This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Josep Ferrer , KDnuggets AI Content Specialist on June 10, 2025 in Python Image by Author DuckDB is a fast, in-process analytical database designed for modern data analysis. As understanding how to deal with data is becoming more important, today I want to show you how to build a Python workflow with DuckDB and explore its key features.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming PythonSQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
By Nate Rosidi , KDnuggets Market Trends & SQL Content Specialist on June 11, 2025 in Language Models Image by Author | Canva If you work in a data-related field, you should update yourself regularly. Instead of generating answers from parameters, the RAG can collect relevant information from the document. What is a retriever?
py # (Optional) to mark directory as Python package You can leave the __init.py__ file empty, as its main purpose is simply to indicate that this directory should be treated as a Python package. Tools Required(requirements.txt) The necessary libraries required are: PyPDF : A pure Python library to read and write PDF files.
Introduction Elasticsearch is primarily a document-based NoSQL database, meaning developers do not need any prior knowledge of SQL to use it. The post Introduction to Elasticsearch using Python appeared first on Analytics Vidhya. Still, it is much more than just a NoSQL database.
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on June 9, 2025 in Python Image by Author | Ideogram Have you ever spent several hours on repetitive tasks that leave you feeling bored and… unproductive? But you can automate most of this boring stuff with Python. I totally get it. Let’s get started.
Python is a powerful and versatile programming language that has become increasingly popular in the field of data science. NumPy NumPy is a fundamental package for scientific computing in Python. Seaborn Seaborn is a library for creating attractive and informative statistical graphics in Python.
Run it once to generate the model file: python model/train_model.py More On This Topic FastAPI Tutorial: Build APIs with Python in Minutes Build a Data Cleaning & Validation Pipeline in Under 50 Lines of Python Top 5 Machine Learning APIs Practitioners Should Know 5 Machine Learning Models Explained in 5 Minutes 3 APIs to Access Gemini 2.5
Follow the installation process outlined in the documentation, and you will see a new tab in your Jupyter Notebook labeled Nbextensions. By using Python code, we can generate an interactive visualization that enables users to engage in a more intuitive data exploration process. We can see an example of Jupyter Widgets below.
Step 4: Leverage NotebookLM’s Tools Audio Overview This feature converts your document, slides, or PDFs into a dynamic, podcast-style conversation with two AI hosts that summarize and connect key points. Study Guides & Briefing Docs In the “Studio” panel, you can generate structured outputs such as study guides or briefing documents.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming PythonSQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 10 FREE AI Tools That’ll Save You 10+ Hours a Week No tech skills needed.
With Modal, you can configure your Python app, including system requirements like GPUs, Docker images, and Python dependencies, and then deploy it to the cloud with a single command. First, install the Modal Python client. file and add the following code for: Defining a vLLM image based on Debian Slim, with Python 3.12
Traditional methods of understanding code structures involve reading through numerous files and documentation, which can be time-consuming and error-prone. GitDiagram offers a solution by converting GitHub repositories into interactive diagrams, providing a visual representation of the codebases architecture.
Introduction MongoDB is a free open-source No-SQLdocument database. ArticleVideo Book This article was published as a part of the Data Science Blogathon. The post How To Create An Aggregation Pipeline In MongoDB appeared first on Analytics Vidhya.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
Cursor AI If you use Cursor for coding or editing, integrating multiple MCP servers has become essential for boosting its capabilities—giving you easy access to the web, databases, documentation, APIs, and external services. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
Python is a powerful and versatile programming language that has become increasingly popular in the field of data science. NumPy NumPy is a fundamental package for scientific computing in Python. Seaborn Seaborn is a library for creating attractive and informative statistical graphics in Python.
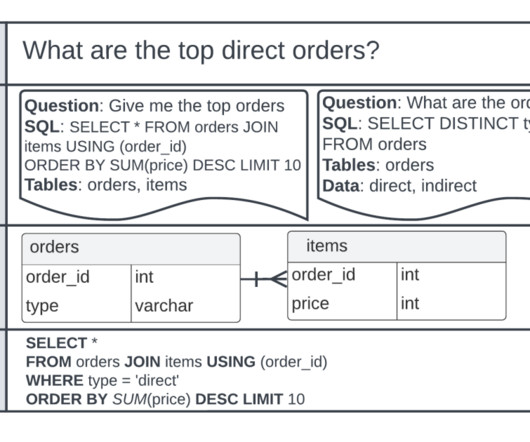
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. This can be overwhelming for nontechnical users who lack proficiency in SQL. This application allows users to ask questions in natural language and then generates a SQL query for the users request.
PDF Data Extraction: Upload a document, highlight the fields you need, and Magical AI will transfer them into online forms or databases, saving you hours of tedious work. You can find detailed step-by-step for many different workflows in Magical AIs own documentation. It even learns your tone over time.
Documentation and Disaster Recovery Made Easy Data is the lifeblood of any organization, and losing it can be catastrophic. using for loops in Python). The following Terraform script will create an Azure Resource Group, a SQL Server, and a SQL Database. So why using IaC for Cloud Data Infrastructures?
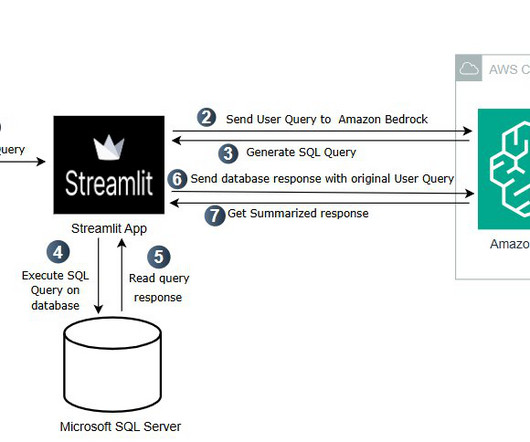
Streamlit is an open source framework for data scientists to efficiently create interactive web-based data applications in pure Python. Solution overview This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base.
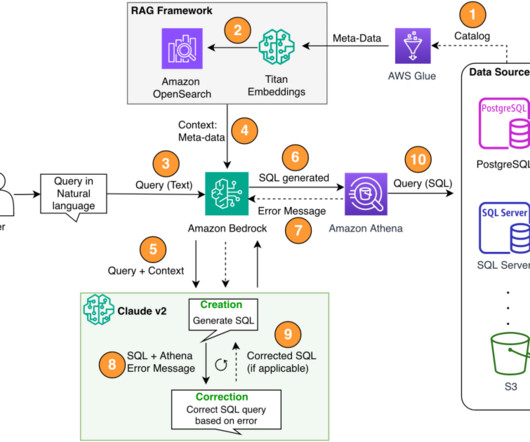
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL.
The data is stored in a data lake and retrieved by SQL using Amazon Athena. The following figure shows a search query that was translated to SQL and run. Data is normally stored in databases, and can be queried using the most common query language, SQL. Constructing SQL queries from natural language isn’t a simple task.
This centralized system consolidates a wide range of data sources, including detailed reports, FAQs, and technical documents. The system integrates structured data, such as tables containing product properties and specifications, with unstructured text documents that provide in-depth product descriptions and usage guidelines.
While Python and R are popular for analysis and machine learning, SQL and database management are often overlooked. However, data is typically stored in databases and requires SQL or business intelligence tools for access. They use Structured Query Language (SQL) for managing and querying data. What is SQL?
The agent can generate SQL queries using natural language questions using a database schema DDL (data definition language for SQL) and execute them against a database instance for the database tier. The following are sample user queries: Write a Python function to validate email address syntax.
Basically, its MongoDB on Cloud, users can create an account by signing up from their official website provided below – MongoDB Atlas: Cloud Document Database | MongoDB After signing in for the very first time, just follow the steps mentioned in the below documentation to spin up a free cluster.
Evolution of data warehouses Data warehouses emerged in the 1980s, designed as structured data repositories conducive to high-performance SQL queries and ACID transactions. SQL performance tuning: On-the-fly optimization of data formats for diverse queries.
Instead, we will leverage LangChain’s SQL Agent to generate complex database queries from human text. The documents should contain data with a bunch of specifications, alongside more fluid, natural language descriptions. Analyze the content of each document using GPT to parse it into JSON objects. I’m using Python 3.11.
Whether we are analyzing IoT data streams, managing scheduled events, processing document uploads, responding to database changes, etc. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions? appeared first on Analytics Vidhya.
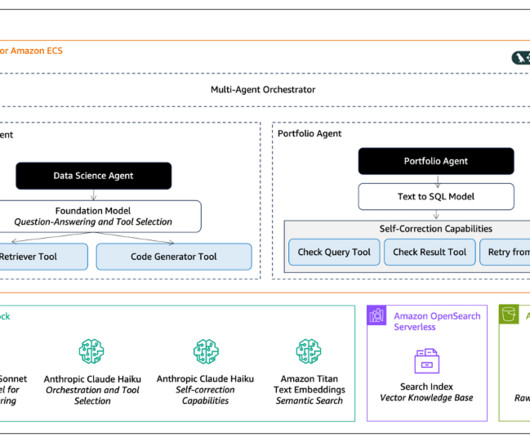
Text-to-SQL bridges this gap by generating precise, schema-specific queries that empower faster decision-making and foster a data-driven culture. We show how to effectively use Text-to-SQL using Amazon Nova , a foundation model (FM) available in Amazon Bedrock , to derive precise and reliable answers from your data.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming PythonSQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 7 Popular LLMs Explained in 7 Minutes Get a quick overview of GPT, BERT, LLaMA, and more!
It aims to boost team efficiency by answering complex technical queries across the machine learning operations (MLOps) lifecycle, drawing from a comprehensive knowledge base that includes environment documentation, AI and data science expertise, and Python code generation. Its also adept at troubleshooting coding errors.
In this post, we provide an overview of the Meta Llama 3 models available on AWS at the time of writing, and share best practices on developing Text-to-SQL use cases using Meta Llama 3 models. Meta Llama 3’s capabilities enhance accuracy and efficiency in understanding and generating SQL queries from natural language inputs.
Based on the customer query and context, the system dynamically generates text-to-SQL queries, summarizes knowledge base results using semantic search , and creates personalized vehicle brochures based on the customers preferences. This seamless process is facilitated by Retrieval Augmentation Generation (RAG) and a text-to-SQL framework.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions. To learn more, refer to API documentation.
Common Challenges in Data Ingestion Pipeline Challenge 1: Data Extraction: Parsing Complex Data Structures: Extracting data from various types of documents, such as PDFs with embedded tables or images, can be challenging. Program synthesis for symbolic reasoning, utilizing languages like Python or SQL.
Python: https://github.com/chonkie-inc/chonkie TypeScript: https://github.com/chonkie-inc/chonkie-ts Here's a video showing our code chunker: https://youtu.be/Xclkh6bU1P0. . 200k+ tokens) with many SQL snippets, query results and database metadata (e.g.
Django is a high-level open source framework written in the Python programming language. As a result of hard work, they created the world’s first website in Python and along the way developed their own framework, which they called Django, in honor of the jazz musician Django Reinhardt. Django has excellent documentation.
How to save a trained model in Python? Saving trained model with pickle The pickle module can be used to serialize and deserialize the Python objects. For saving the ML models used as a pickle file, you need to use the Pickle module that already comes with the default Python installation. Now let’s see how we can save our model.
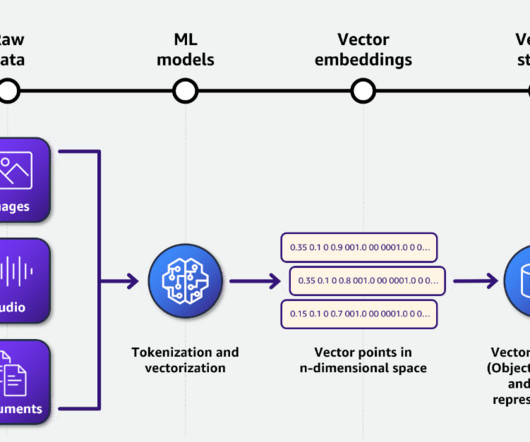
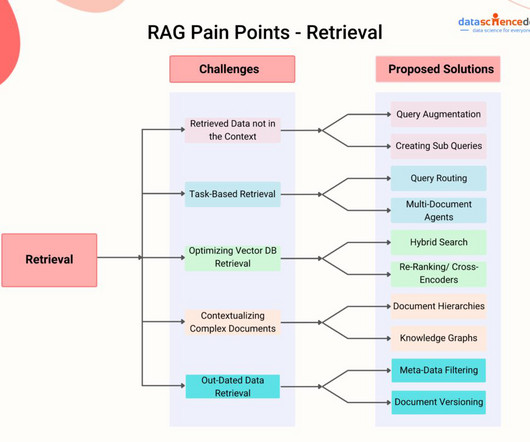
However, this also calls for the need to build processes to split large text data from various documents, which is required for RAG applications, into smaller chunks so that they can be embedded and retrieved efficiently as vectors. We can split a large document or text into smaller chunks. Return the chunks as an ARRAY.
medium instance with a Python 3 (ipykernel) kernel. For this post, we use a dataset called sql-create-context , which contains samples of natural language instructions, schema definitions and the corresponding SQL query. For details, refer to Creating an AWS account.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content