This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At its core, Amazon Bedrock provides the foundational infrastructure for robust performance, security, and scalability for deploying machinelearning (ML) models. Dhawal Patel is a Principal MachineLearning Architect at AWS. He currently is working on Generative AI for data integration.
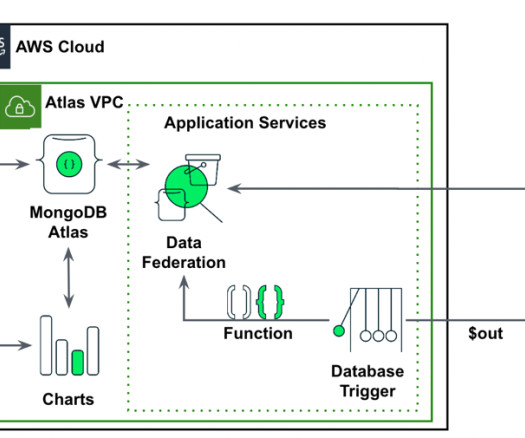
MongoDB’s robust time series data management allows for the storage and retrieval of large volumes of time-series data in real-time, while advanced machinelearning algorithms and predictive capabilities provide accurate and dynamic forecasting models with SageMaker Canvas. Setup the Database access and Network access.
A basic, production-ready cluster priced out to the low-six-figures. A company then needed to train up their ops team to manage the cluster, and their analysts to express their ideas in MapReduce. Plus there was all of the infrastructure to push data into the cluster in the first place. Hello, R and scikit-learn.
Even modern machinelearning applications should use visual encoding to explain data to people. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Nov 2010), which allowed users to drag and drop multiple tables on one sheet. Let’s take a look at each. .
These activities cover disparate fields such as basic data processing, analytics, and machinelearning (ML). Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machinelearning (ML). Spark provides distributed processing on clusters to handle data that is too big for a single machine. Feature quality is critical to ensure a highly accurate ML model.
Iris was designed to use machinelearning (ML) algorithms to predict the next steps in building a data pipeline. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machinelearning.
Even modern machinelearning applications should use visual encoding to explain data to people. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Nov 2010), which allowed users to drag and drop multiple tables on one sheet. Let’s take a look at each. .
Machinelearning is a popular choice here. I tried several other machinelearning classifiers, but SVM turned out to be the best. Furthermore, it involves just dot-products, a fast operation for nowadays machines to carry on. Of course, any machinelearning algorithm requires a proper dataset to train on.
Released as an open-source project in 2008 and later becoming a top-level project of the Apache Software Foundation in 2010, Cassandra has gained popularity due to its scalability and high availability features. Cassandra’s architecture is based on a peer-to-peer model where all nodes in the cluster are equal.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content