This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This minimizes the complexity and overhead associated with moving data between cloud environments, enabling organizations to access and utilize their disparate data assets for ML projects. You can use SageMaker Canvas to build the initial datapreparation routine and generate accurate predictions without writing code.
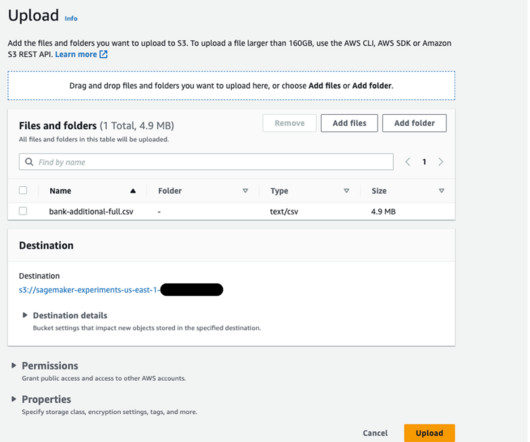
Prerequisites To use this feature, make sure that you have satisfied the following requirements: An active AWS account. model customization is available in the US West (Oregon) AWS Region. The required training dataset (and optional validation dataset) prepared and stored in Amazon Simple Storage Service (Amazon S3).
This simplifies access to generative artificial intelligence (AI) capabilities to business analysts and data scientists without the need for technical knowledge or having to write code, thereby accelerating productivity. Provide the AWS Region, account, and model IDs appropriate for your environment.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
We’re excited to announce Amazon SageMaker Data Wrangler support for Amazon S3 Access Points. In this post, we walk you through importing data from, and exporting data to, an S3 access point in SageMaker Data Wrangler. Configure your AWS Identity and Access Management (IAM) role with the necessary policies.
Prerequisites To try out this solution using SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all of your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker. of persons present’ for the sustainability committee meeting held on 5th April, 2012?
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
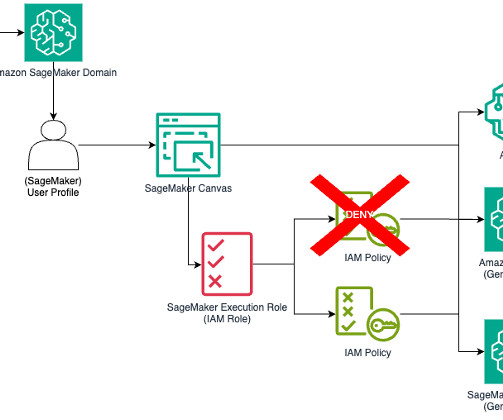
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. An execution role update may be required to bring in data browsing and the SQL run feature. You need to create AWS Glue connections with specific connection types.
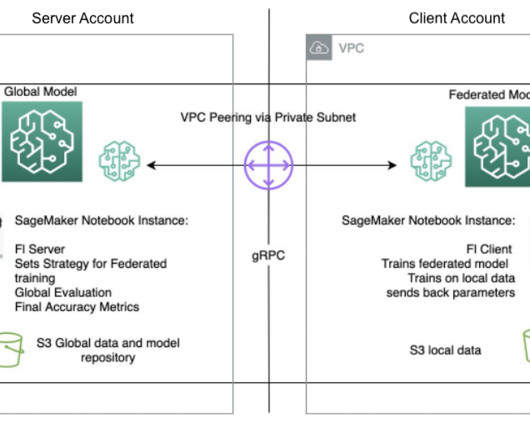
With SageMaker, data scientists and developers can quickly build and train ML models, and then deploy them into a production-ready hosted environment. In this post, we demonstrate how to use the managed ML platform to provide a notebook experience environment and perform federated learning across AWS accounts, using SageMaker training jobs.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics. Work by Hinton et al.
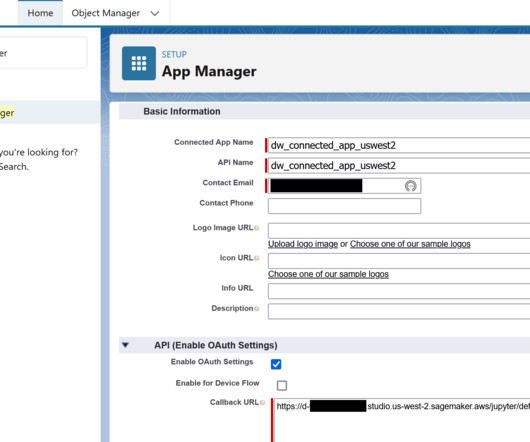
The following steps give an overview of how to use the new capabilities launched in SageMaker for Salesforce to enable the overall integration: Set up the Amazon SageMaker Studio domain and OAuth between Salesforce and the AWS account s. Select Other type of secret. Save the secret and note the ARN of the secret.
Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. You can manage app images via the SageMaker console, the AWS SDK for Python (Boto3), and the AWS Command Line Interface (AWS CLI). Environments without internet access.
Since DataRobot was founded in 2012, we’ve been committed to democratizing access to the power of AI. We’re building a platform for all users: data scientists, analytics experts, business users, and IT. Let’s dive into each of these areas and talk about how we’re delivering the DataRobot AI Cloud Platform with our 7.2
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of data silos or the need to copy data between systems. Environments are the actual data infrastructure behind a project.
Starting from AlexNet with 8 layers in 2012 to ResNet with 152 layers in 2015 – the deep neural networks have become deeper with time. It requires significant effort in terms of datapreparation, exploration, processing, and experimentation, which involves trying out algorithms and hyperparameters.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content