This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. To do so, you can use a vector database. Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME)
For example, for simple motion detection, we use a simple pixel difference, but you can refine the motion detection functionality as needed, or follow the format to implement other detection algorithms, such as object detection or scene segmentation. The database connection is configured through a SQL Alchemy engine.
Sign In Sign Up Communications of the ACM About Us Frequently Asked Questions Contact Us Follow Us CACM on Twitter CACM on Reddit CACM on LinkedIn News Architecture and Hardware An Algorithm for a Better Bookshelf Managing the strategic positioning of empty spaces. However, no one could beat the log 2 n cost of the 1981 algorithm.
Adams’s recognitions include the 2012 Warren Alpert Foundation Prize for his role in the discovery and development of bortezomib, an anti-cancer drug; the 2012 C. Sam Ransbotham: … ImageNet is a database of 14-plus million images that … started with a contest about a decade ago for image recognition.
The Open Energy Profiler Toolset (OpenEPT) ecosystem will provide diverse hardware solutions, a user-friendly interface encapsulated in a GUI application, and a collaborative database infrastructure that brings together engineers and researchers to drive innovations in the field of battery-powered technologies.
From a dev perspective this area has a ton of super interesting algorithmic / math / data structure applications, and computational geometry has always been special to me. I've built the archival and database software on Lucee & MySQL to store images and automate, and I use OpenAI to analyze images and extra meta data.
Improving Operations and Infrastructure Taipy The inspiration for this open-source software for Python developers was the frustration felt by those who were trying, and struggling, to bring AI algorithms to end-users. Making Data Observable Bigeye The quality of the data powering your machine learning algorithms should not be a mystery.
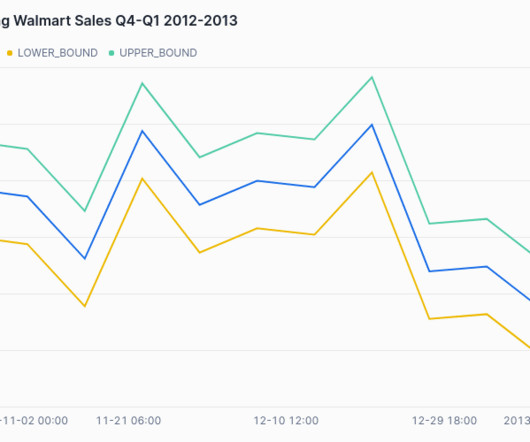
The forecasting algorithm uses gradient boosting to model data and the rolling average of historical data to help predict trends. This low-code solution lets you use your existing Snowflake data and easily create a visualization to predict the future of your sales, taking into account unlimited data points.
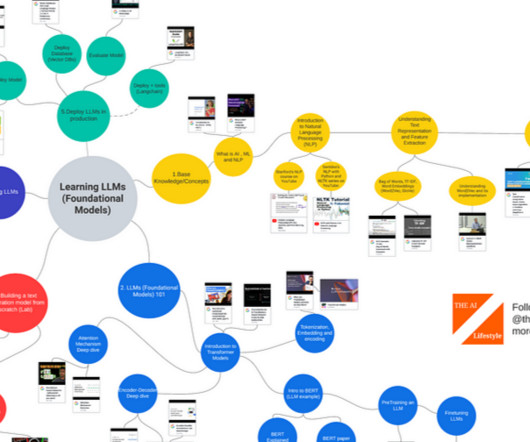
YouTube Introduction to Natural Language Processing (NLP) NLP 2012 Dan Jurafsky and Chris Manning (1.1) Learning LLMs (Foundational Models) Base Knowledge / Concepts: What is AI, ML and NLP Introduction to ML and AI — MFML Part 1 — YouTube What is NLP (Natural Language Processing)? — YouTube
**Improving CPython's performance** Guido initially coded CPython simply and efficiently, but over time more optimized algorithms were developed to improve performance. The example of prime number checking illustrates the time-space tradeoff in algorithms. **The However, over time these modules became outdated.
in 2012 is now widely referred to as ML’s “Cambrian Explosion.” This is accomplished by breaking the problem into independent parts so that each processing element can complete its part of the workload algorithm simultaneously. In FSI, non-time series workloads are also underpinned by algorithms that can be parallelized.
Sometimes it’s a story of creating a superalgorithm that encapsulates decades of algorithmic development. And in a similar vein, we can expect LLMs to be useful in making connections to external databases, functions, etc. And in 2012 we introduced Quantity to represent quantities with units in the Wolfram Language.
With the application of natural language processing (NLP) and machine learning algorithms, AI systems can understand and translate spoken language into written notes. Utilizing its CognitiveML engine, Iodine Software implements advanced machine learning across various use-case scenarios within a database of patient admissions.
By uploading a small set of training images, Amazon Rekognition automatically loads and inspects the training data, selects the right ML algorithms, trains a model, and provides model performance metrics. join(", "), }; }).catch((error)
Here are a few reasons why an agent needs tools: Access to external resources: Tools allow an agent to access and retrieve information from external sources, such as databases, APIs, or web scraping. This includes cleaning and transforming data, performing calculations, or applying machine learning algorithms.
Advance algorithms and analytic approaches for early prediction of AD/ADRD, with an emphasis on explainability of predictions. Top solvers from Phase 2 demonstrate algorithmic approaches on diverse datasets and share their results at an innovation event. Phase 2 [Build IT!] Phase 3 [Put IT All Together!]
Advance algorithms and analytic approaches for early prediction of AD/ADRD, with an emphasis on explainability of predictions. Top solvers from Phase 2 demonstrate algorithmic approaches on diverse datasets and share their results at an innovation event. changes between 2003 and 2012). Phase 2 [Build IT!]
Business Value As per FAERS database , the number of reported AEs has grown 2.5x in 10 years, from 2012 to 2022. In a nod to the growing usage of Machine learning in life sciences, FDA has now cleared more than 500 medical algorithms that are commercially available in the United States. More than half of algorithms on the U.S.
Algorithms are important and require expert knowledge to develop and refine, but they would be useless without data. These datasets, essentially large collections of related information, act as the training field for machine learning algorithms. This involves feeding the images and their corresponding labels into an algorithm (e.g.,
Back in 2016 I was trying to explain to software engineers how to think about machine learning models from a software design perspective; I told them that they should think of a database. Photo by Tobias Fischer on Unsplash What are databases used for? How are neural networks like databases?
Amazon Bedrock Knowledge Bases automates critical processes such as data ingestion, chunking, embedding generation, and vector storage, and the application of advanced indexing algorithms and retrieval techniques, empowering users to develop intelligent applications with minimal effort. Replace YOUR_ACCOUNT_ID with your AWS account number.
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets. The LLM response is passed back to the agent.
The data might exist in various formats such as files, database records, or long-form text. An AI technique called embedding language models converts this external data into numerical representations and stores it in a vector database. Learn more in Amazon OpenSearch Service’s vector database capabilities explained.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content