This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. The structured dataset includes order information for products spanning from 2010 to 2017.
Full list of new or updated datasets This dataset joins 33 other new or updated datasets on the Registry of Open Data in four categories: climate and weather, geospatial, life sciences, and machinelearning (ML). 94-171) Demonstration Noisy Measurement File from United States Census Bureau What are people doing with open data?
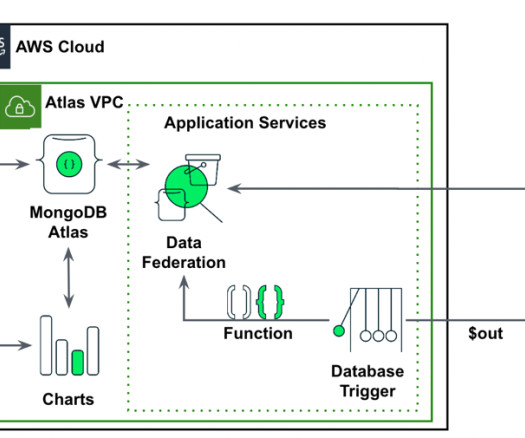
MongoDB’s robust time series data management allows for the storage and retrieval of large volumes of time-series data in real-time, while advanced machinelearning algorithms and predictive capabilities provide accurate and dynamic forecasting models with SageMaker Canvas. Setup the Database access and Network access.
2782 2122 3 UC San Diego 01/01/2010 Bachelor of Science in Marketing */-Maintain the SQL order simple and efficient as you can, using valid SQL Lite, answer the following questions for the table provided above. Data Science. Data Science.
It encompasses everything from CSV files and spreadsheets to relational databases. Tabular data has been around for decades and is one of the most common data types used in data analysis and machinelearning. The prompt asks them to describe what the community has learned over the past two years of working and experimenting.
The concept of data science was first introduced in 2001, but it started gaining popularity in 2010. That’s where the machinelearning came to existence. Data Science is a prerequisite of machinelearning. Machinelearning is not limited to one type of development. Sexiest Job of 21 st Century.
Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first EOM contract with the database company Hyperion—that’s when I was hired. Release v1.0
More than 170 tech teams used the latest cloud, machinelearning and artificial intelligence technologies to build 33 solutions. The fundamental objective is to build a manufacturer-agnostic database, leveraging generative AI’s ability to standardize sensor outputs, synchronize data, and facilitate precise corrections.
Overview of RAG RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and natural language processing (NLP) tasks since 2010. Load into the SQL database for later querying.
Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first OEM contract with the database company Hyperion—that’s when I was hired. Release v1.0
Amazon SageMaker Studio Lab provides no-cost access to a machinelearning (ML) development environment to everyone with an email address. This post is co-written with Stephen Aylward, Matt McCormick, Brianna Major from Kitware and Justin Kirby from the Frederick National Laboratory for Cancer Research (FNLCR).
If you want to check out the new v3 features from spaCy, check out their blog post here: [link] Large Database of 90M Indian Legal Cases “Development Data Lab has processed and de-identified legal case records for all lower courts in India filed between 2010–2018, using the government’s online case-management portal — E-courts.
Summary: Apache Cassandra and MongoDB are leading NoSQL databases with unique strengths. Introduction In the realm of database management systems, two prominent players have emerged in the NoSQL landscape: Apache Cassandra and MongoDB. MongoDB is another leading NoSQL database that operates on a document-oriented model.
in 2010 , found that camel case identifiers led to higher accuracy and lower visual effort when compared to snake case identifiers. How to choose a programming language for your machinelearning project? It is also used for database table and column names in some operating systems.
AWSTemplateFormatVersion: "2010-09-09" Transform: AWS::Serverless-2016-10-31 Description: CloudFormation template for book hotel bot. Similarly, you can use a Lambda function for fulfillment as well, for example writing data to databases or calling APIs save the collected information. Resources: # 1.
These activities cover disparate fields such as basic data processing, analytics, and machinelearning (ML). From 2010 onwards, other PBAs have started becoming available to consumers, such as AWS Trainium , Google’s TPU , and Graphcore’s IPU. For these three training approaches, the role of PBAs varies.
If you want to check out the new v3 features from spaCy, check out their blog post here: [link] Large Database of 90M Indian Legal Cases “Development Data Lab has processed and de-identified legal case records for all lower courts in India filed between 2010–2018, using the government’s online case-management portal — E-courts.
In the main track of Phase 1, solvers submitted a written description of a shareable dataset that could support novel machinelearning approaches for early prediction of AD/ADRD, with an emphasis on addressing biases in existing data sources. These patients, aged 60-75, were eventually diagnosed with AD/ADRD.
In this post, we’ll show you the datasets you can use to build your machinelearning projects. After you create a free account, you’ll have access to the best machinelearning datasets. Importance and Role of Datasets in MachineLearning Data is king.
And as a first indication of this, we can plot the number of new Life structures that have been identified each year (or, more specifically, the number of structures deemed significant enough to name, and to record in the LifeWiki database or its predecessors): Theres an immediate impression of several waves of activity.
Without databases, most software applications would not be possible. Of course, we can’t miss Artificial Intelligence, Deep Learning, MachineLearning, Data Science, HPC, Blockchain, and IoT, which totally relies on data and definitely need a database to store them and process them later.
Large language models (LLMs) can help uncover insights from structured data such as a relational database management system (RDBMS) by generating complex SQL queries from natural language questions, making data analysis accessible to users of all skill levels and empowering organizations to make data-driven decisions faster than ever before.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content