This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Next, the SageMaker Ground Truth Plus team sets up data labeling workflows, which changes the batch status to In progress. Annotators label the data, and you complete your dataquality check by accepting or rejecting the labeled data. Rejected objects go back to annotators to re-label.
Job title history of data scientist The title “data scientist” gained prominence in 2008 when companies like Facebook and LinkedIn utilized it in corporate job descriptions. Dataquality concerns: Inconsistencies and inaccuracies in data can lead to faulty conclusions.
Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem. Tools like Git and Jenkins are not suited for managing data. This is where a feature platform comes in handy.
Making Data Observable Bigeye The quality of the data powering your machine learning algorithms should not be a mystery. Bigeye’s data observability platform helps data science teams “measure, improve, and communicate dataquality at any scale.”
These optimizations are automatically applied, allowing you to focus on dataquality and the configurable parameters while benefiting from our research-backed tuning strategies. Model size selection and performance comparison Choosing between Meta Llama 3.2 11B and Meta Llama 3.2
Data Integrity checks and best practices support data management as both strategic and tactical processes that enable companies to improve compliance, reduce costs, transform their customer relationships, and stay on the leading edge of innovation. This post examines the practical implications of poor data integrity.
The trouble began in 2012 when a thief stole a laptop containing 30,000 patient records from an employee’s home. That same year, as well as in 2013, there were two separate instances of more data loss via misplaced USB drives. If you trust the data, it’s easier to use confidently to make business decisions.
December 2012: Alation forms and goes to work creating the first enterprise data catalog. Later, in its inaugural report on data catalogs, Forrester Research recognizes that “Alation started the MLDC trend.”. May 2016: Alation named a Gartner Cool Vendor in their Data Integration and DataQuality, 2016 report.
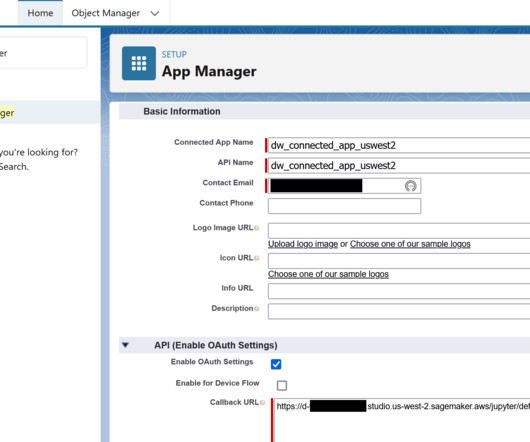
In the data flow view, you can now see a new node added to the visual graph. For more information on how you can use SageMaker Data Wrangler to create DataQuality and Insights Reports, refer to Get Insights On Data and DataQuality. SageMaker Data Wrangler offers over 300 built-in transformations.
Generally, as the size of the high-quality training data increases, you can expect to achieve better performance from the fine-tuned model. However, it’s essential to maintain a focus on dataquality, because a large but low-quality dataset may not yield the desired improvements in the fine-tuned model performance.
Hockey Stick Growth in the Demand for Data Experts It is one of the most reforming changes coming in the industry. In addition to the conventional career choices, Data Science proficiency is gaining popularity. Since 2012, there has been a 650% rise in the demand for skilled and qualified data professionals.
AlexNet is a more profound and complex CNN architecture developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton in 2012. Data Preprocessing : The dataquality used to train a CNN is critical to its performance. It is critical to preprocess the data before it is fed into the network.
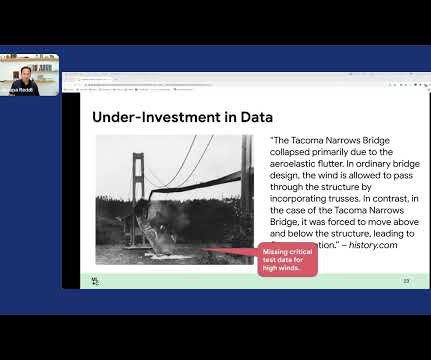
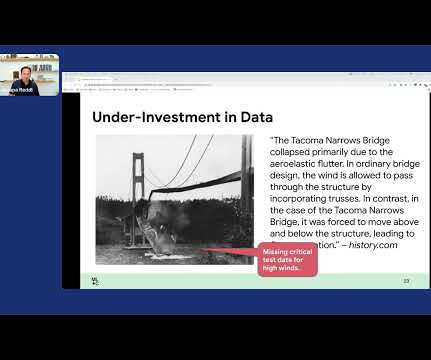
But in the context of data, we have yet to have a very systematic way of improving the datasets that we have in ML. This plot, which is effectively looking from 2012 to 2021, is showing that we have invested a huge amount of effort in improving the models in the ML context. First is how good is your training data?
But in the context of data, we have yet to have a very systematic way of improving the datasets that we have in ML. This plot, which is effectively looking from 2012 to 2021, is showing that we have invested a huge amount of effort in improving the models in the ML context. First is how good is your training data?
Amazon SageMaker Catalog serves as a central repository hub to store both technical and business catalog information of the data product. To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the dataquality metrics and data lineage events to track and drive transparency in data pipelines.
The training set acts as a crucible for model training, the validation set assists in gauging the model’s performance, and the test set allows for performance appraisal on unfamiliar data. Three synchronized and calibrated Kinect V2 cameras captured the dataset, ensuring consistent dataquality.
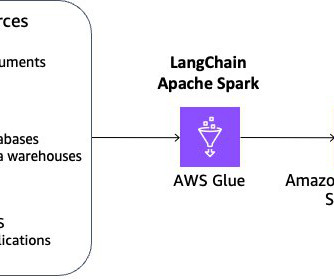
The benefits of this solution are: You can flexibly achieve data cleaning, sanitizing, and dataquality management in addition to chunking and embedding. You can build and manage an incremental data pipeline to update embeddings on Vectorstore at scale. You can choose a wide variety of embedding models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content