This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using Amazon Bedrock Knowledge Bases, FMs and agents can retrieve contextual information from your company’s private data sources for RAG. It supports exact and approximate nearest-neighbor algorithms and multiple storage and matching engines. For information on creating service roles, refer to Service roles. Choose Next.
In this tutorial, well explore how OpenSearch performs k-NN (k-NearestNeighbor) search on embeddings. How OpenSearch Uses Neural Search and k-NN Indexing Figure 6 illustrates the entire workflow of how OpenSearch processes a neural query and retrieves results using k-NearestNeighbor (k-NN) search.
The ability to quickly access relevant information is a key differentiator in todays competitive landscape. It supports advanced features such as result highlighting, flexible pagination, and k-nearestneighbor (k-NN) search for vector and semantic search use cases. Also, Cohere Rerank 3.5, with OpenSearch Service.
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. This type of data is often used in ML and artificial intelligence applications.
Retrieval (and reranking) strategy FloTorch used a retrieval strategy with a k-nearestneighbor (k-NN) of five for retrieved chunks. For more information, contact us at info@flotorch.ai. Dr. Hemant Joshi has over 20 years of industry experience building products and services with AI/ML technologies.
a low-code enterprise graph machine learning (ML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. With GraphStorm, we release the tools that Amazon uses internally to bring large-scale graph ML solutions to production. license on GitHub. GraphStorm 0.1
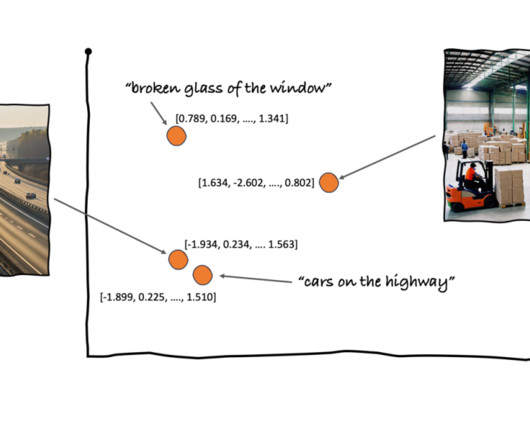
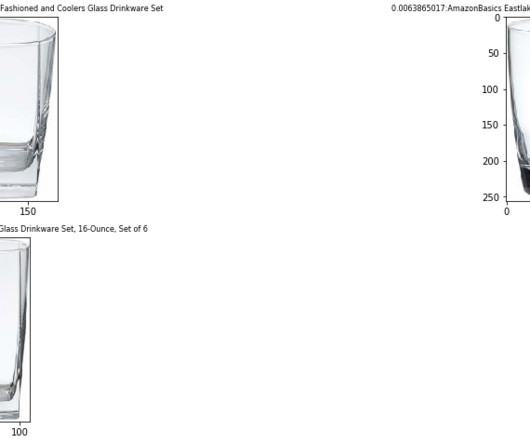
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. For more information on managing credentials securely, see the AWS Boto3 documentation. The closer vectors are to one another in this space, the more similar the information they represent is.
Machine learning (ML) has proven that it is here with us for the long haul, everyone who had their doubts by calling it a phase should by now realize how wrong they are, ML has being used in various sector’s of society such as medicine, geospatial data, finance, statistics and robotics.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? This will be a good way to get familiar with ML. Types of Machine Learning for GIS 1.
Example: Determining whether an email is spam or not based on features like word frequency and sender information. k-NearestNeighbors (k-NN) k-NN is a simple algorithm that classifies new instances based on the majority class among its knearest neighbours in the training dataset.
Comparison of approaches SlideVQA is a collection of publicly available slide decks, each composed of multiple slides (in JPG format) and questions based on the information in the slide decks. We performed a k-nearestneighbor (k-NN) search to retrieve the most relevant embedding matching the question.
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
Realizing the impact of these applications can provide enhanced insights to the customers and positively impact the performance efficiency in the organization, with easy information retrieval and automating certain time-consuming tasks. For more information about foundation models, see Getting started with Amazon SageMaker JumpStart.
We shall look at various machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. I wrote about Python ML here. Join thousands of data leaders on the AI newsletter.
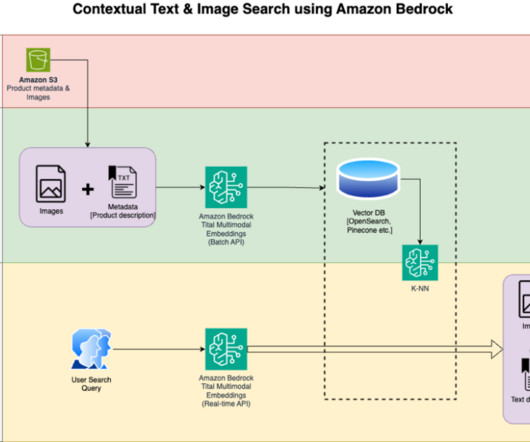
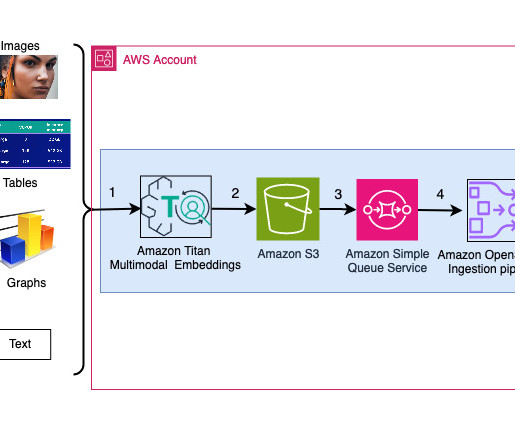
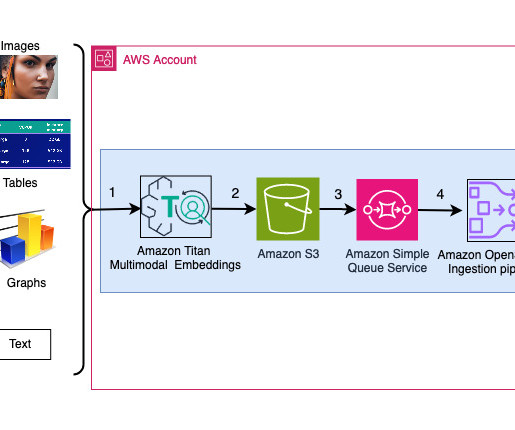
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality. In her free time, she likes to go for long runs along the beach.
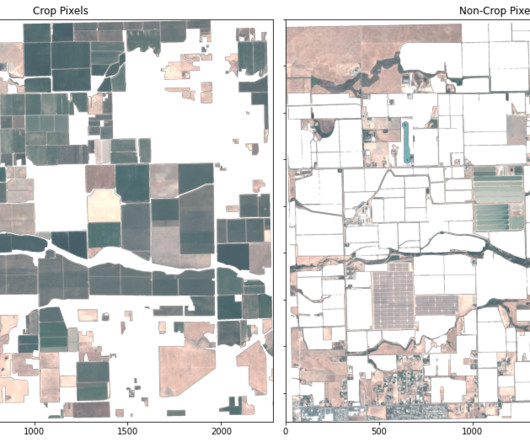
In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image. Identifying crop regions is a core step towards gaining agricultural insights, and the combination of rich geospatial data and ML can lead to insights that drive decisions and actions.
Since the inception of AWS GenAIIC in May 2023, we have witnessed high customer demand for chatbots that can extract information and generate insights from massive and often heterogeneous knowledge bases. Augmentation : The retrieved information is added to the FM prompt (3.a) a) to augment its knowledge, along with the user query (3.b).
Solution overview The solution provides an implementation for answering questions using information contained in text and visual elements of a slide deck. We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. I need numbers. Up to 4x higher throughput.
It could contain information in the form of text, or embedded in graphs, tables, and pictures. Solution overview The solution provides an implementation for answering questions using information contained in the text and visual elements of a slide deck. Setting k=1 retrieves the most relevant slide to the user question.
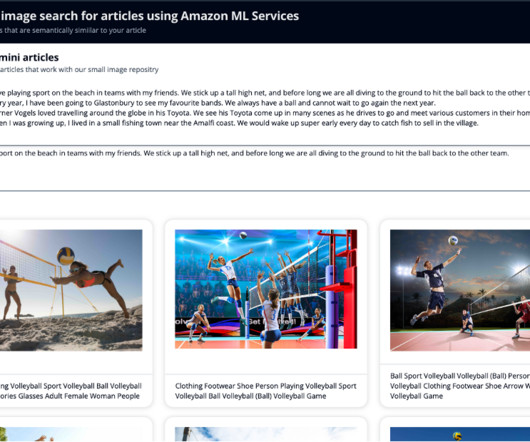
The previous post discussed how you can use Amazon machine learning (ML) services to help you find the best images to be placed along an article or TV synopsis without typing in keywords. Amazon Rekognition automatically recognizes tens of thousands of well-known personalities in images and videos using ML.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decision tree.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decision tree.
Summary Key Takeaways Citation Information Build a Search Engine: Setting Up AWS OpenSearch Were launching an exciting new series, and this time, were venturing into something new experimenting with cloud infrastructure for the first time! Learning to Rank (LTR) and Re-Ranking: Uses ML models (e.g.,
It combines information from various sources into comprehensive, on-demand summaries available in our CRM or proactively delivered based on upcoming meetings. This includes sales collateral, customer engagements, external web data, machine learning (ML) insights, and more. increase in value of opportunities created.
In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machine learning (ML). For more information about the code sample in this post, see the GitHub repo.
How to Use Machine Learning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. ML-based predictive models nowadays may consider time-dependent components — seasonality, trends, cycles, irregular components, etc. — to
Services class Texts belonging to this class consist of explicit requests for services such as room reservations, hotel bookings, dining services, cinema information, tourism-related inquiries, and similar service-oriented requests. The aim is to understand which approach is most suitable for addressing the presented challenge.
This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
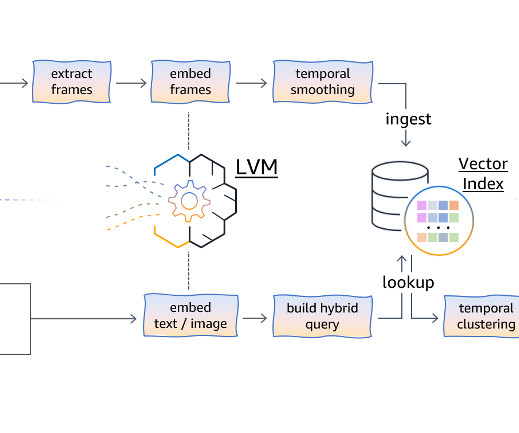
These extracted frames are then passed through an embedding module, which uses the LVM to map each frame into a high-dimensional vector representation containing its semantic information. To account for temporal dynamics and motion information present in the video, a temporal smoothing technique is applied to the frame embeddings.
Kinesis Video Streams makes it straightforward to securely stream video from connected devices to AWS for analytics, machine learning (ML), playback, and other processing. It processes and generates information from distinct data types like text and images. For more information, refer to Amazon Titan Multimodal Embeddings G1 model.
Make note of the domain Amazon Resource Name (ARN) and domain endpoint, both of which can be found in the General information section of each domain on the OpenSearch Service console. For more information, see Creating connectors for third-party ML platforms. Weve created a small knowledge base comprising population information.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. PyTorch is an open-source ML framework that accelerates the path from research prototyping to production deployment. For more information, refer to Amazon SageMaker Pricing.
ML algorithms can be broadly divided into supervised learning , unsupervised learning , and reinforcement learning. How is it actually looks in a real life process of ML investigation? In this article, I will cover all of them. Reward(1) or punishment(0).
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. In this post, we deep dive into the technical details of this ML model.
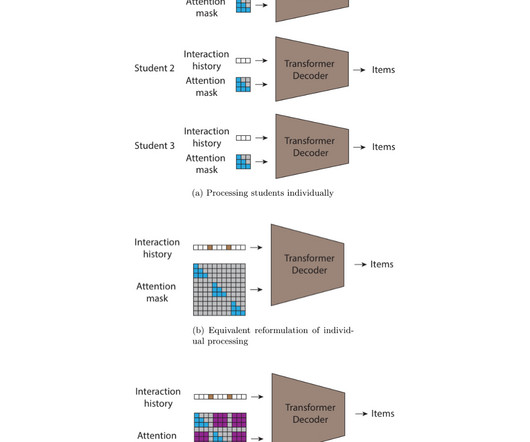
Effective recommendations that present students with relevant reading material helps keep students reading, and this is where machine learning (ML) can help. ML has been widely used in building recommender systems for various types of digital content, ranging from videos to books to e-commerce items.
The algorithm must balance exploring different arms to gather information about their expected reward, while also exploiting the knowledge it has gained to make decisions that are likely to result in high rewards. bag of words or TF-IDF vectors) and splitting the data into training and testing sets.
As Data Scientists, we all have worked on an ML classification model. In this article, we will talk about feasible techniques to deal with such a large-scale ML Classification model. In this article, you will learn: 1 What are some examples of large-scale ML classification models? Let’s take a look at some of them.
Bayesian Optimization : Use previous reviews to make informed decisions about where to look next. K-NearestNeighbors (KNN) Classifier: The KNN algorithm relies on selecting the right number of neighbors and a power parameter p. Comet ML provides a platform for test tracking and hyperparameter optimization.
Significantly, the technique allows the model to work independently by discovering its patterns and previously undetected information. It aims to partition a given dataset into K clusters, where each data point belongs to the cluster with the nearest mean. Therefore, it mainly deals with unlabelled data.
In the era of data-driven decision making, social media platforms like Twitter have become more than just channels for communication, but also a trove of information offering profound insights into human behaviors and societal trends. BECOME a WRITER at MLearning.ai // invisible ML // Detect AI img Mlearning.ai
movie titles , directors , and release years ), ensuring that search results include rich, meaningful information. Enter the URL: [link] Click Send and check if the response contains cluster health information. Powering Neural Search : Enables advanced similarity-based retrieval using OpenSearchs k-NN (k-NearestNeighbors) indexing.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. So the key problem here is, how can we efficiently identify the most informative training examples? And we’re in luck.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. So the key problem here is, how can we efficiently identify the most informative training examples? And we’re in luck.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. So the key problem here is, how can we efficiently identify the most informative training examples? And we’re in luck.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content