
Best Practices for Building ETLs for ML
KDnuggets
OCTOBER 12, 2023
This article talks about several best practices for writing ETLs for building training datasets. It delves into several software engineering techniques and patterns applied to ML.
KDnuggets
OCTOBER 12, 2023
This article talks about several best practices for writing ETLs for building training datasets. It delves into several software engineering techniques and patterns applied to ML.

databricks
MAY 1, 2023
At Databricks, we offer maximal flexibility for choosing compute for ETL and ML/AI workloads. Staying true to the theme of flexibility, we announce.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
AWS Machine Learning Blog
DECEMBER 14, 2023
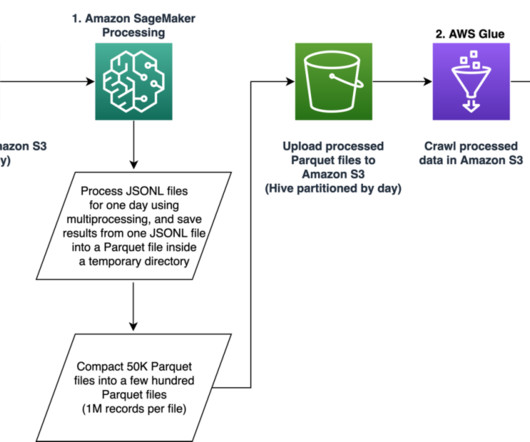
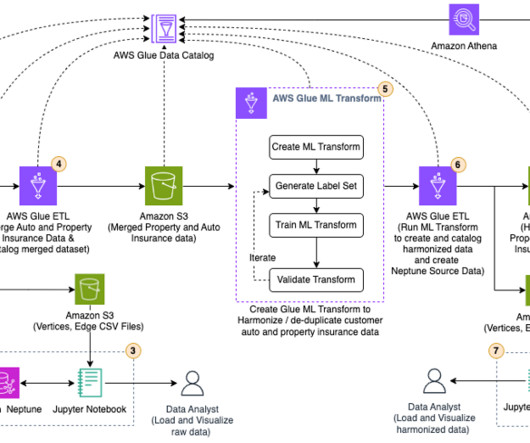
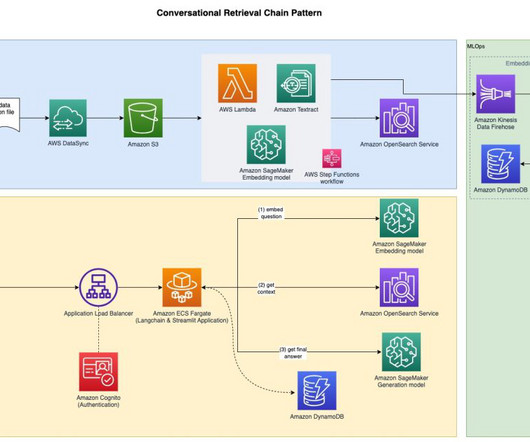
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name
KDnuggets
NOVEMBER 2, 2021
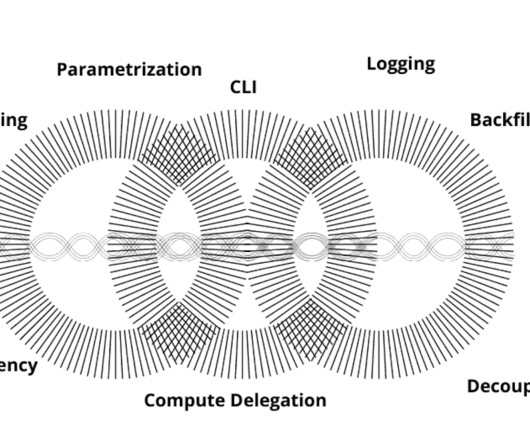
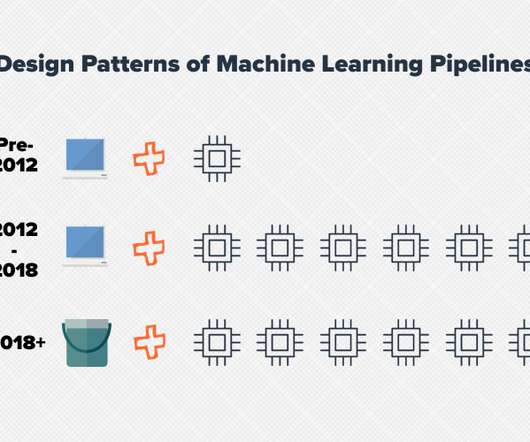
ML pipeline design has undergone several evolutions in the past decade with advances in memory and processor performance, storage systems, and the increasing scale of data sets. We describe how these design patterns changed, what processes they went through, and their future direction.

Analytics Vidhya
JANUARY 20, 2023
However, the success of ML projects is heavily dependent on the quality of data used to train models. Introduction Machine learning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. Poor data quality can lead to inaccurate predictions and poor model performance.

The MLOps Blog
MAY 17, 2023
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.

databricks
JUNE 11, 2025
It eliminates fragile ETL pipelines and complex infrastructure, enabling teams to move faster and deliver intelligent applications on a unified data platform In this blog, we propose a new architecture for OLTP databases called a lakebase. Deeply integrated with the lakehouse, Lakebase simplifies operational data workflows.

Expert insights. Personalized for you.




































Let's personalize your content