This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
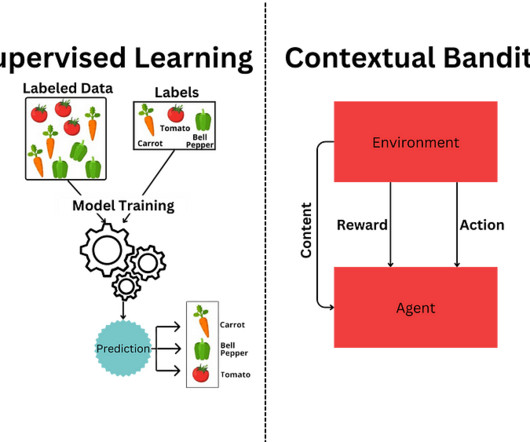
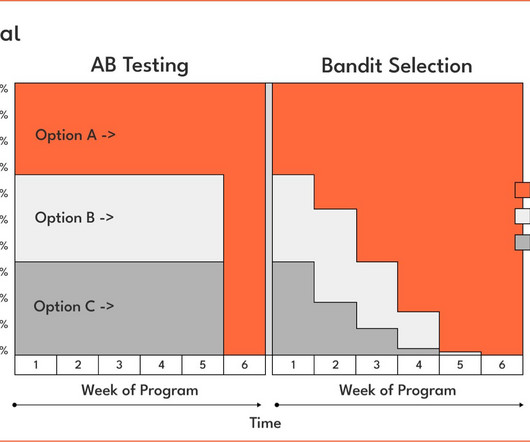
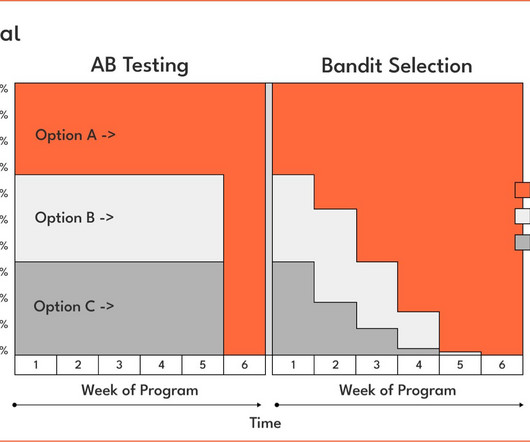
SupervisedLearning: Train once, deploy static model; Contextual Bandits: Deploy once, allow the agent to adapt actions based on content and its corresponding reward. Supervisedlearning is a staple in machine learning for well-defined problems, but it struggles to adapt to dynamic environments: enter contextual bandits.
This paper demonstrates an approach for learning highly semantic image representations without relying on hand-crafted data-augmentations. We introduce the Image-based Joint-Embedding Predictive Architecture (I-JEPA), a non-generative approach for self-supervisedlearning from images.
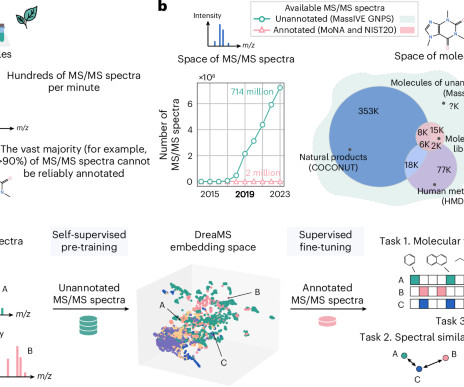
Characterizing biological and environmental samples at a molecular level primarily uses tandem mass spectroscopy (MS/MS), yet the interpretation of tandem mass spectra from untargeted metabolomics experiments remains a challenge.
This study explores using embedding rank as an unsupervised evaluation metric for general-purpose speech encoders trained via self-supervisedlearning (SSL). Traditionally, assessing the performance of these encoders is resource-intensive and requires labeled data from the downstream tasks.
Typical SSL Architectures Introduction: The Rise of Self-SupervisedLearning In recent years, Self-SupervisedLearning (SSL) has emerged as a pivotal paradigm in machine learning, enabling models to learn from unlabeled data by generating their own supervisory signals.
It blends supervisedlearning foundations with reward-based updates to make them safer, more accurate, and genuinely helpful. Reinforcement finetuning has shaken up AI development by teaching models to adjust based on human feedback.
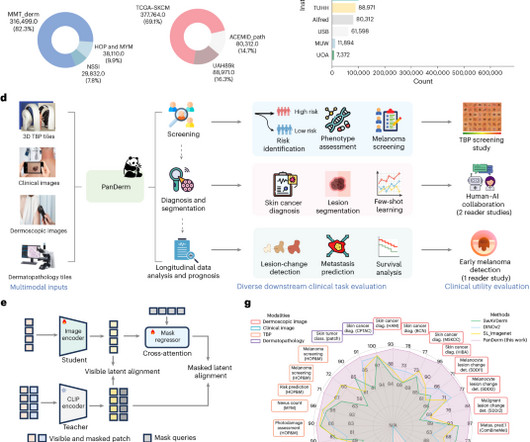
While current deep learning models excel at specific tasks such as skin cancer diagnosis from dermoscopic images, they struggle to meet the complex, multimodal requirements of clinical practice.
Semi-supervisedlearning is reshaping the landscape of machine learning by bridging the gap between supervised and unsupervised methods. With vast amounts of unlabeled data available in various domains, semi-supervisedlearning proves to be an invaluable tool in tackling complex classification tasks.
Supervisedlearning is a powerful approach within the expansive field of machine learning that relies on labeled data to teach algorithms how to make predictions. What is supervisedlearning? Supervisedlearning refers to a subset of machine learning techniques where algorithms learn from labeled datasets.
Supervisedlearning applications: Use labeled data to teach the system how to classify images accurately. Unsupervised learning insights: Allow systems to discover patterns and groupings within unlabeled data.
Change the guest list or seating logic, and you get dimensionality reduction, self-supervisedlearning, or spectral clustering. The I-Con framework shows that algorithms differ mainly in how they define those relationships. It all boils down to preserving certain relationships while simplifying others.
Have you ever felt like the world of machine learning is moving so fast that you can barely keep up? One day, its all about supervisedlearning and the next, people are throwing around terms like self-supervisedlearning as if its the holy grail of AI. So, what exactly is self-supervisedlearning?
Challenges in supervisedlearningSupervisedlearning often grapples with data limitations, particularly the scarcity of labeled examples necessary for training algorithms effectively. Such flaws can lead to significant consequences in critical fields like healthcare or finance.
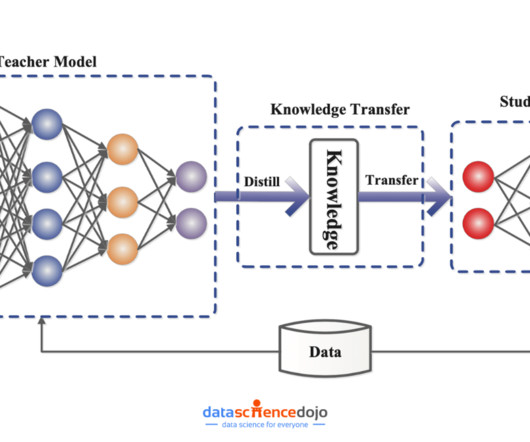
Now, it is time to train the teacher model on the dataset using standard supervisedlearning. We need to then define a function that combines soft label loss (teachers predictions) and hard label loss (ground truth) to train the student model. Finally, we can evaluate the models on the test dataset and print their accuracy.
Key Characteristics of LLMs: Built on transformer architecture Trained on large corpora using self-supervisedlearning Capable of understanding context, semantics, grammar, and even logic Scalable and general-purpose, making them adaptable across tasks and industries Learn more about LLMs and their applications.
Goals of supervisedlearning In supervisedlearning tasks, managing the bias-variance tradeoff aligns with specific objectives. Mimicking the target function (f) In supervisedlearning, the primary goal is to build models that genuinely mimic the target function relating inputs to outputs.
Inspired by its reinforcement learning (RL)-based optimization, I wondered: can we apply a similar RL-driven strategy to supervisedlearning? Instead of manually selecting a model, why not let reinforcement learninglearn the best strategy for us?
Increasingly, FMs are completing tasks that were previously solved by supervisedlearning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. An FM-driven solution can also provide rationale for outputs, whereas a traditional classifier lacks this capability.
Can I Use Autoencoders for SupervisedLearning Tasks? Yes, autoencoders can enhance supervisedlearning tasks. By pre-training the model on unlabeled data to learn useful features, you can improve classification or regression performance on labelled datasets.
While deep neural networks have become an increasingly popular alternative to kernel methods for machine learning over the past decade, kernel-based systems have seen a resurgence in the past few years due to their relative simplicity and advantages when working with small datasets.
Applications of linear regression in machine learning Linear regression plays a significant role in supervisedlearning, where it models relationships based on a labeled dataset. Understanding supervisedlearning In supervisedlearning, algorithms learn from training data that includes input-output pairs.
In Part 2, we compared Contextual Bandits to SupervisedLearning, highlighting the advantages of adaptive optimization over static learning. In Part 1, we introduced the concept of Contextual Bandits, a powerful technique for solving real-time decision-making problems.
Machine learning forms a core subset of artificial intelligence and has a heavy influence in modern technology ranging from recommendation engines to self-driving cars. SupervisedLearning Algorithms One of the most common applications of machine learning occurs in supervisedlearning.
InfoNCE Loss (Information Noise Contrastive Estimation): A popular variant of contrastive loss, InfoNCE measures similarity by treating the problem as a binary classification task: given a positive pair and a set of negative pairs, the model learns to discriminate them. It’s widely used in self-supervisedlearning for its effectiveness.
Learn how to build resilient, production-grade AI systems end-to-end. Deep Learning & Multi‑Modal Models Explore foundational and advanced deep learning — from CNNs and GANs to transformers, self-supervisedlearning, and reinforcement methods — plus integration with multi-modal systems.
In Part 2, we compared Contextual Bandits to SupervisedLearning, highlighting the advantages of adaptive optimization over static learning. In Part 1, we introduced the concept of Contextual Bandits, a powerful technique for solving real-time decision-making problems.
Have you ever looked at AI models and thought, How the heck does this thing actually learn? Supervisedlearning, a cornerstone of machine learning, often seems like magic like feeding a computer some data and watching it miraculously predict things. This member-only story is on us. Upgrade to access all of Medium.
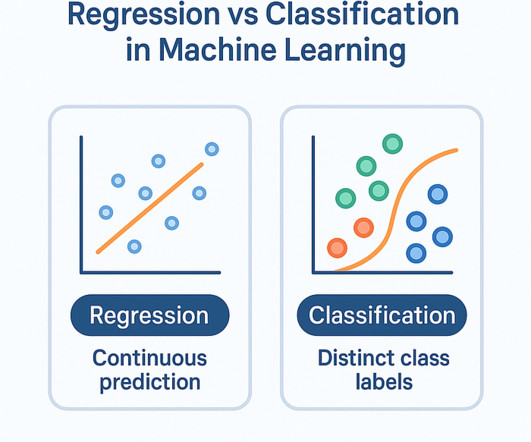
Regression vs Classification in Machine Learning Why Most Beginners Get This Wrong | M004 If youre learning Machine Learning and think supervisedlearning is straightforward, think again. When I first started with supervisedlearning, I picked models like they were tools in a toolbox.
Using deep learning and transformer-based models, SparkAI processes extensive audio datasets to analyze tonal characteristics and generate realistic guitar sounds. The system applies self-supervisedlearning techniques, allowing it to adapt to different playing styles without requiring manually labeled training data.
Supervisedlearning means training an AI model using examples with labels. If labels are wrong or messy, the model learns the wrong thing. It’s where model accuracy begins. What defines high-quality data annotation? Not all labels are equal. These annotations tell the model what it’s looking at or working with.
Types of Machine Learning Algorithms Machine Learning has become an integral part of modern technology, enabling systems to learn from data and improve over time without explicit programming. The goal is to learn a mapping from inputs to outputs, allowing the model to make predictions on unseen data.
Theres another reason we are doing this, let me clarify it a bit later. from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.2, random_state=42) Preprocessing the data and making it suitable for the PCA algorithm is as important as applying the algorithm itself.
It enables systems to automatically learn and improve from experience without being explicitly programmed. Machine learning can be categorized as: Supervisedlearning : Uses labeled data to train models for prediction or classification tasks. What are some artificial intelligence techniques examples?
Support Vector Machines (SVM) are a type of supervisedlearning algorithm designed for classification and regression tasks. In the context of SVMs, it serves as the decision boundary that separates different classes of data, allowing for distinct classifications in supervisedlearning.
We know that model learning is scalable, because its just supervisedlearning. So why dont we combine the two, where we first learn a model and run on-policy RL within the model? Would model-based RL indeed scale better than TD-based Q-learning? We also know that on-policy RL is scalable.
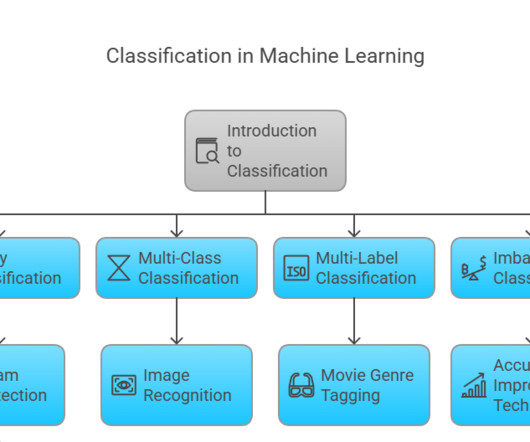
Classification is a subset of supervisedlearning, where labelled data guides the algorithm to make predictions. Classifiers are algorithms designed to perform this task efficiently, helping industries solve problems like spam detection, fraud prevention, and medical diagnosis.
The primary types of learning approaches include: SupervisedLearning In this approach, the model is trained using labelled data, where the input-output pairs are provided. The goal is to learn a mapping from inputs to outputs, allowing the model to make predictions on unseen data. predicting house prices).
Machine learning Structured data is crucial in machine learning applications. It provides clear and organized datasets essential for training supervisedlearning models. Data management SQL databases and tools like Excel frequently utilize structured data for efficient business intelligence and data tracking.
Training on Massive Datasets LLMs are trained using unsupervised or semi-supervisedlearning on huge text corpora, including books, websites, code, news, and forums. Training on diverse and large-scale data enables the model to learn grammar, facts, styles, reasoning, and even world knowledge.
To excel in ML, you must understand its key methodologies: SupervisedLearning: Involves training models on labeled datasets for tasks like classification (e.g., spam detection) and regression (e.g., predicting housing prices).
This is in contrast to the previous step of supervisedlearning, where the model is shown explicit pairs of inputs and ideal outputs and learns to mimic them directly. It doesn’t learn which answers are better than others — just how to replicate the provided ones.
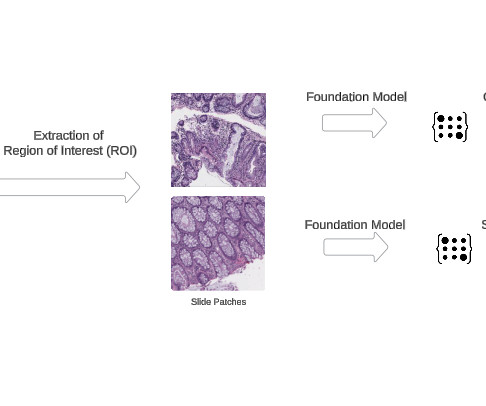
These models are trained using self-supervisedlearning algorithms on expansive datasets, enabling them to capture a comprehensive repertoire of visual representations and patterns inherent within pathology images.
CDS Assistant Professor Mengye Ren and collaborators have developed a new self-supervisedlearning method that tackles this challenge. The research, published as “ PooDLe🐩: Pooled and Dense Self-SupervisedLearning from Naturalistic Videos ” at ICLR 2025 , addresses a fundamental problem in computer vision.
Meme shared by bin4ry_d3struct0r TAI Curated section Article of the week Reinforcement Learning-Driven Adaptive Model Selection and Blending for SupervisedLearning By Shenggang Li This article discusses a novel framework for adaptive model selection and blending in supervisedlearning inspired by reinforcement learning (RL) techniques.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content