This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rich Miner — Android co-founder, formerly Google Ventures, now Google — asked me recently “What if companies managed their data like they manage their money?” It’s a basic but profound question that merits some thoughts based on my 25 years managing both information and financial functions in technology and data. The post What if companies managed their data as carefully as they manage their money?
Sometimes you want to fine-tune a pre-trained model to add a new label or correct some specific errors. This can introduce the “catastrophic forgetting” problem. Pseudo-rehearsal is a good solution: use the original model to label examples, and mix them through your fine-tuning updates. The catastrophic forgetting problem occurs when you optimise two learning problems in succession, with the weights from the first problem used as part of the initialisation for the weights of the second problem.
ETL and ELT are some of the most common data engineering use cases, but can come with challenges like scaling, connectivity to other systems, and dynamically adapting to changing data sources. Airflow is specifically designed for moving and transforming data in ETL/ELT pipelines, and new features in Airflow 3.0 like assets, backfills, and event-driven scheduling make orchestrating ETL/ELT pipelines easier than ever!
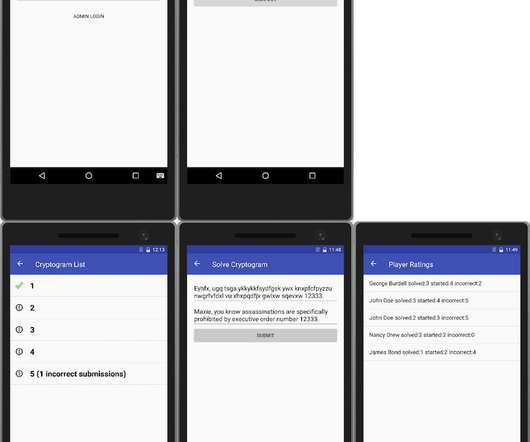
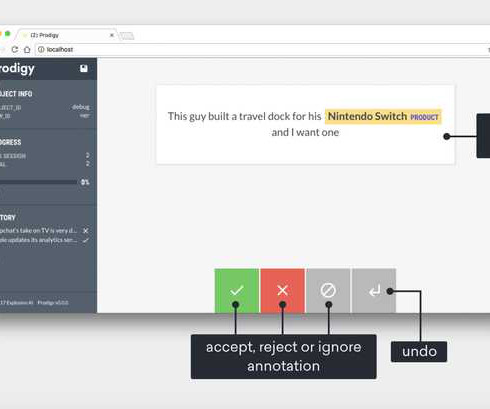
I’m excited and proud to finally share what we’ve been working on since launching Explosion AI , alongside our NLP library spaCy and our consulting projects. Prodigy is a project very dear to my heart and seeing it come to life has been one of the most exciting experiences as a software developer so far. A lot of the consulting projects we’ve worked on in the past year ended up circling back to the problem of labelling data to train custom models.
In this post, I will introduce you to something called Named Entity Recognition (NER). NER is a part of natural language processing (NLP) and information retrieval (IR). The task in NER is to find the entity-type of words.
Big data has rapidly made its way into a wide range of industries. Healthcare is ripe for big data initiatives—as one of the largest and most complex industries in the United States, there is an incredible number of potential applications for predictive analytics. While some healthcare organizations have begun to. The post 5 Ways The Healthcare Industry Could Use Big Data—and Why It’s Not appeared first on Dataconomy.
Big data has rapidly made its way into a wide range of industries. Healthcare is ripe for big data initiatives—as one of the largest and most complex industries in the United States, there is an incredible number of potential applications for predictive analytics. While some healthcare organizations have begun to. The post 5 Ways The Healthcare Industry Could Use Big Data—and Why It’s Not appeared first on Dataconomy.
Technologies in the field of data science are progressing at an exponential rate. The introduction of Machine Learning has revolutionized the world of data science by enabling computers to classify and comprehend large data sets. Another important innovation which has changed the paradigm of the world of the tech world. The post Trends Shaping Machine Learning in 2017 appeared first on Dataconomy.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
In 2016, Google’s net worth was reported to be $336 billion, and this is largely due to the advanced learning algorithms the company employs. Google was the first company to realize the importance of incorporating machine learning in business processes. And the technology powerhouse doesn’t stop at any given point; it keeps. The post Why Businesses Should Embrace Machine Learning appeared first on Dataconomy.
Just a few years ago, enterprise organizations had to be convinced that Big Data was a real-world opportunity worth investing in. By 2016, 63% of those enterprise leaders were saying they considered Big Data and advanced analytics initiatives a necessity in order to remain competitive. This year started with even. The post Steering Big Data Projects in the Modern Enterprise appeared first on Dataconomy.
Google regularly gets voted as the best company to work for in USA – its employees get generous paid holidays, free food and are even encouraged to take power naps during the work day in those ‘nap pods’. Google has been providing an excellent workplace atmosphere to its staff – The post Improving Employee Management using Big Data appeared first on Dataconomy.
The rise of financial technology and digital payment solutions is helping the world go cashless. Cashless payment methods now cover a wide range of technologies – there are physical cards, online gateways, mobile apps, and digital wallets. Blockchain-enabled payments and cryptocurrencies are also on the rise. Methods are enjoying varying. The post How blockchain is changing the way we pay appeared first on Dataconomy.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Big data and sports analytics are changing the ways many things in sports have traditionally been done. They are allowing for new processes that have the potential to alter the way that organizations conduct their scouting. This is because data science and sports analytics are opening up new data points. The post Big Data is changing the future of NBA scouting appeared first on Dataconomy.
Artificial Intelligence, Machine Learning, GDPR, Building up a Data Science Team: Trends that impact every modern organization. What is the best way to deal with these challenges and become a successful data driven organization? For the third consecutive year, Big Data Expo and GoDataDriven conduct Big Data Survey: the international benchmark. The post What makes organizations successful with data?
It’s not new news that Europe is suffering from a near-chronic skills gap. It’s been going on for a while now, with industry experts and government bodies all scratching their heads over how to solve it. The problem is about to get a whole lot worse, as the soon-to-be-enforced General. The post GDPR and the skills gap that could cost you €20million appeared first on Dataconomy.
Many marketers representing mid-market financial services companies labor under the impression that due to their size and scope, the data-driven marketing tactics used by the dominant players are simply out of reach for them. This is a shame and quite far from the truth. Data, analytics, technology and the overall. The post 5 Misconceptions About Data-Driven Financial Services Marketing appeared first on Dataconomy.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
One of the great things about running a startup is that you’re working with a clean slate. If you have worked with a different organization before, you may have had issues with culture and people that you probably don’t want happening with your own company. Existing organizations, especially the established. The post How to promote a culture of data stewardship for your startup appeared first on Dataconomy.
Linear regression is a basic tool. It works on the assumption that there exists a linear relationship between the dependent and independent variable, also known as the explanatory variables and output. However, not all problems have such a linear relationship. In fact, many of the problems we see today are. The post Performing Nonlinear Least Square and Nonlinear Regressions in R appeared first on Dataconomy.
A recent Cowen survey reveals that businesses are showing increased adoption of cloud computing. Leaders Amazon Web Services (AWS) and Microsoft Azure also continue to control majority of the public cloud market. Organizations are also looking to benefit from increased cloud adoption. Design software giant Adobe’s Q2 earnings report showed 27 percent growth.
Franz Inc., an early innovator in Artificial Intelligence (AI) and leading supplier of Semantic Graph Database technology for Knowledge Graphs, recently announced Gruff v7.0, the industry’s leading Graph Visualization software for exploring and discovering connections within data. Gruff provides novice users and graph experts the ability to visually build queries and explore.
Documents are the backbone of enterprise operations, but they are also a common source of inefficiency. From buried insights to manual handoffs, document-based workflows can quietly stall decision-making and drain resources. For large, complex organizations, legacy systems and siloed processes create friction that AI is uniquely positioned to resolve.
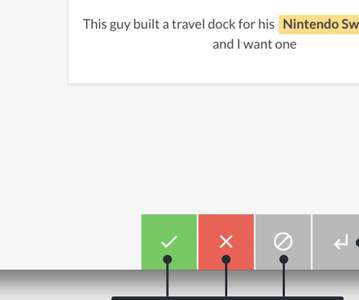
Machine learning systems are built from both code and data. It’s easy to reuse the code but hard to reuse the data, so building AI mostly means doing annotation. This is good, because the examples are how you program the behaviour – the learner itself is really just a compiler. What’s not good is the current technology for creating the examples. That’s why we’re pleased to introduce Prodigy , a downloadable tool for radically efficient machine teaching.
Sometimes you want to fine-tune a pre-trained model to add a new label or correct some specific errors. This can introduce the "catastrophic forgetting" problem. Pseudo-rehearsal is a good solution: use the original model to label examples, and mix them through your fine-tuning updates.
In this article, we will apply the concept of multi-label multi-class classification with neural networks from the last post, to classify movie posters by genre. First we import the usual suspects in python. import numpy as np import pandas as pd import glob import scipy.
Often in machine learning tasks, you have multiple possible labels for one sample that are not mutually exclusive. This is called a multi-class, multi-label classification problem. Obvious suspects are image classification and text classification, where a document can have multiple topics.
Speaker: Chris Townsend, VP of Product Marketing, Wellspring
Over the past decade, companies have embraced innovation with enthusiasm—Chief Innovation Officers have been hired, and in-house incubators, accelerators, and co-creation labs have been launched. CEOs have spoken with passion about “making everyone an innovator” and the need “to disrupt our own business.” But after years of experimentation, senior leaders are asking: Is this still just an experiment, or are we in it for the long haul?
Machine learning systems are built from both code and data. It's easy to reuse the code but hard to reuse the data, so building AI mostly means doing annotation. This is good, because the examples are how you program the behaviour – the learner itself is really just a compiler. What's not good is the current technology for creating the examples. That's why we're pleased to introduce Prodigy, a downloadable tool for radically efficient machine teaching.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content