This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Every time I surf the internet, I come across a new mind-blowing advancement in AI. The times were living in feels straight out of a sci-fi movie! So, whats on the table today? Well, in a recent interview, NVIDIA CEO Jensen Huang shared his bold vision for the future of computing, robotics, and AI. His […] The post 8 Future Predictions from Jensen Huang that Sound Like Sci-Fi appeared first on Analytics Vidhya.
*Primary Contributors Attention is a key part of the transformer architecture. It is a sequence-to-sequence mapping that transforms each sequence element into a weighted sum of values. The weights are typically obtained as the softmax of dot products between keys and queries. Recent work has explored alternatives to softmax attention in transformers, such as ReLU and sigmoid activations.
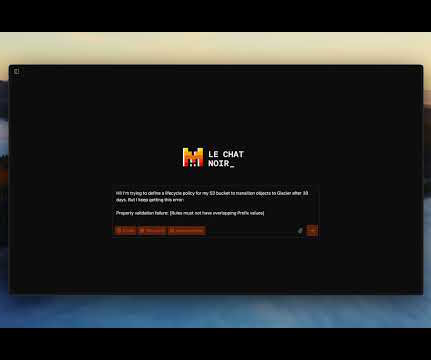
The AI assistant space is getting crowded like a Reddit thread during breaking news. From ChatGPT, Claude to Qwen and DeepSeek – the options are neverending. And here I am – giving you another addition to your AI toolkit – Mistral’s Le Chat. In this article, I will be discussing all about this new AI […] The post 10 Tasks Mistrals Le Chat Handles Better Than Any Other AI appeared first on Analytics Vidhya.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
In a new essay on his personal blog, OpenAI CEO Sam Altman said the company is open to a compute budget, among other strange-sounding ideas, to enable everyone on Earth to use a lot of AI and ensure the benefits of the technology are widely distributed.
Yes, some work will be replaced, but new jobs will be discovered in emerging industries. A recent meme captures the gnawing artificial-intelligence backlash: A worker says, AI turns this single bullet point into a long email I can pretend I wrote.
Yes, some work will be replaced, but new jobs will be discovered in emerging industries. A recent meme captures the gnawing artificial-intelligence backlash: A worker says, AI turns this single bullet point into a long email I can pretend I wrote.
An Open Letter To JD Vance From A Former CIA Officer On The Counterintelligence Risks Of Smartwatches Mr. Vice President, Congratulations on your ascendancy to the Vice President of the United States of America. While we are an apolitical platform, we wish you nothing but success, the country depends on you.
Looking at AI-generated art shows that machines may never truly understand the human mind, because there are states of mind that can never be automated.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
There's a new race in space, but it's not where you might think. It's happening close to home in the nearest bit of space, right on the edge of Earth's atmosphere.
Working with artificial intelligence can sometimes feel more like an art than a science. That's why many companies are turning to consulting firms for guidance on how to maximize the technology.
One indicator of flu activity is the percentage of doctors office visits driven by flu-like symptoms. Last week, that number was clearly higher than the peak of any winter flu season since 2009-2010.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Can you tell the difference between a poem written by a human and one crafted by AI? New research suggests most people cantand surprisingly, they even prefer AI-generated poetry for its rhythm and beauty.
The writing is on the wall. AI will replace many more jobs this year. Experts predict that AI will replace full-time careers in 2025reducing the number of jobs and creating a greater reliance on gig employment and freelancers.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Here are five things in business tech news that happened this week and how they affect your business.Did you miss them? Business Tech News #1 OpenAI launches new AI tool to facilitate research tasks.
ChatGPTs new Operator mode is its first step towards becoming an AI agent a new type of AI tool that carries out far more complex tasks without the need for human intervention. But what exactly can it do?
Documents are the backbone of enterprise operations, but they are also a common source of inefficiency. From buried insights to manual handoffs, document-based workflows can quietly stall decision-making and drain resources. For large, complex organizations, legacy systems and siloed processes create friction that AI is uniquely positioned to resolve.
Last Updated on February 10, 2025 by Editorial Team Author(s): Harshit Dawar Originally published on Towards AI. Lets understand the most useful linear feature scaling techniques of Machine Learning (ML) in detail! This member-only story is on us. Upgrade to access all of Medium. Source: Image by NIR HIMI on Unsplash Machine Learning (ML) is a very vast field & requires a proper approach to formulate the solution for every problem, irrespective of the solution or problem being small scale or
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content