This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Best practices for datapreparation The quality and structure of your training data fundamentally determine the success of fine-tuning. Our experiments revealed several critical insights for preparing effective multimodal datasets: Data structure You should use a single image per example rather than multiple images.
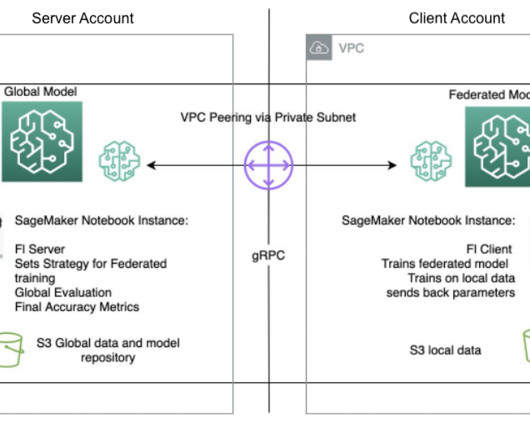
Both the training and validation data are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket for model training in the client account, and the testing dataset is used in the server account for testing purposes only. Details of the datapreparation code are in the following notebook.
Option C: Use SageMaker Data Wrangler SageMaker Data Wrangler allows you to import data from various data sources including Amazon Redshift for a low-code/no-code way to prepare, transform, and featurize your data. She has extensive experience in machine learning with a PhD degree in ComputerScience.
Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics. in 2012 is now widely referred to as ML’s “Cambrian Explosion.” The union of advances in hardware and ML has led us to the current day.
However, another motivation was a personal reflection on a field that did not yet exist a little over a decade ago when I first began my advanced studies in computerscience. As datascience work grew in complexity, data scientists became less generalized and more specialized, often engaged in specific aspects of datascience work.
However, another motivation was a personal reflection on a field that did not yet exist a little over a decade ago when I first began my advanced studies in computerscience. As datascience work grew in complexity, data scientists became less generalized and more specialized, often engaged in specific aspects of datascience work.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content