
LLM continuous self-instruct fine-tuning framework powered by a compound AI system on Amazon SageMaker
AWS Machine Learning Blog
FEBRUARY 21, 2025
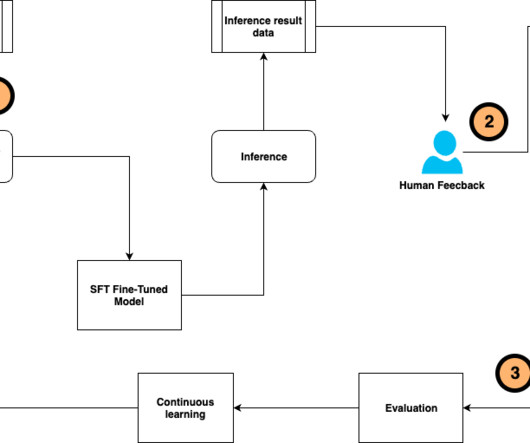
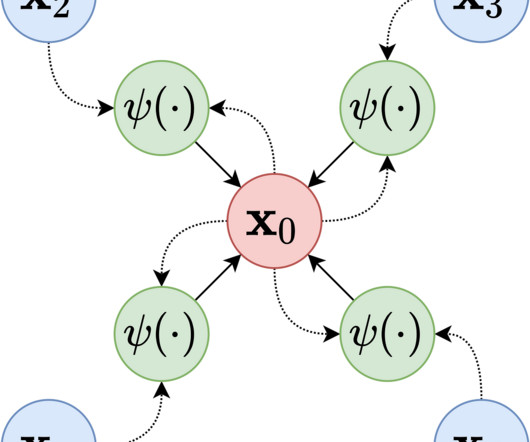
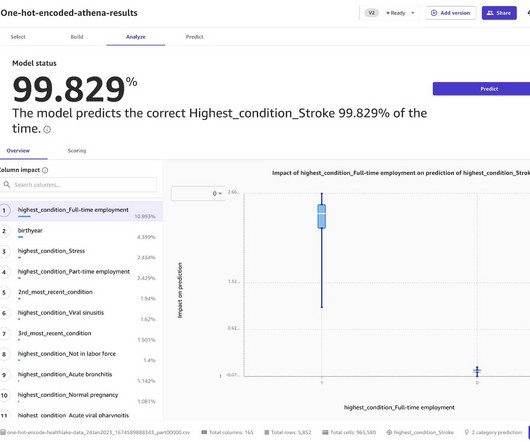
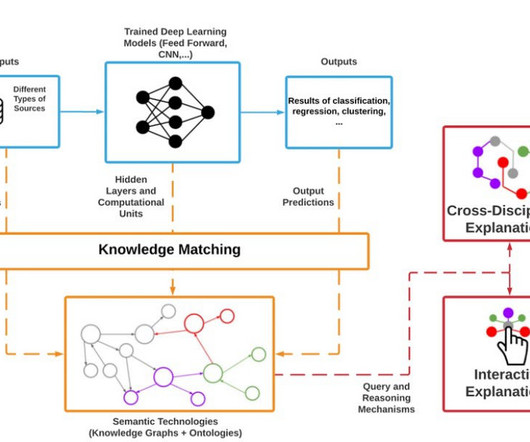
We use DSPy (Declarative Self-improving Python) to demonstrate the workflow of Retrieval Augmented Generation (RAG) optimization, LLM fine-tuning and evaluation, and human preference alignment for performance improvement. Evaluation and continuous learning The model customization and preference alignment is not a one-time effort.






















Let's personalize your content