This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Source: Author Introduction Deeplearning, a branch of machine learning inspired by biological neural networks, has become a key technique in artificial intelligence (AI) applications. Deeplearning methods use multi-layer artificial neural networks to extract intricate patterns from large data sets.
The promise and power of AI lead many researchers to gloss over the ways in which things can go wrong when building and operationalizing machine learning models. As a datascientist, one of my passions is to reproduce research papers as a learning exercise. As these examples show, errors in machine learning can be subtle.
This post is co-authored by Anatoly Khomenko, Machine Learning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. Established in 2011, Talent.com aggregates paid job listings from their clients and public job listings, and has created a unified, easily searchable platform.
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for data science, machine learning (ML), and computational science. Given the importance of Jupyter to datascientists and ML developers, AWS is an active sponsor and contributor to Project Jupyter.
These models rely on learning algorithms that are developed and maintained by datascientists. In other words, traditional machine learning models need human intervention to process new information and perform any new task that falls outside their initial training. IBM watsonx.ai Explore watsonx.ai
Businesses are increasingly using machine learning (ML) to make near-real-time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products and services. As a result, some enterprises have spent millions of dollars inventing their own proprietary infrastructure for feature management.
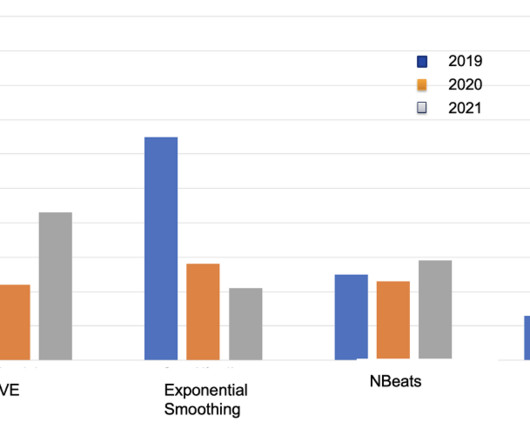
We calculated the WAPE value of a model by splitting the data into test and validation sets. For example, in the 2019 WAPE value, we trained our model using sales data between 2011–2018 and predicted sales values for the next 12 months (2019 sale). He focuses on machine learning, deeplearning and end-to-end ML solutions.
Artificial Intelligence (AI) Integration: AI techniques, including machine learning and deeplearning, will be combined with computer vision to improve the protection and understanding of cultural assets. Preservation of cultural heritage and natural history through game-based learning. Ahmad, M., & Selviandro, N.
It’s widely used in production and research systems for extracting information from text, developing smarter user-facing features, and preprocessing text for deeplearning. In 2011, deeplearning methods were proving successful for NLP, and techniques for pretraining word representations were already in use.
jpg': {'class': 111, 'label': 'Ford Ranger SuperCab 2011'}, '00236.jpg': jpg': {'class': 102, 'label': 'Ferrari California Convertible 2012'}, Since this isn’t an article on data cleaning/preparation, for this initial step, I’m just going to show my code with comments.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



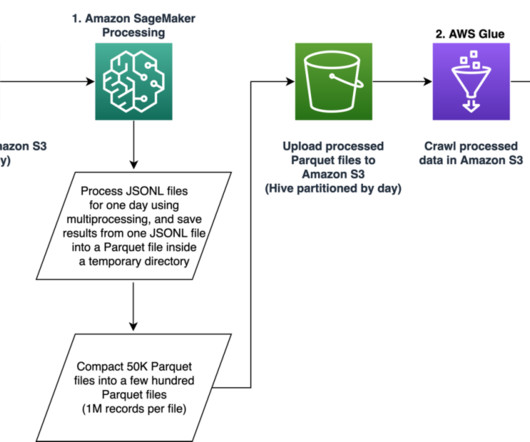


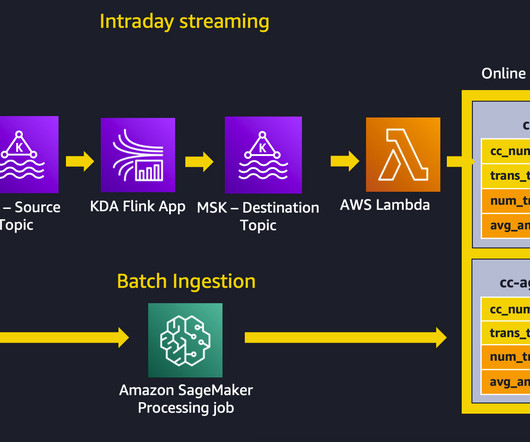









Let's personalize your content