This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
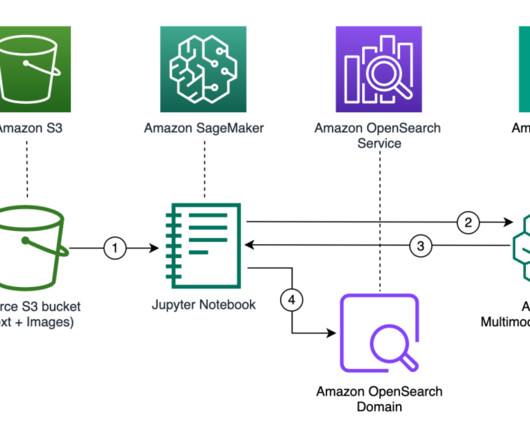
OpenSearch Service is the AWS recommended vector database for Amazon Bedrock. OpenSearch is a distributed open-source search and analytics engine composed of a search engine and vector database. To learn more, see Improve search results for AI using Amazon OpenSearch Service as a vector database with Amazon Bedrock.
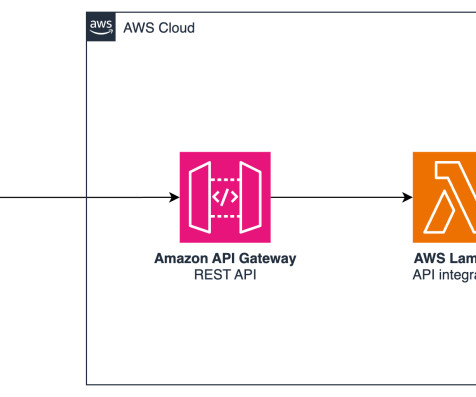
To set up the integration, follow these steps: Create an AWS Lambda function with Python runtime and below code to be the backend for the API. Make sure that we have Powertools for AWS Lambda (Python) available in our runtime, for example, by attaching a Lambda layer to our function.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
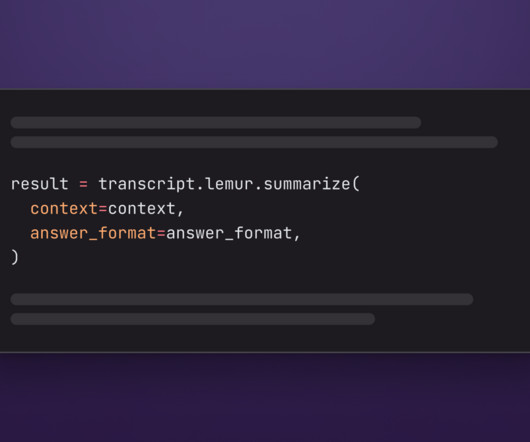
In this tutorial, we will learn how to use LLMs to automatically summarize audio and video files with Python. We’ll use the AssemblyAI Python SDK in this tutorial. python -m venv transcriber # you may have to use `python3` Activate the virtual environment with the activation script on macOS or Linux: source.
Apache Spark and its Python API, PySpark , empower users to process massive datasets effortlessly by using distributed computing across multiple nodes. This solution enables you to process massive volumes of textual data, generate relevant embeddings , and store them in a powerful vector database for seamless retrieval and generation.
Improving Operations and Infrastructure Taipy The inspiration for this open-source software for Python developers was the frustration felt by those who were trying, and struggling, to bring AI algorithms to end-users. Blueprint’s tools and services allow organizations to quickly obtain decision-guiding insights from your data.
Now that signals are being generated, we can set up IoT Core to read the MQTT topics and direct the payloads to the Timestream database. Choose Create Timestream database. Select Standard database. Name the database sampleDB and choose Create database. For Runtime , choose Python 3.9. Choose Create rule.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select.
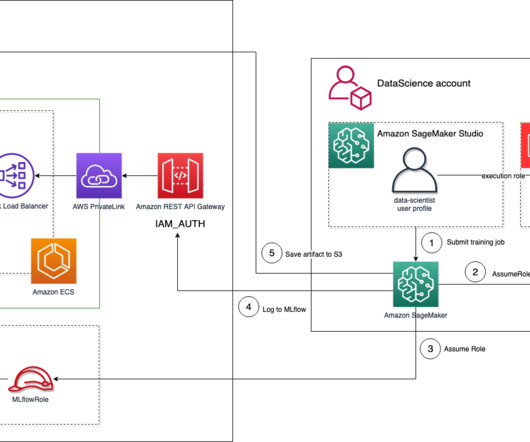
MLflow has integrated the feature that enables request signing using AWS credentials into the upstream repository for its Python SDK, improving the integration with SageMaker. The changes to the MLflow Python SDK are available for everyone since MLflow version 1.30.0. mlflow/runs/search/", "arn:aws:execute-api: : : / /POST/api/2.0/mlflow/experiments/search",
Netezza Performance Server (NPS) has recently added the ability to access Parquet files by defining a Parquet file as an external table in the database. All SQL and Python code is executed against the NPS database using Jupyter notebooks, which capture query output and graphing of results during the analysis phase of the demonstration.
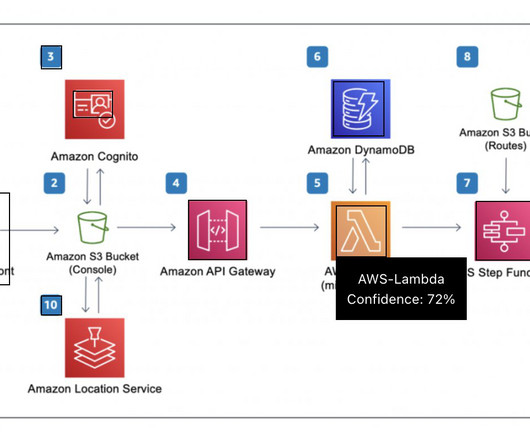
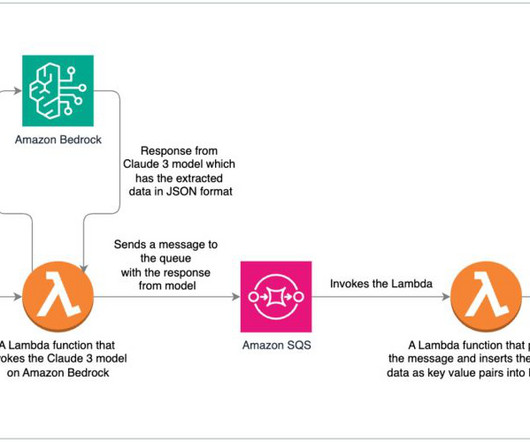
The orchestrating Lambda function calls the Amazon Bedrock LLM endpoint to generate a final order summary including the order total from the customer database system (for example, Amazon DynamoDB ). You can load the data to the DynamoDB table using Python code in a SageMaker notebook. Copy your prompt files to the python folder.
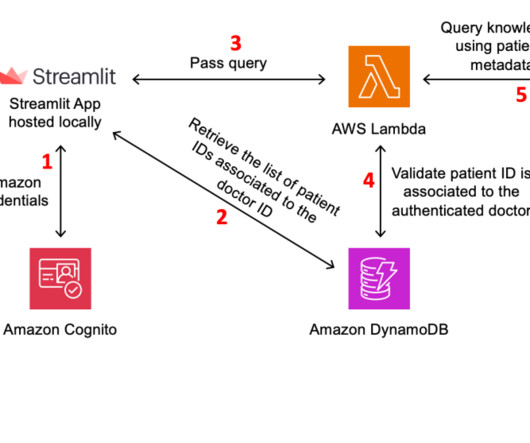
After the doctor has successfully signed in, the application retrieves the list of patients associated with the doctor’s ID from the Amazon DynamoDB database. Before querying the knowledge base, the Lambda function retrieves data from the DynamoDB database, which stores doctor-patient associations.
YouTube Introduction to Natural Language Processing (NLP) NLP 2012 Dan Jurafsky and Chris Manning (1.1) Learning LLMs (Foundational Models) Base Knowledge / Concepts: What is AI, ML and NLP Introduction to ML and AI — MFML Part 1 — YouTube What is NLP (Natural Language Processing)? — YouTube
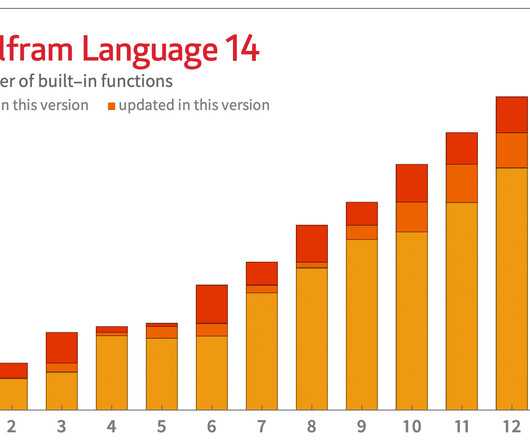
And in a similar vein, we can expect LLMs to be useful in making connections to external databases, functions, etc. And in 2012 we introduced Quantity to represent quantities with units in the Wolfram Language. There’s one setup for interpreted languages like Python. Let’s start with Python. But in Version 14.0
RedShift , the data source and can be backend-connected to other sources and databases or replaced by any other type of data source like S3 buckets or DynamoDB. Imagine, as a use case, you need to access different databases by writing a complex query and then writing a summary to another table. sm_client = boto3.client( split( "?"
After modeling, detected services of each architecture diagram image and its metadata, like URL origin and image title, are indexed for future search purposes and stored in Amazon DynamoDB , a fully managed, serverless, key-value NoSQL database designed to run high-performance applications. join(", "), }; }).catch((error)
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. in 2012 is now widely referred to as ML’s “Cambrian Explosion.” GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5% Work by Hinton et al.
Circuit Painter is implemented as a simplified Python-based language, using vector graphics-inspired techniques such as matrix transformation to simplify board generation. The OpenEPT database infrastructure will facilitate collaboration between engineers and researchers by promoting data exchange.
spaCy is a new library for text processing in Python and Cython. NLTK 4ms 443ms n/a 20x 443x n/a Set up : 100,000 plain-text documents were streamed from an SQLite3 database, and processed with an NLP library, to one of three levels of detail — tokenization, tagging, or parsing. ZPar 1ms 8ms 850ms 5x 8x 44.7x
When you run the crawler, it creates metadata tables that are added to a database you specify or the default database. The following sections describe the implementation details of each approach using the Python programming language. This approach is ideal for AWS Glue databases with a small number of tables.
Snowflake provides many mechanisms to access their service including: Browser SnowSQL Python Connector JDBC/ODBC Driver.NET Snowflake has some limitations with SAML. The OAuth framework was initially created and supported by Twitter, Google, and a few other companies in 2010 and subsequently underwent a substantial revision to OAuth 2.0
For instance, problems like “write a Python function that takes a list of names, splits them by first and last name, and sorts by last name.” Similarly, it taught me that “Background scripts are ideal for handling long-term or ongoing tasks, managing state, maintaining databases, and communicating with remote servers.
We demonstrate how to extract data from a scanned document and insert it into a database. Amazon DynamoDB is a fully managed, serverless, NoSQL database service. Create a Lambda function to invoke the Amazon Bedrock model On the Lambda console, create a function (for example, invoke_bedrock_claude3 ), choose Python 3.12
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets. The LLM response is passed back to the agent.
The data might exist in various formats such as files, database records, or long-form text. An AI technique called embedding language models converts this external data into numerical representations and stores it in a vector database. Learn more in Amazon OpenSearch Service’s vector database capabilities explained.
It helps ingest, structure, and retrieve information from databases, APIs, PDFs, and more, enabling the agent and RAG for AI applications. In this post, we demonstrate an example of building an agentic RAG application using the LlamaIndex framework. LlamaIndex is a framework that connects FMs with external data sources. Check the utils.py
I've built the archival and database software on Lucee & MySQL to store images and automate, and I use OpenAI to analyze images and extra meta data. Uses lldb's Python scripting extensions to register commands, and handle memory access. Happy to chat if you're into VMs, query engines, or DSLs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content