This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dplyr simplifies this process significantly, enhancing dataquality and facilitating thorough analysis. Benefits of using dplyr Using dplyr offers several advantages: Saves time in data preparation tasks. Improves comprehension through a user-friendly syntax. Facilitates easier conversion of datasets for visualization.
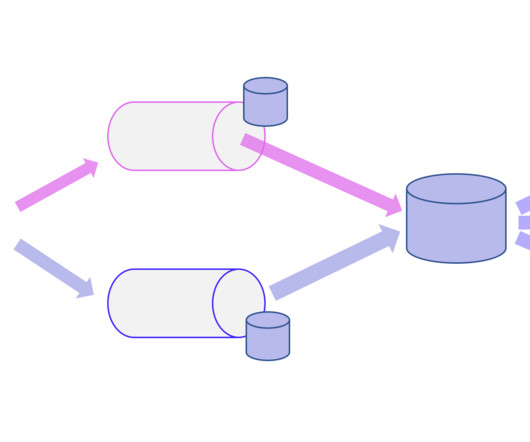
The batch views within the Lambda architecture allow for the application of more complex or resource-intensive rules, resulting in superior dataquality and reduced bias over time. On the other hand, the real-time views provide immediate access to the most current data.
Dataquality: ensuring the data received in production is processed in the same way as the training data. We can also identify some important differences with AI projects in the context of MLOps: the need to version code, data, and models; tracking model experiments; monitoring models in production. Russell and P.
RNNs and LSTMs came later in 2014. This focus on understanding context is similar to the way YData Fabric, a dataquality platform designed for data […] There is very little contention that large language models have evolved very rapidly since 2018.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
Founded in 2014 by three leading cloud engineers, phData focuses on solving real-world data engineering, operations, and advanced analytics problems with the best cloud platforms and products. This search for efficiency led us to create the Data Source tool, which is part of the phData Toolkit.
DataOps is a set of technologies, processes, and best practices that combine a process-focused perspective on data and the automation methods of the Agile software development methodology to improve speed and quality and foster a collaborative culture of rapid, continuous improvement in the data analytics field.
Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care. Data Management – Efficient data management is crucial for AI/ML platforms. This is a joint blog with AWS and Philips.
Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. BLEU on the WMT 2014 English- to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. Our model achieves 28.4
GoogLeNet: is a highly optimized CNN architecture developed by researchers at Google in 2014. Data Preprocessing : The dataquality used to train a CNN is critical to its performance. It is critical to preprocess the data before it is fed into the network.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content