This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
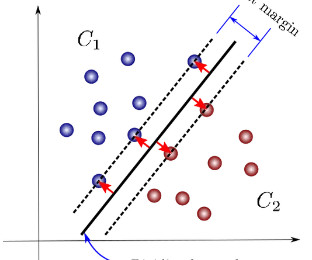
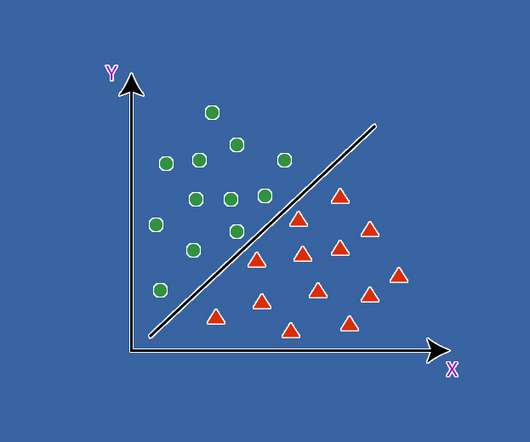
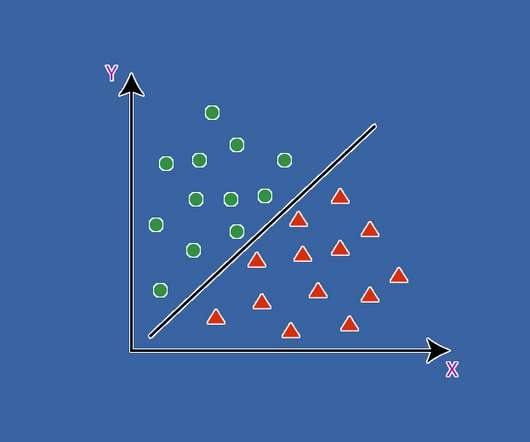
SupportVectorMachines (SVM) are a cornerstone of machine learning, providing powerful techniques for classifying and predicting outcomes in complex datasets. What are SupportVectorMachines (SVM)? They work by identifying a hyperplane that best separates distinct classes within the data.
Supportvectormachines (SVM) are at the forefront of machine learning techniques used for both classification and regression tasks. What are supportvectormachines (SVMs)? Advantages of supportvectormachines SVMs offer several advantages, particularly in terms of accuracy and efficiency.
SupportVectorMachines, or SVM, is a machine learning algorithm that, in its original form, is utilized for binary classification. Last Updated on November 3, 2024 by Editorial Team Author(s): Fernando Guzman Originally published on Towards AI.
Hinge loss is pivotal in classification tasks and widely used in SupportVectorMachines (SVMs), quantifies errors by penalizing predictions near or across decision boundaries. By promoting robust margins between classes, it enhances model generalization.
Hyperparameter tuning is a technical process to tune the configuration settings of machine learning models, called hyperparameters, before training the model.
We applied various machine learning models, such as logistic regression, naive Bayes, supportvectormachine, decision tree, random forest, gradient boosting decision tree, and adaptive boosting, to analyze the students’ negative academic emotions.
SupportVectorMachines were disrupted by deep learning, and convolutional neural networks were displaced by transformers. As an example, the speech recognition community spent decades focusing on Hidden Markov Models at the expense of other architectures, before eventually being disrupted by advancements in deep learning.
Examples include: Spam vs. Not Spam Disease Positive vs. Negative Fraudulent Transaction vs. Legitimate Transaction Popular algorithms for binary classification include Logistic Regression, SupportVectorMachines (SVM), and Decision Trees. These models can detect subtle patterns that might be missed by human radiologists.
More On This Topic Principal Component Analysis (PCA) with Scikit-Learn A Gentle Introduction to Rust for Python Programmers A Gentle Introduction to Go for Python Programmers A Gentle Introduction to SupportVectorMachines A Gentle Introduction to Symbolic AI Introduction to Python Libraries for Data Cleaning Our Top 5 Free Course Recommendations (..)
However, the combination of EfficientNetB0 pre-training with ML SupportVectorMachines (SVM) produced optimal results with accuracy, sensitivity, specificity, precision, F1-Score, and AUC, of 99.4%, 98.7%, 99.1%, 99%, 98.8%, and 100%, respectively. This work employed and tested a variety of pre-training and ML techniques.
Develop Hybrid Models Combine traditional analytical methods with modern algorithms such as decision trees, neural networks, and supportvectormachines. Clustering algorithms, such as k-means, group similar data points, and regression models predict trends based on historical data.
SupportVectorMachines (SVMs): Parameters include the weights defining the hyperplane that separates classes. Neural Networks: Parameters include weights and biases for each neuron connection. These parameters determine how input features are transformed through layers to produce outputs.
Comparison with Other Classification Techniques Associative classification differs from traditional classification methods like decision trees and supportvectormachines (SVM). The computational cost and complexity of implementing associative classification in large-scale operations can pose significant challenges.
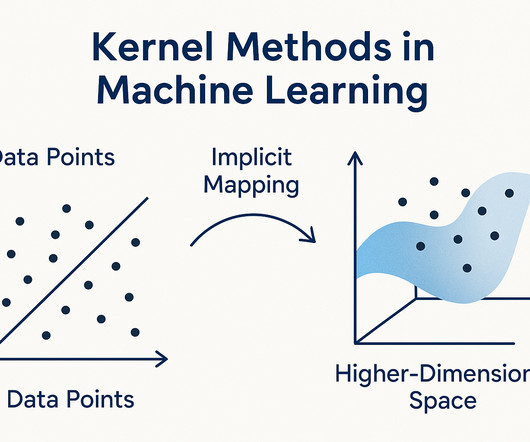
Helping Algorithms Like SVM SupportVectorMachines ( SVM ) are popular machine learning tools that work well with kernel methods. Frequently Asked Questions What are kernel methods in machine learning? Kernel methods solve this by lifting the data into a new space where it becomes easier to separate.
Among the most significant models are non-linear models, supportvectormachines, and linear regression. Supportvectormachines (SVM) SupportVectorMachines are a robust classification technique in machine learning.
Some examples of supervised algorithms are linear regression, logistic regression, supportvectormachines, and decision trees. SupportVectorMachines (SVM): SVMs find the optimal boundary that separates classes in the data, often used for high-dimensional datasets.
Supportvectormachine (SVM) Supportvectormachines excel in high-dimensional spaces, making them suitable for complex classification tasks. Its simplicity and interpretability make it a popular choice, particularly in fields requiring clear explanations of predictive relationships.
SupportVectorMachines (SVM) SVMs are powerful classification algorithms that work by finding the hyperplane that best separates different classes in high-dimensional space. Commonly used algorithms include SupportVectorMachines, Random Forests, and Gradient Boosting methods; however, selection should be based on testing.
Common types of surrogate models Surrogate modeling encompasses various machine learning methodologies, including: Polynomial regressions: Useful for capturing relationships in a straightforward manner. Supportvectormachines: Effective in high-dimensional spaces and can handle nonlinearities.
Supportvectormachines: SVMs employ convex optimization to find the optimal hyperplane that classifies data into two categories. Common applications Portfolio optimization: In finance, convex optimization models help in selecting the best combination of assets to maximize returns while minimizing risk.
Classification algorithms like supportvectormachines (SVMs) are especially well-suited to use this implicit geometry of the data. The previous visualization of the embeddings space displayed only a 2D transformation of this space. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
This work aims to assess the performance of numerous combinations of machine learning methods to detect alpha and beta-thalassemia in their minor and major types. The analyzed models are K-nearest Neighbor (KNN), SupportVectorMachine (SVM), and Extreme Gradient Boosting (XGBoost).
Supportvectormachine (SVM) SVM functions as both a classification and regression tool, utilizing the concept of margins and kernels to optimize performance. Pros: Offers clear quantitative insights and is easy to implement. Cons: Susceptible to model dependency and may exhibit limited flexibility with complex data patterns.
Applications of hyperplanes in machine learning Hyperplanes play a critical role in various machine learning algorithms, ranging from classification to clustering and regression. Understanding supporting hyperplanes further enriches the concept of hyperplanes and their role in machine learning.
Learning the decision boundary Machine learning algorithms learn decision boundaries through a training process that adjusts the model’s parameters based on the input data. Algorithms like logistic regression or supportvectormachines focus on optimizing the decision boundary to minimize misclassification errors.
To enhance predictive accuracy, machine learning models Linear Regression, Random Forest Regression, SupportVectorMachines (SVM), K-Means Clustering, and Artificial Neural Networks (ANN) were employed to analyze combustion-induced degradation trends, confirming Test-06 as the optimal balance of stability and high performance.
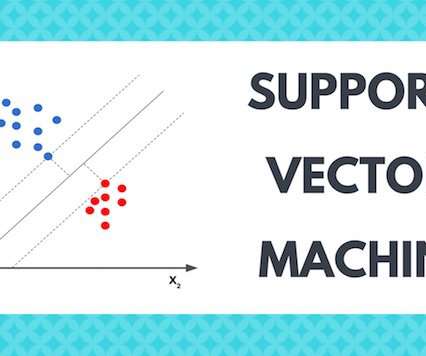
SupportVectorMachines: A method that finds the hyperplane separating different classes with the largest margin. Logistic Regression: A statistical method for binary classification that models the probability of a class based on input features.
Rico Angell (CDS Postdoctoral Researcher) Monitoring LLM Agents for Sequentially Contextual Harm (Building Trust WorkshopPaper) Sam Bowman (CDS Associate Professor of Linguistics and Data Science) Language Models Learn to Mislead Humans via RLHF (Poster) Inverse Scaling: When Bigger Isnt Better (Poster) Beyond the Imitation Game: Quantifying (..)
Some common supervised learning algorithms include decision trees, random forests, supportvectormachines, and linear regression. Algorithms Used in Supervised vs Unsupervised Learning Supervised learning relies on well-known algorithms that help in classification and regression tasks.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article, we will be discussing SupportVectorMachines. The post SupportVectorMachine: Introduction appeared first on Analytics Vidhya.
Machine learning methods: Methods like decision trees, neural networks, and supportvectormachines, each utilize specific algorithms to identify patterns in datasets. Business ventures: Startups increasingly leverage pattern recognition, creating innovative solutions in various sectors.
This article was published as a part of the Data Science Blogathon Introduction to SupportVectorMachine(SVM) SVM is a powerful supervised algorithm that works best on smaller datasets but on complex ones. The post SupportVectorMachine(SVM): A Complete guide for beginners appeared first on Analytics Vidhya.
Introduction Supportvectormachines are one of the most widely used machine learning algorithms known for their accuracy and excellent performance on any dataset.
The post Understanding Naïve Bayes and SupportVectorMachine and their implementation in Python appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Introduction In this digital world, spam is the most troublesome challenge that.
Later, we will discuss the Maximal-Margin Classifier and Soft Margin Classifier for SupportVectorMachine. The post SupportVectorMachine with Kernels and Python Iterators appeared first on Analytics Vidhya. At last, we will learn about some SVM Kernels, such as Linear, Polynomial, and […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction SupportVectorMachine (SVM) is one of the Machine Learning. The post The A-Z guide to SupportVectorMachine appeared first on Analytics Vidhya.
The SupportVectorMachine algorithm is one of the most popular supervised machine learning techniques, and it comes implemented in the OpenCV library. This tutorial will introduce the necessary skills to start using SupportVectorMachines in OpenCV, using a custom dataset that we will generate.
Gradient boosting machines (GBM): Sequentially builds decision models to enhance predictive power. Supportvectormachines (SVM): Focuses on class separation through hyperplanes. Random forests: An ensemble technique utilizing multiple trees for improved stability and accuracy.
SupportVectorMachines (SVMs) are powerful for solving regression and classification problems. You should have this approach in your machine learning arsenal, and this article provides all the mathematics you need to know -- it's not as hard you might think.
Introduction Classification problems are often solved using supervised learning algorithms such as Random Forest Classifier, SupportVectorMachine, Logistic Regressor (for binary class classification) etc. The post One Class Classification Using SupportVectorMachines appeared first on Analytics Vidhya.
Ever wondered, how great would it be, if we could predict, whether our request for a loan, will be approved or not, simply by the use of machine learning, from the ease and comfort […]. The post Loan Status Prediction using SupportVectorMachine (SVM) Algorithm appeared first on Analytics Vidhya.
The post The Mathematics Behind SupportVectorMachine Algorithm (SVM) appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Introduction One of the classifiers that we come across while learning about.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content