This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
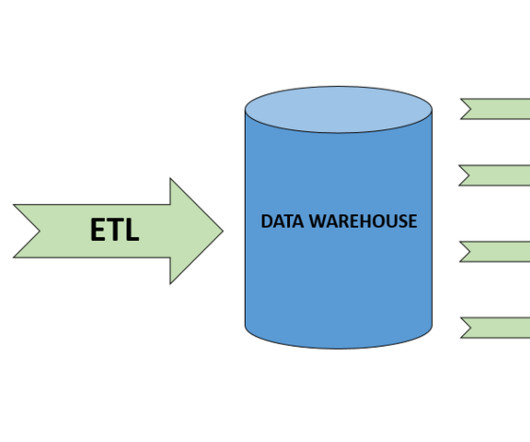
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. Thus, we use an Extract-Transform-Load (ETL) process to ingest the data.
Data pipelines are essential in our increasingly data-driven world, enabling organizations to automate the flow of information from diverse sources to analytical platforms. Users of data pipelines Different roles within organizations benefit from data pipelines, enhancing their capacity to leverage data for informed decision-making.
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (Natural Language Processing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
Structured query language (SQL) is one of the most popular programming languages, with nearly 52% of programmers using it in their work. SQL has outlasted many other programming languages due to its stability and reliability.
They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference. Previously, data scientists often found themselves juggling multiple tools to support SQL in their workflow, which hindered productivity.
Enhanced Security and Compliance Data Warehouses often store sensitive information, making security a paramount concern. This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations. So why using IaC for Cloud Data Infrastructures?
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. For more information on enabling users in IAM Identity Center, see Add users to your Identity Center directory. For IAM role , choose Create a new service role.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
Familiarise yourself with ETL processes and their significance. ETL Process: Extract, Transform, Load processes that prepare data for analysis. Can You Explain the ETL Process? The ETL process involves three main steps: Extract: Data is collected from various sources. What Is Metadata in Data Warehousing?
It’s more than just data that provides the information necessary to make wise, data-driven decisions. It Started Reverse ETL. ETL is the source of its origin. To understand how data activation is unique and where it can help your business in powerful ways, you have to start with reverse ETL. What is Data Activation?
For budding data scientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. Introduction In todays data-driven world, organizations are overwhelmed with vast amounts of information. For example, companies like Amazon use ETL tools to optimize logistics, personalize customer experiences, and drive sales.
As the volume and complexity of data continue to surge, the demand for skilled professionals who can derive meaningful insights from this wealth of information has skyrocketed. In the current landscape, data science has emerged as the lifeblood of organizations seeking to gain a competitive edge.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
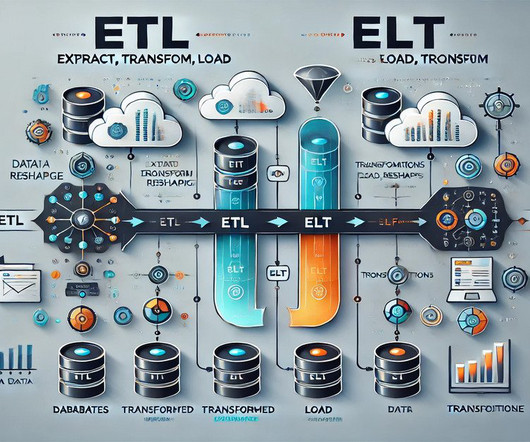
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Introduction In today’s data-driven world, efficient data processing is crucial for informed decision-making and business growth. What is ETL? ETL stands for Extract, Transform, and Load.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
The assistant is connected to internal and external systems, with the capability to query various sources such as SQL databases, Amazon CloudWatch logs, and third-party tools to check the live system health status. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
Moreover, LRRs and other industry frameworks, such as the National Institute of Standards and Technology (NIST), Information Technology Infrastructure Library (ITIL), and Control Objectives for Information and Related Technologies (COBIT), are constantly evolving.
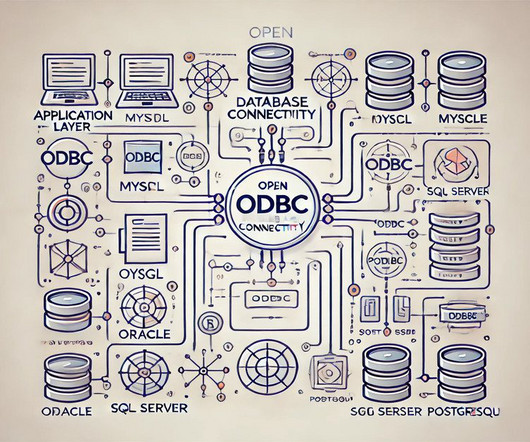
Each database type requires its specific driver, which interprets the application’s SQL queries and translates them into a format the database can understand. The driver manages the connection to the database, processes SQL commands, and retrieves the resulting data. Each database has a driver who knows how to interact with it.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning. Room for improvement!
One of Sigma’s key features is its support for custom SQL queries and CSV file uploads. In this blog, we’ll explain why custom SQL and CSVs are important, demonstrate how to use these features in Sigma Computing, and provide some best practices to help you get started.
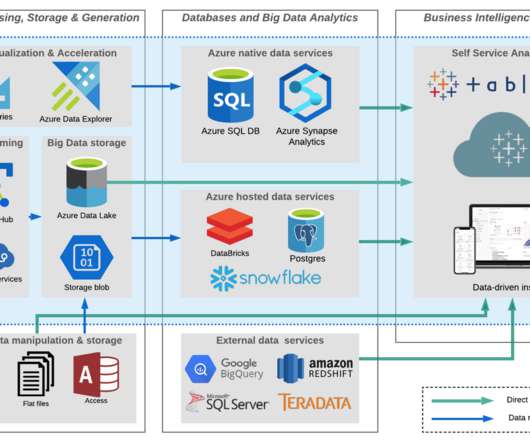
we’ve added new connectors to help our customers access more data in Azure than ever before: an Azure SQL Database connector and an Azure Data Lake Storage Gen2 connector. These insights can be ad-hoc or can inform additions to your data processing pipeline. Azure SQL Database. Kristin Adderson. March 30, 2021 - 12:07am.
Extraction, Transform, Load (ETL). Redshift is the product for data warehousing, and Athena provides SQL data analytics. Staff members can access and upload various forms of content, and management can share information across the company through news feeds. Dataform is a data transformation platform that is based on SQL.
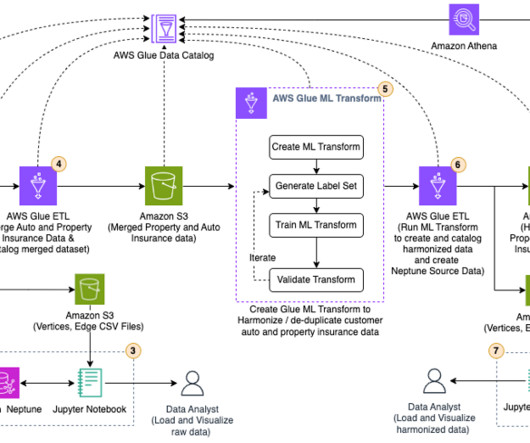
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset. Under Data classification tools, choose Record Matching.
Developers can make informed decisions based on project needs, language, and platform requirements. By exploring their features and use cases, we empower developers to make informed decisions in database management. It allows developers to easily connect to databases, execute SQL queries, and retrieve data. from 2023 to 2030.
By analyzing a wide range of data points, were able to quickly and accurately assess the risk associated with a loan, enabling us to make more informed lending decisions and get our clients the financing they need. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL.
In this blog, we explore best practices and techniques to optimize Snowflake’s performance for data vault modeling , enabling your organizations to achieve efficient data processing, accelerated query performance, and streamlined ETL workflows. This can make it nearly impossible to “handwrite” these SQL queries.
The processes of SQL, Python scripts, and web scraping libraries such as BeautifulSoup or Scrapy are used for carrying out the data collection. Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for data preparation before analysis. How to Choose the Right Data Science Career Path?
Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Python, SQL, and Apache Spark are essential for data engineering workflows. Without data engineering , companies would struggle to analyse information and make informed decisions. What Does a Data Engineer Do?
This tool is designed to connect various data sources, enterprise applications and perform analytics and ETL processes. This ETL integration software allows you to build integrations anytime and anywhere without requiring any coding. Moreover, it allows you to explore the data in SQL and view it in any analytics tool efficiently.
Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB. Data Engineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. For more information, refer to Common techniques to detect PHI and PII data using AWS Services.
In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using natural language, without the need to write SQL queries or learn a BI tool. For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training.
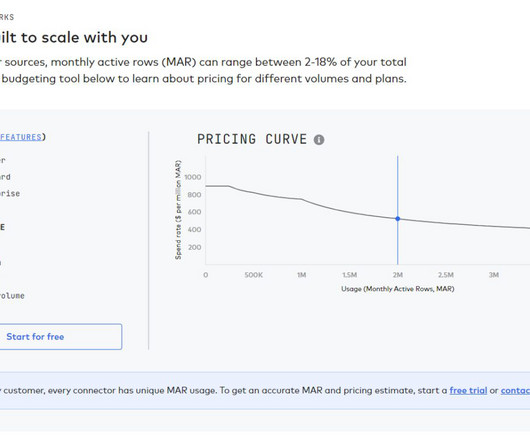
In this blog, we will explore what Fivetran is and how it works, as well as dive into its pricing structure to help you make an informed decision on whether or not Fivetran is the right platform for your data integration needs. For more information and examples of the MAR calculation, see the official documentation here.
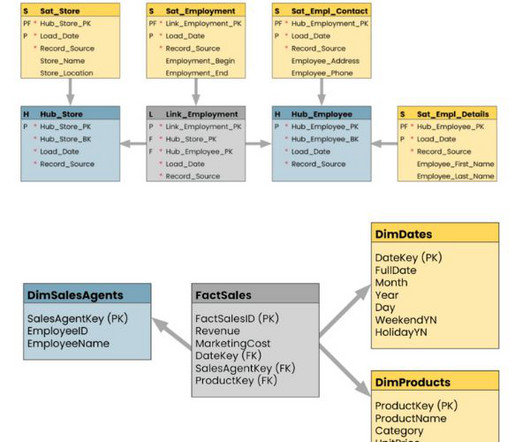
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud data warehouse like Snowflake. Its primary goal is to create a comprehensive customer data table enriched with information on States, Regions, and Consumer Categories.
People will need high-quality data to trust information and make decisions. SmartSuggestions — In Compose, Alation’s SQL editor, AI-powered suggestions actively show query writers relevant data to use as they query. The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph.
Optimized for analytical processing, it uses specialized data models to enhance query performance and is often integrated with business intelligence tools, allowing users to create reports and visualizations that inform organizational strategies. Its PostgreSQL foundation ensures compatibility with most SQL clients.
Learning about the framework of a service cloud platform is time consuming and frustrating because there is a lot of new information from many different computing fields (computer science/database, software engineering/developers, data science/scientific engineering & computing/research).
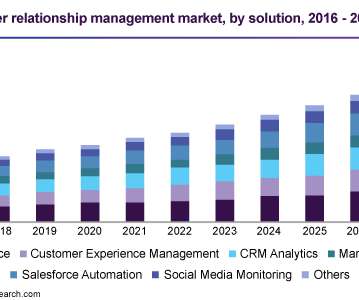
Business Intelligence (BI) refers to the technology, techniques, and practises that are used to gather, evaluate, and present information about an organisation in order to assist decision-making and generate effective administrative action. Based on the report of Zion Research, the global market of Business Intelligence rose from $16.33
Take an Inventory Taking an inventory is an important step for the following reasons; It informs the scope of a Snowflake migration. SQL Server Agent jobs). Similar to the database objects, we gather information about the volume of data being processed, the frequency of the pipelines, and the types of activities performed (e.g.
Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts. Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts. Power BI Datamarts provide no-code/low-code datamart capabilities using Azure SQL Database technology in the background.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content