This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
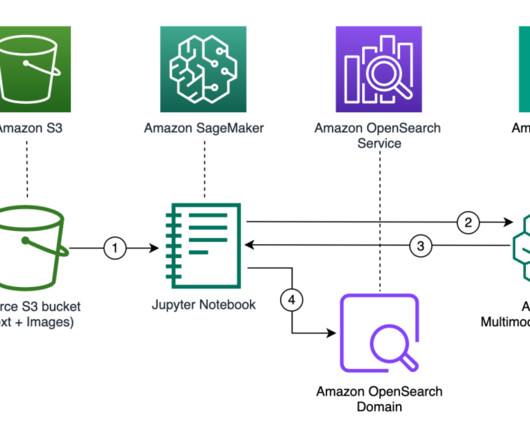
It works by analyzing the visual content to find similar images in its database. Exclusive to Amazon Bedrock, the Amazon Titan family of models incorporates 25 years of experience innovating with AI and machinelearning at Amazon. To do so, you can use a vector database. Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME)
This fragmentation can complicate efforts by organizations to consolidate and analyze data for their machinelearning (ML) initiatives. You should be able to run live queries against the BigQuery database. In the modern, cloud-centric business landscape, data is often scattered across numerous clouds and on-site systems.
OpenSearch Service is the AWS recommended vector database for Amazon Bedrock. OpenSearch is a distributed open-source search and analytics engine composed of a search engine and vector database. To learn more, see Improve search results for AI using Amazon OpenSearch Service as a vector database with Amazon Bedrock.
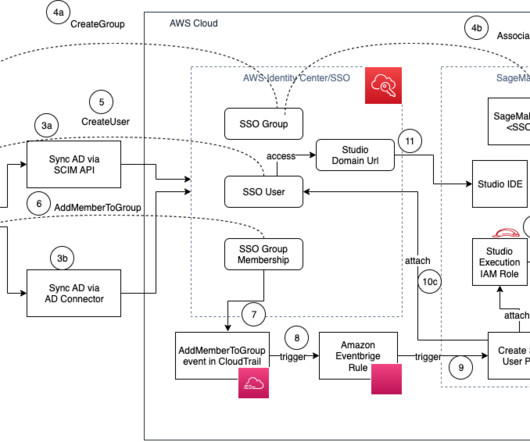
Managing access control in enterprise machinelearning (ML) environments presents significant challenges, particularly when multiple teams share Amazon SageMaker AI resources within a single Amazon Web Services (AWS) account.
As demonstrated in the following example, the system translates natural language queries about vehicles into SQL, returning structured information from the database. The database connection is configured through a SQL Alchemy engine. Daytime conditions, clear visibility. No suspicious behavior or safety concerns observed.
Adams’s recognitions include the 2012 Warren Alpert Foundation Prize for his role in the discovery and development of bortezomib, an anti-cancer drug; the 2012 C. The AI component of this is that the more images you show the computer, the more it learns, the better and more accurately it describes the abnormality.
It was built using a combination of in-house and external cloud services on Microsoft Azure for large language models (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. Opportunities for innovation CreditAI by Octus version 1.x x uses Retrieval Augmented Generation (RAG).
This involved creating a pipeline for data ingestion, preprocessing, metadata extraction, and indexing in a vector database. Similarity search and retrieval – The system retrieves the most relevant chunks in the vector database based on similarity scores to the query.
When you run the crawler, it creates metadata tables that are added to a database you specify or the default database. Approach 1: In-context learning In this approach, you use an LLM to generate the metadata descriptions. This approach is ideal for AWS Glue databases with a small number of tables. Build the prompt.
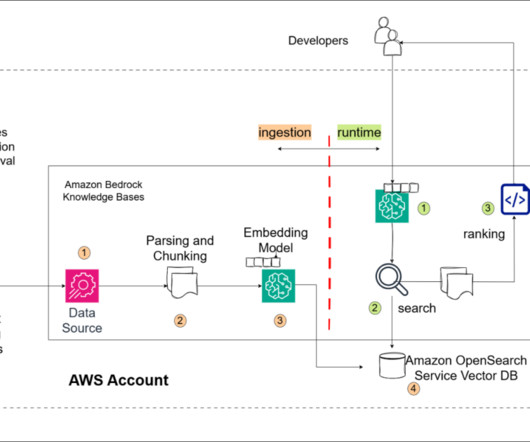
As knowledge bases grow and require more granular embeddings, many vector databases that rely on high-performance storage such as SSDs or in-memory solutions become prohibitively expensive. In this post, we demonstrate how to integrate Amazon S3 Vectors with Amazon Bedrock Knowledge Bases for RAG applications.
In 2012, researchers proved that no deterministic algorithm can improve on log 2 n. 35 th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems (PODS) , pages 289-302, June 2016. 44 th annual ACM Symposium on Theory of Computing (STOC) , pages 1185-1198, 2012. 7 Previous Issue June 2025 , Vol. Bulánek, J.
Under DATABASES , select glue_db_ or the customer glue database name you provided during project creation. You will see a new database dev@ in the managed Amazon Redshift Serverless workgroup. Select Redshift (Lakehouse) from CONNECTIONS , dev@ from DATABASES and public from SCHEMAS Run the following SQL in order.
AWS (Amazon Web Services) is a comprehensive cloud computing platform offering a wide range of services like computing power, database storage, content delivery, and more.n2. Make sure that we have Powertools for AWS Lambda (Python) available in our runtime, for example, by attaching a Lambda layer to our function.
The Open Energy Profiler Toolset (OpenEPT) ecosystem will provide diverse hardware solutions, a user-friendly interface encapsulated in a GUI application, and a collaborative database infrastructure that brings together engineers and researchers to drive innovations in the field of battery-powered technologies.
reply phelddagrif 21 minutes ago | prev | next [–] https://www.quarterbackranking.com It's a DIY confirmation bias machine for ranking NFL quarterbacks by a variety of stats. So I might be putting it into a database to hopefully aggregate multiples of the 10k results if they're not always the same 10k. [0]:
Feature Platforms — A New Paradigm in MachineLearning Operations (MLOps) Operationalizing MachineLearning is Still Hard OpenAI introduced ChatGPT. The growth of the AI and MachineLearning (ML) industry has continued to grow at a rapid rate over recent years.
revolution has shown the value and importance of machinelearning (ML) across verticals and environments, with more impact on manufacturing than possibly any other application. Now that signals are being generated, we can set up IoT Core to read the MQTT topics and direct the payloads to the Timestream database. Choose Add.
When building such generative AI applications using FMs or base models, customers want to generate a response without going over the public internet or based on their proprietary data that may reside in their enterprise databases. You’re redirected to the IAM console. Currently, the VPC endpoint policy is set to Allow.
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machinelearning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. elasticmapreduce", "arn:aws:s3:::*.elasticmapreduce/*" elasticmapreduce", "arn:aws:s3:::*.elasticmapreduce/*"
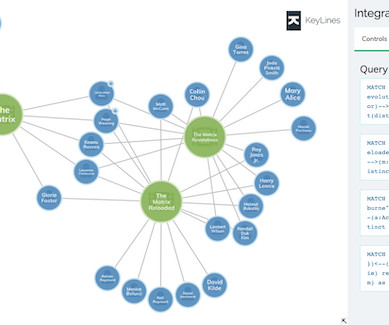
That’s why our data visualization SDKs are database agnostic: so you’re free to choose the right stack for your application. There have been a lot of new entrants and innovations in the graph database category, with some vendors slowly dipping below the radar, or always staying on the periphery. can handle many graph-type problems.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machinelearning (ML) models. For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. or later image versions. or later image versions.
Cloudera For Cloudera, it’s all about machinelearning optimization. Their CDP machinelearning allows teams to collaborate across the full data life cycle with scalable computing resources, tools, and more.
With cloud computing, as compute power and data became more available, machinelearning (ML) is now making an impact across every industry and is a core part of every business and industry. The SourceIdentity attribute is used to tie the identity of the original SageMaker Studio user to the Amazon Redshift database user.
Facies classification using AI and machinelearning (ML) has become an increasingly popular area of investigation for many oil majors. An existing database within Snowflake. Download the training_data.csv and validation_data_nofacies.csv files to your local machine. Do the same for the validation database.
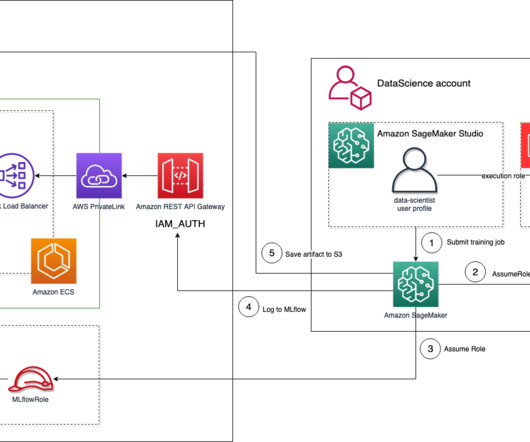
With Amazon SageMaker , you can manage the whole end-to-end machinelearning (ML) lifecycle. For this task, we build on top the following GitHub repo: Manage your machinelearning lifecycle with MLflow and Amazon SageMaker. mlflow/runs/search/", "arn:aws:execute-api: : : / /POST/api/2.0/mlflow/experiments/search",
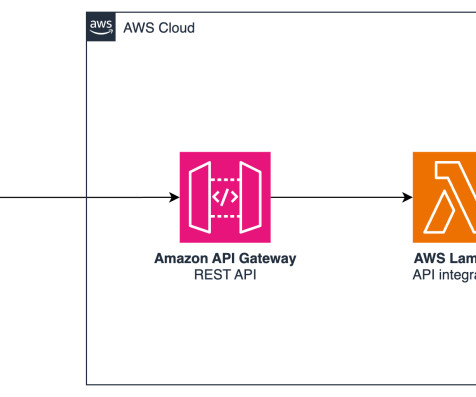
IAM role that is used by the bot at runtime BotRuntimeRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: - lexv2.amazonaws.com For more information, refer to Enabling custom logic with AWS Lambda functions.
Many practitioners are extending these Redshift datasets at scale for machinelearning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
Cortex ML is Snowflake’s newest feature, added to enhance the ease of use and low-code functionality of your business’s machinelearning needs. What is Cortex ML, and Why Does it Matter? The newest ML functions are Forecasting, Anomaly Detection, and Contribution Explorer.
Amazon SageMaker Studio is a web-based integrated development environment (IDE) for machinelearning (ML) that lets you build, train, debug, deploy, and monitor your ML models. She is passionate about making machinelearning accessible to everyone.
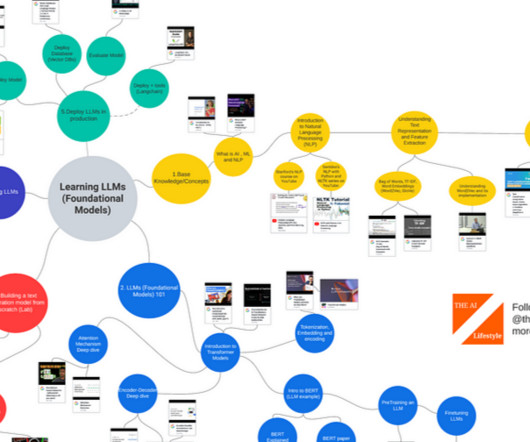
Learning LLMs (Foundational Models) Base Knowledge / Concepts: What is AI, ML and NLP Introduction to ML and AI — MFML Part 1 — YouTube What is NLP (Natural Language Processing)? — YouTube YouTube Introduction to Natural Language Processing (NLP) NLP 2012 Dan Jurafsky and Chris Manning (1.1)
They can help to ensure that machinelearning models are developed and deployed efficiently and that they remain reliable and accurate over time. AWS offers a three-layered machinelearning stack to choose from based on your skill set and team’s requirements for implementing workloads to execute machinelearning tasks.
In 2012, records show there were 447 data breaches in the United States. EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machinelearning to responsible AI.
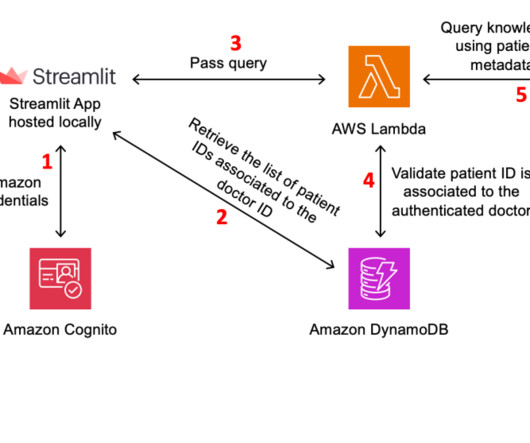
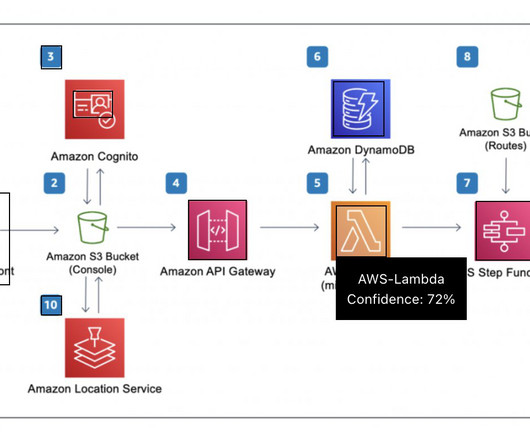
After the doctor has successfully signed in, the application retrieves the list of patients associated with the doctor’s ID from the Amazon DynamoDB database. Before querying the knowledge base, the Lambda function retrieves data from the DynamoDB database, which stores doctor-patient associations.
With the application of natural language processing (NLP) and machinelearning algorithms, AI systems can understand and translate spoken language into written notes. Utilizing its CognitiveML engine, Iodine Software implements advanced machinelearning across various use-case scenarios within a database of patient admissions.
Without careful architectural planning, RAG implementations can lead to unnecessary expenses through duplicate data storage, excessive vector database operations, and inefficient data transfer patterns. Aamna Najmi is a Senior GenAI and Data Specialist in the Worldwide team at Amazon Web Services (AWS).
The orchestrating Lambda function calls the Amazon Bedrock LLM endpoint to generate a final order summary including the order total from the customer database system (for example, Amazon DynamoDB ). A strategic leader with expertise in cloud architecture, generative AI, machinelearning, and data analytics.
Since DataRobot was founded in 2012, we’ve been committed to democratizing access to the power of AI. DataRobot AI Cloud brings together any type of data from any source to give our customers a holistic view that drives their business: critical information in databases, data clouds, cloud storage systems, enterprise apps, and more.
In this post, we discuss a machinelearning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. She is also passionate about the field of machinelearning. With the internet, searching and obtaining an image has never been easier. join(", "), }; }).catch((error)
Around 2012 to 2014, developers proposed updating these modules, but were told to use third party libraries instead. Python for machinelearning and data science** In the early 1990s, scientists used Fortran and C++ libraries to solve mathematical problems. However, over time these modules became outdated.
December 2012: Alation forms and goes to work creating the first enterprise data catalog. October 2020: Forrester Research names Alation a Leader in The Forrester Wave: MachineLearning Data Catalogs, Q4, 2020. Here’s a timeline view of what the market has said about Alation since our founding: Timeline: 10 Years of Alation.
These activities cover disparate fields such as basic data processing, analytics, and machinelearning (ML). in 2012 is now widely referred to as ML’s “Cambrian Explosion.” Machinelearning Generative AI is the most topical ML application at this point in time. Work by Hinton et al.
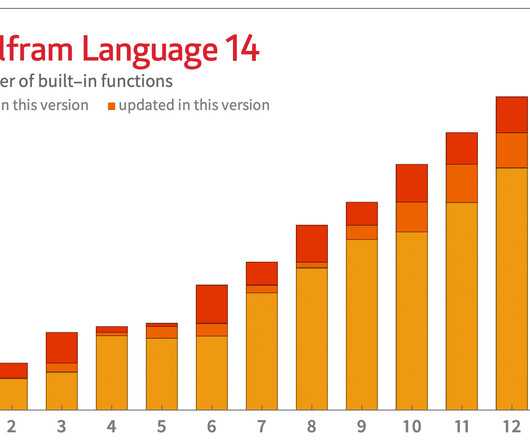
The LLMs Have Landed The machinelearning superfunctions Classify and Predict first appeared in Wolfram Language in 2014 ( Version 10 ). And in a similar vein, we can expect LLMs to be useful in making connections to external databases, functions, etc. But in Version 14.0 and if it’s right, can be used henceforth.
Here are a few reasons why an agent needs tools: Access to external resources: Tools allow an agent to access and retrieve information from external sources, such as databases, APIs, or web scraping. This includes cleaning and transforming data, performing calculations, or applying machinelearning algorithms.
To do great NLP, you have to know a little about linguistics, a lot about machinelearning, and almost everything about the latest research. Hardware : Intel i7-3770 (2012) Efficiency is a major concern for NLP applications. I spent a long time on spaCy’s initial design before this announcement. ZPar 1ms 8ms 850ms 5x 8x 44.7x
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content