This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
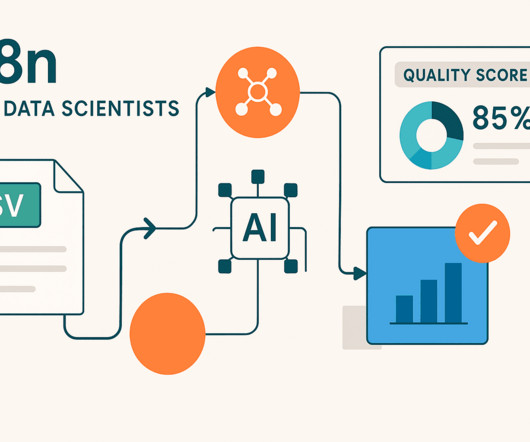
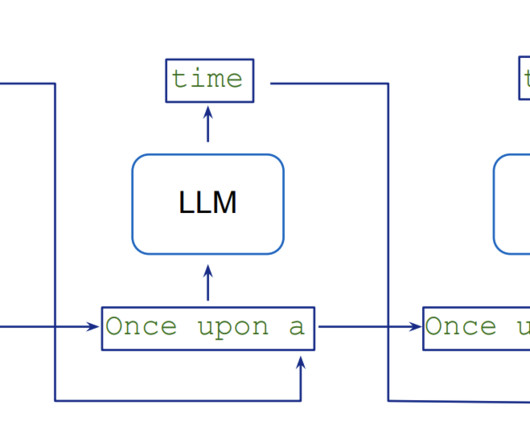
In this article, Ill walk you through creating a pipeline that processes e-commerce transactions. Well grab data from a CSV file (like youd download from an e-commerce platform), clean it up, and store it in a proper database for analysis. Nothing fancy, just practical code that gets the job done.
Download and configure the 1.78-bit Ollama is a lightweight server for running large language models locally. Install it on an Ubuntu distribution using the following commands: apt-get update apt-get install pciutils -y curl -fsSL [link] | sh Step 2: Download and Run the Model Run the 1.78-bit
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Get the FREE ebook The Great Big NaturalLanguageProcessing Primer and The Complete Collection of Data Science Cheat Sheets along with the leading newsletter on Data Science, Machine Learning, AI & Analytics straight to your inbox.
After Kaggle, this is one of the best sources for free datasets to download and enhance your data science portfolio. It is ideal for data science projects, machine learning experiments, and anyone who wants to work with real-world data. By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: No, thanks!
Google’s Python Class Platform: Google for Education Level: Intermediate Why Take It: A hands-on course with downloadable lecture notes and exercises created by Google engineers. Computer science foundations: Algorithms, data structures, and how they apply in Python. #
We will also set environment variables to optimize model downloads and inference performance. To avoid repeated downloads and speed up cold starts, create two Modal Volumes. 🎉 View Deployment: [link] After deployment, the server will begin downloading the model weights and loading them onto the GPUs. and all required packages.
The PDF I’m using is publicly accessible, and you can download it using the link. Show extracted image metadata") choice = input("Enter the number of your choice: ").strip() strip() if choice not in {1, 2, 3, 4, 5, 6, 7, 8}: print("❌ Invalid option.") return file_path = input("Enter the path to your PDF file: ").strip() page_content[:500], ".")
To install Node.js, download it from nodejs.org To install pnpm, run the following command: npm install -g pnpm Step 3: Set Up Environment Variables cp.env.example.env Edit the.env file to include your OpenAI / Anthropic /OpenRouter API key and, optionally, your GitHub personal access token. and pnpm installed globally.
It has been used as a take-home assignment in the recruitment process for the data science position at Walmart. Here is the link to this data project: [link] Visit, download the dataset, and upload it to ChatGPT. Data Exploration with LLMs Consider this data project: Black Friday purchases.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Get the FREE ebook The Great Big NaturalLanguageProcessing Primer and The Complete Collection of Data Science Cheat Sheets along with the leading newsletter on Data Science, Machine Learning, AI & Analytics straight to your inbox.
Download the data and store it somewhere for now. . # Machine Learning Pipeline with Google Cloud Platform To build our machine learning pipeline, we will need an example dataset. We will use the Heart Attack Prediction dataset from Kaggle for this tutorial. To do that, we must create a storage bucket for our dataset.
Downloading files for months until your desktop or downloads folder becomes an archaeological dig site of documents, images, and videos. What to build : Create a script that monitors a folder (like your Downloads directory) and automatically sorts files into appropriate subfolders based on their type. Let’s get started.
While chatbots are almost as pervasive as new app downloads for mobile phones, the applications of AI realizing automation and productivity gains line up with the unique purpose and architecture of the underlying AI system they are built on. The analysis also applied sentiment analysis to classify words as positive, negative, or neutral.
The creator keeps it super simple: you install Python, clone a lightweight web UI repo, download the model checkpoint, and run a local server. This project does exactly that. In this video, you’ll learn how to set up Stable Diffusion on your own computer.
The Challenge Legal texts are uniquely challenging for naturallanguageprocessing (NLP) due to their specialized vocabulary, intricate syntax, and the critical importance of context. Terms that appear similar in general language can have vastly different meanings in legal contexts. features['label'].namesnum_labels
Business challenge Today, many developers use AI and machine learning (ML) models to tackle a variety of business cases, from smart identification and naturallanguageprocessing (NLP) to AI assistants. This structure ensures that the YOLO API correctly loads and processes the images and labels during the training phase.
app downloads, DeepSeek is growing in popularity with each passing hour. DeepSeek AI is an advanced AI genomics platform that allows experts to solve complex problems using cutting-edge deep learning, neural networks, and naturallanguageprocessing (NLP). With numbers estimating 46 million users and 2.6M
Today, we’re exploring an awesome tool called SaveTWT that solves a common challenge: how to download video from Twitter. But we’ll go beyond just the “how-to” we’ll also discover exciting ways machine learning enthusiasts can use these downloaded videos for cool projects.
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. Recall@5 is a specific metric used in information retrieval evaluation, including in the BEIR benchmark. jpg") or doc.endswith(".png"))
Large language models (LLMs) have transformed naturallanguageprocessing (NLP), yet converting conversational queries into structured data analysis remains complex. Amazon Bedrock Knowledge Bases enables direct naturallanguage interactions with structured data sources.
Complete the following steps: Download the CloudFormation template and deploy it in the source Region ( us-east-1 ). Download the CloudFormation template to deploy a sample Lambda and CloudWatch log group. For this example, we create a bot named BookHotel in the source Region ( us-east-1 ).
Complete the following steps for manual deployment: Download these assets directly from the GitHub repository. Deploy the infrastructure Although this demonstrates using a CloudFormation template for quick deployment, you can also set up the components manually. The assets (JavaScript and CSS files) are available in our GitHub repository.
Although rapid generative AI advancements are revolutionizing organizational naturallanguageprocessing tasks, developers and data scientists face significant challenges customizing these large models. Download the SQuaD dataset and upload it to SageMaker Lakehouse by following the steps in Uploading data.
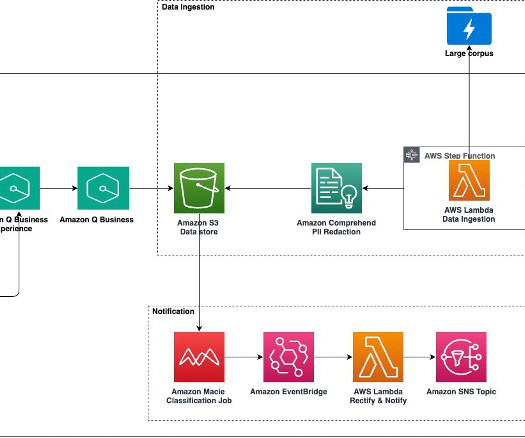
The Process Data Lambda function redacts sensitive data through Amazon Comprehend. Amazon Comprehend provides real-time APIs, such as DetectPiiEntities and DetectEntities , which use naturallanguageprocessing (NLP) machine learning (ML) models to identify text portions for redaction.
By understanding its significance, readers can grasp how it empowers advancements in AI and contributes to cutting-edge innovation in naturallanguageprocessing. Dataset Size and Format The Pile dataset comprises over 800GB of text data, making it one of the largest publicly available datasets for naturallanguageprocessing.
The integration of modern naturallanguageprocessing (NLP) and LLM technologies enhances metadata accuracy, enabling more precise search functionality and streamlined document management. When processing is triggered, endpoints are automatically initialized and model artifacts are downloaded from Amazon S3.
Using Open source Large Language Models Open source large language models (LLMs) form the foundation of offline AI systems. These models, such as Llama or Small LM2 , are freely available and highly versatile, supporting tasks like naturallanguageprocessing, content generation, and more.
Today, we’re diving into something super practical that will help you gather data for your ML projects – how to download video from YouTube easily and efficiently! Y2Mate is the fastest YouTube downloader tool available, working like a well-optimized algorithm to convert and download videos in record time!
For each email, we want to find the following: Customer name Shipment ID Email language Email sentiment Shipment delay (in days) Summary of issue Suggested response Complete the following steps: Upload input emails as.txt files. You can download sample emails from GitHub. When the IDP pipeline is complete, you will see the results.
SageMaker downloads the training image from Amazon Elastic Container Registry (Amazon ECR) and will use Amazon Simple Storage Service (Amazon S3) as an input training data source and to store training artifacts. This type of dataset is ideal for extracting meaningful information from customer reviews.
Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing. This is widely used in NaturalLanguageProcessing (NLP), where it plays a pivotal role in pre-processing unstructured textual data.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing with their ability to understand and generate humanlike text. His experience extends across different areas, including naturallanguageprocessing, generative AI and machine learning operations.
Can machines understand human language? These questions are addressed by the field of NaturalLanguageprocessing, which allows machines to mimic human comprehension and usage of naturallanguage. Last Updated on March 3, 2025 by Editorial Team Author(s): SHARON ZACHARIA Originally published on Towards AI.
This method is generally much faster, with the model typically downloading in just a couple of minutes from Amazon S3. However, this method tends to be slower and can take significantly longer to download the model compared to using Amazon S3. In his free time, he enjoys playing chess and traveling. You can find Pranav on LinkedIn.
PDF download: Downloads the PDF file from S3. Image processing: Saves the images locally and uploads them back to S3. The code snippet that follows provides a sample of the code used to extract the images from the PDF file and save them back to S3. Local path set up: Defines local paths for storing the PDF and extracted images.
To install Cursor, just go to www.cursor.com, download the version that is compatible with your OS, follow the installation instructions, and you will be set up in seconds. Then create a folder named “Sentiment Analysis Project” and move the downloaded train.csv file into it. Finally, create an empty file named app.py.
We download the documents and store them under a samples folder locally. Generate metadata Using naturallanguageprocessing, you can generate metadata for the paper to aid in searchability. Load data We use example research papers from arXiv to demonstrate the capability outlined here.
Before you begin, you can deploy this solution by downloading the required files and following the instructions in its corresponding GitHub repository. Add policy permissions to the IAM role. Request access to Amazon Titan and Anthropics Claude 3 Haiku models in Amazon Bedrock.
SageMaker Canvas supports multiple ML modalities and problem types, catering to a wide range of use cases based on data types, such as tabular data (our focus in this post), computer vision, naturallanguageprocessing, and document analysis. To download a copy of this dataset, visit.
As organizations look to incorporate AI capabilities into their applications, large language models (LLMs) have emerged as powerful tools for naturallanguageprocessing tasks. To improve startup times, SageMaker AI supports use of uncompressed files. This removes the need to untar large files.
It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. His research interests are in the area of naturallanguageprocessing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering.
In terms of how Hugging Face's Sheets compares to other AI products, ChatGPT can also be prompted in naturallanguage to generate spreadsheets, which users can copy and paste or turn into downloadable files. Claude, meanwhile, can't generate spreadsheets on its own, but it can be integrated into Google Sheets.
Download the provided CloudFormation template , then complete the following steps to deploy the stack: Open the AWS CloudFormation console (the preferred AWS Regions are us-west-2 or us-east-1 for the solution).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content