
Enterprise-grade natural language to SQL generation using LLMs: Balancing accuracy, latency, and scale
APRIL 24, 2025
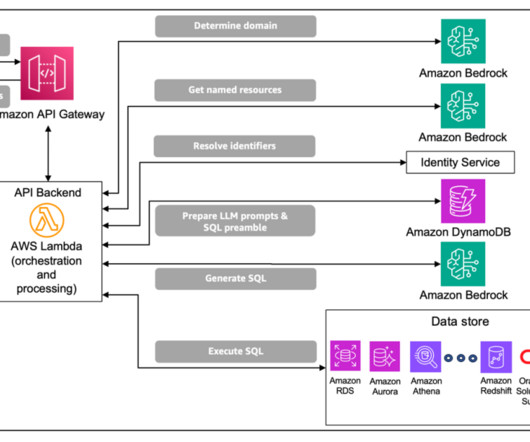
For enterprise data, a major difficulty stems from the common case of database tables having embedded structures that require specific knowledge or highly nuanced processing (for example, an embedded XML formatted string). As a result, NL2SQL solutions for enterprise data are often incomplete or inaccurate.

















Let's personalize your content