This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This study explores the neural and behavioral consequences of LLM-assisted essay writing. Participants were divided into three groups: LLM, Search Engine, and Brain-only (no tools). Across groups, NERs, n-gram patterns, and topic ontology showed within-group homogeneity.
Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Masters degree in technology management and a bachelors degree in telecommunication engineering.
The first big moment came with the launch of DeepSeek -V3, a highly advanced large language model (LLM) that made waves with its cutting-edge advancements in training optimization, achieving remarkable performance at a fraction of the cost of its competitors. Here, the LLM is trained on labeled data for specific tasks.
Building high-quality agents was often too complex, for several reasons: Evaluation is difficult: Many enterprise AI tasks are difficult to evaluate, for both humans and even automated LLM judges. Academic benchmarks such as math exams did not translate to real-world use cases. With ALHF, we’ve solved this with two approaches.
Researchers working in the AI safety subfield of mechanistic interpretability who spend their days studying the complex sequences of mathematical functions that lead to an LLM outputting its next word or pixel, are still playing catch-up. The good news is that theyre making real progress. the AI microscope) work.
eugeneyan Start Here Writing Speaking Prototyping About Evaluating Long-Context Question & Answer Systems [ llm eval survey ] · 28 min read While evaluating Q&A systems is straightforward with short paragraphs, complexity increases as documents grow larger. This is where LLM-evaluators (also called “LLM-as-Judge”) can help.
Want to build a custom llm application? However, mastering LLMs requires a comprehensive understanding of their underlying principles, architectures, and training techniques. Step 2: Explore LLM architectures LLMs come in various architectures, each with its strengths and limitations.
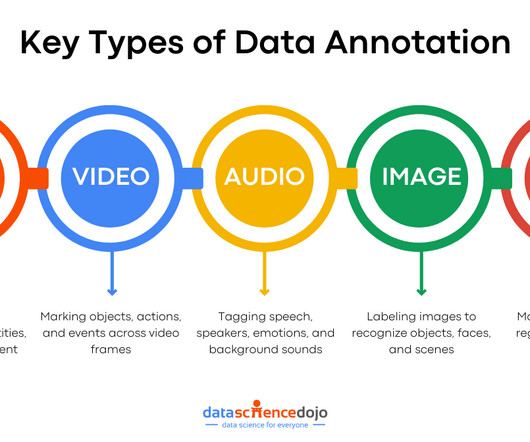
It enables AI systems to recognize patterns, understand them, and make informed predictions. For LLMs, this annotated data forms the backbone of their ability to comprehend and generate human-like language. Similarly, it also results in enhanced conversations with an LLM, ensuring the results are context-specific.
Because LLM usage costs are decreasing, GPT 4.1 Industry Related Practice Now, LLMs are evolving into agents. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL. But that’s where the cost-reducing requests enter. Now, RAG has also evolved.
I’m fascinated by this discussion, particularly from my sociologist’s perspective, because so much of the conversation seems to be about whether an LLM is useful. Instead of thinking about it so narrowly, I actually really want to talk about the broader context of software engineering in the context of LLM technology. (I
For example, a technician could query the system about a specific machine part, receiving both textual maintenance history and annotated images showing wear patterns or common failure points, enhancing their ability to diagnose and resolve issues efficiently. In practice, the router module can be implemented with an initial LLM call.
Furthermore, researchers have identified that LLM-generated fabrications can be exploited to disseminate malicious code packages to unsuspecting software developers. Additionally, LLMs often provide erroneous advice related to mental health and medical matters, such as the unsupported claim that wine consumption can “prevent cancer.”
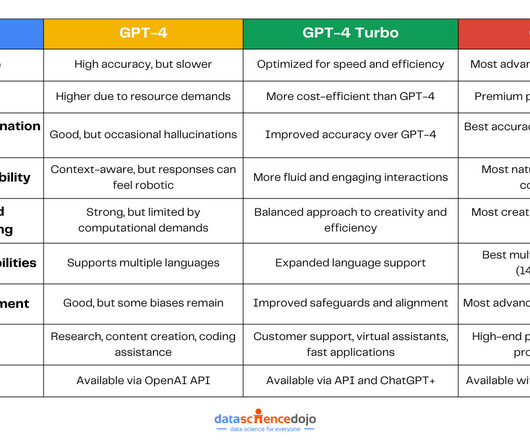
This latest large language model (LLM) is a powerful tool for natural language processing (NLP). Since Llama 2’s launch last year, multiple LLMs have been released into the market including OpenAI’s GPT-4 and Anthropic’s Claude 3. Hence, the LLM market has become highly competitive and is rapidly advancing.
Why its key : Paying attention to dependencies, patterns, and interrelationships among elements of the same sequence is incredibly useful to extract a deep meaning and context of the input sequence being understood, as well as the target sequence being generated as a response — thereby enabling more coherent and context-aware outputs.
Tools Required(requirements.txt) The necessary libraries required are: PyPDF : A pure Python library to read and write PDF files. Folder Structure Before starting, it’s good to organize your project files for clarity and scalability. I will explain the purpose of each of the remaining files step by step. Show extracted image metadata.
You had to combine columns and sort them by writing long formulas. Data Analytics Agents The agents went one step further than traditional LLM interaction. As powerful as these LLMs were, it felt like something was missing. The Dominance of Microsoft Excel In the 90s and early 2000s, we used Microsoft Excel for everything.
This equates to asking someone to write an 800-word blog on AI agents in one go, without any edits. They let the LLM go over the task multiple times, fine-tuning the results each time. This process uses extra tools and smarter decision-making to really leverage what LLMs can do, especially for specific, targeted projects.
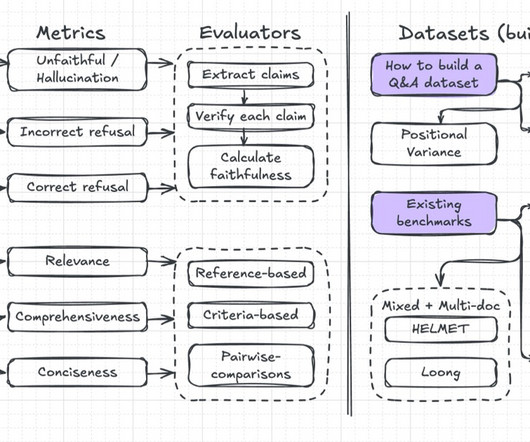
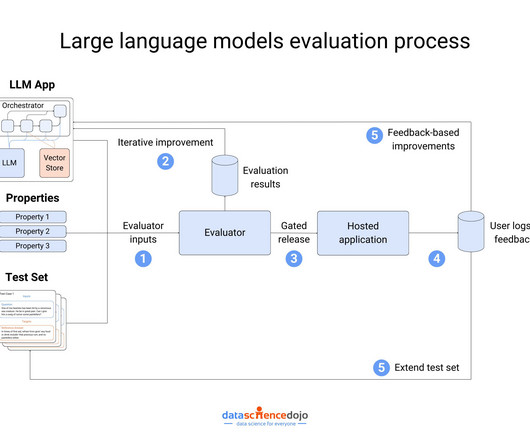
What is LLM Evaluation? LLM evaluation is all about testing how well a large language model performs. In simple terms, LLM evaluation shows us where models excel and where they still need work. Why is LLM Evaluation Significant? Major LLM Evaluation Benchmark Datasets 1. Let’s dig in. What is its Purpose?
Organizations are increasingly using multiple large language models (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements. In this post, we provide an overview of common multi-LLM applications.
That is, an agent is a for loop which contains an LLM call. The LLM can execute commands and see their output without a human in the loop. User LLM prompt bash, patch, etc tool call tool result Response & End of turn That’s it. Asking an agentless LLM to write code is equivalent to asking you to write code on a whiteboard.
Learn more The generative AI boom has given us powerful language models that can write, summarize and reason over vast amounts of text and other types of data. Kumo’s RFM applies this same attention mechanism to the graph, allowing it to learn complex patterns and relationships across multiple tables simultaneously.
Large language models (LLMs) are AI models that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. In this blog, we will take a deep dive into LLMs, including their building blocks, such as embeddings, transformers, and attention.
Want to build a custom llm application? However, mastering LLMs requires a comprehensive understanding of their underlying principles, architectures, and training techniques. Step 2: Explore LLM Architectures LLMs come in various architectures, each with its strengths and limitations.
These “DNA foundation models” are fantastic at recognizing patterns, but they have a major limitation: they operate as “black boxes.” On the other hand, large language nodels (LLMs) , the technology behind tools like ChatGPT, have become masters of reasoning and explanation.
DeepSeek-R1 is an advanced LLM developed by the AI startup DeepSeek. Simplified LLM hosting on SageMaker AI Before orchestrating agentic workflows with CrewAI powered by an LLM, the first step is to host and query an LLM using SageMaker real-time inference endpoints.
How prompt caching works Large language model (LLM) processing is made up of two primary stages: input token processing and output token generation. As you send more requests with the same prompt prefix, marked by the cache checkpoint, the LLM will check if the prompt prefix is already stored in the cache.
Text generation inference represents a fascinating frontier in artificial intelligence, where machines not only process language but also create new content that mimics human writing. This technology has opened a plethora of applications, impacting industries ranging from customer service to creative writing.
TL;DR LangChain provides composable building blocks to create LLM-powered applications, making it an ideal framework for building RAG systems. The experiment tracker can handle large amounts of data, making it well-suited for quick iteration and extensive evaluations of LLM-based applications. Source What is LangChain? ragas== 0.2.8
ReLM enables writing tests that are guaranteed to come from the set of valid strings, such as dates. Without ReLM, LLMs are free to complete prompts with non-date answers, which are difficult to assess. I claim that using large language models (LLMs) to generate text content is similar to playing a game with such secret sequences.
Indirect prompt injection occurs when a large language model (LLM) processes and combines untrusted input from external sources controlled by a bad actor or trusted internal sources that have been compromised. When a user submits a query, the LLM retrieves relevant content from these sources.
Marta Kryven, Cole Wyeth, Aidan Curtis, and Kevin Ellis suggest our knack for planning comes from a core belief: the world usually follows predictable patterns. We look for patterns, and we use them. Not for planning, but for writing code. They prompted the LLM to spot repeating visual patterns in the maze.
LLM summarization is a cutting-edge technique harnessing the capabilities of large language models to streamline the way we consume vast amounts of information. What is LLM summarization? LLM summarization involves the use of advanced algorithms and large language models (LLMs) to create concise summaries from extensive text.
Expanding LLM capabilities with tool use LLMs excel at natural language tasks but become significantly more powerful with tool integration, such as APIs and computational frameworks. the LLM evaluates its repertoire of tools to determine whether an appropriate tool is available. Choose us-east-1 as the AWS Region.
Lets explore how CoT prompting works and why its a key tool in enhancing LLM performance. Chain-of-thought prompting (CoT) is a technique in prompt engineering that improves the ability of large language models (LLMs) to handle tasks requiring complex reasoning, logic, and decision-making. What is chain-of-thought prompting (CoT)?
Early large language models (LLMs) were essentially clever text predictors : Given some input, theyd generate a continuation based on patterns in training data. They were powerful for answering questions or writing text, but functionally isolated they had no built-in way to use external tools or real-time data.
For MCP implementation, you need a scalable infrastructure to host these servers and an infrastructure to host the large language model (LLM), which will perform actions with the tools implemented by the MCP server. You can deploy your model or LLM to SageMaker AI hosting services and get an endpoint that can be used for real-time inference.
The next generation of Language Model Systems (LLMs) and LLM chatbots are expected to offer improved accuracy, expanded language support, enhanced computational efficiency, and seamless integration with emerging technologies. To overcome these challenges, Large Language Models (LLMs) come to the rescue.
These AI agents have demonstrated remarkable versatility, being able to perform tasks ranging from creative writing and code generation to data analysis and decision support. One of the most significant impacts of generative AI agents has been their potential to augment human capabilities through both synchronous and asynchronous patterns.
Martin Ruiz, Content Specialist, Kanto Pattern is a leader in ecommerce acceleration, helping brands navigate the complexities of selling on marketplaces and achieve profitable growth through a combination of proprietary technology and on-demand expertise. Select Brands looked to improve their Amazon performance and partnered with Pattern.
The evaluation of large language model (LLM) performance, particularly in response to a variety of prompts, is crucial for organizations aiming to harness the full potential of this rapidly evolving technology. Both features use the LLM-as-a-judge technique behind the scenes but evaluate different things.
Agent Creator is a no-code visual tool that empowers business users and application developers to create sophisticated large language model (LLM) powered applications and agents without programming expertise. LLM Snap Pack – Facilitates interactions with Claude and other language models.
That’s essentially what an LLM is! By analyzing this data, LLMs become experts at recognizing patterns and relationships between words. Some LLMs, like LaMDA by Google AI , can help you brainstorm ideas and even write different creative text formats based on your initial input. Read more about it here.
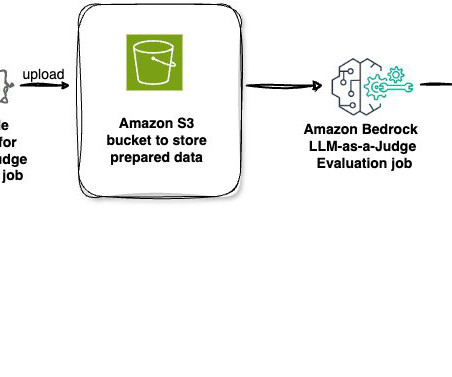
In December 2024, AWS launched the AWS Large Language Model League (AWS LLM League) during re:Invent 2024. The submitted model would be compared against a bigger 90B reference model with the quality of the responses decided using an LLM-as-a-Judge approach. Competitors were tasked with customizing Metas Llama 3.2
A wide range of applications deals with a variety of tasks, ranging from writing, E-learning, and SEO to medical advice, marketing, data analysis, and so much more. It is capable of writing and running Python codes. This GPT is created by LLM Imagineers. This custom GPT is created by Open AI’s ChatGPT.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























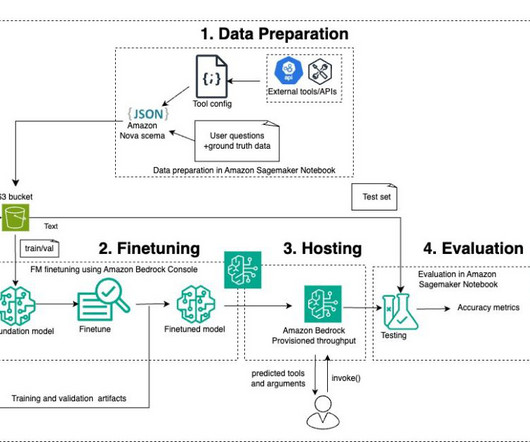


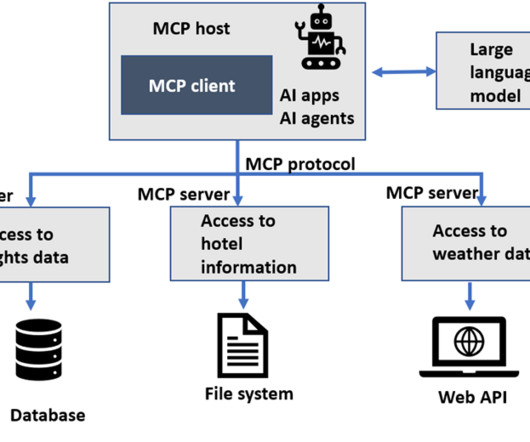


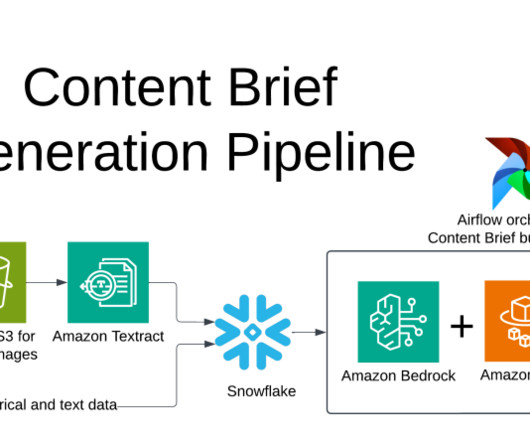








Let's personalize your content