This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Managing ML projects without MLFlow is challenging. MLFlow Projects MLflow Projects enable reproducibility and portability by standardizing the structure of ML code. A project contains: Source code : The Python scripts or notebooks for training and evaluation. It supports scalability and works with popular ML libraries.
Amazon SageMaker has redesigned its Python SDK to provide a unified object-oriented interface that makes it straightforward to interact with SageMaker services. We show you how to use the ModelTrainer class to train your ML models, which includes executing distributed training using a custom script or container.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
Run it once to generate the model file: python model/train_model.py More On This Topic FastAPI Tutorial: Build APIs with Python in Minutes Build a Data Cleaning & Validation Pipeline in Under 50 Lines of Python Top 5 Machine Learning APIs Practitioners Should Know 5 Machine Learning Models Explained in 5 Minutes 3 APIs to Access Gemini 2.5
In Part 1 of this series, we introduced the newly launched ModelTrainer class on the Amazon SageMaker Python SDK and its benefits, and showed you how to fine-tune a Meta Llama 3.1 The machine learning (ML) practitioners need to iterate over these settings before finally deploying the endpoint to SageMaker for inference.
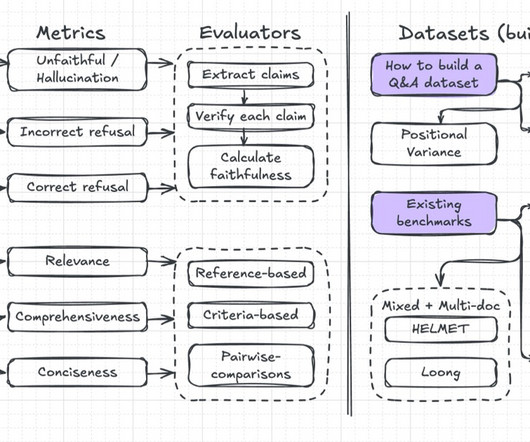
eugeneyan Start Here Writing Speaking Prototyping About Evaluating Long-Context Question & Answer Systems [ llm eval survey ] · 28 min read While evaluating Q&A systems is straightforward with short paragraphs, complexity increases as documents grow larger. Helpfulness: How relevant, comprehensive, and useful the response is for the user.
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. With SageMaker Core, managing ML workloads on SageMaker becomes simpler and more efficient. or greater is installed in the environment.
The market size for multilingual content extraction and the gathering of relevant insights from unstructured documents (such as images, forms, and receipts) for information processing is rapidly increasing. These languages might not be supported out of the box by existing document extraction software.
Snowpark ML is transforming the way that organizations implement AI solutions. Snowpark allows ML models and code to run on Snowflake warehouses. By “bringing the code to the data,” we’ve seen ML applications run anywhere from 4-100x faster than other architectures. df = session.table("BBC_ARTICLES").filter(col("CLASS")
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
For this example, we enter the following: You are an expert financial analyst with years of experience in summarizing complex financial documents. For this post, we use the following prompt: Summarize the following financial document for {{company_name}} with ticker symbol {{ticker_symbol}}: Please provide a brief summary that includes 1.
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. To learn more, refer to the API documentation. Both models support a context window of 32,000 tokens, which is roughly 50 pages of text.
Prerequisites Before diving in, you should have: Basic AI/ML understanding: concepts like language models, embeddings, and model inference. Software engineering skills: familiarity with Python, virtual environments, and package installation. Python libraries: comfort importing and using packages and file I/O.
Publish AI, ML & data-science insights to a global community of data professionals. In looking back, I often find new principles that have been accompanying me during learning ML. Luckily, in our domain, doing ML research and engineering, quick wit is not the superpower that gets you far. You want to train ML models.
You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards , making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks.
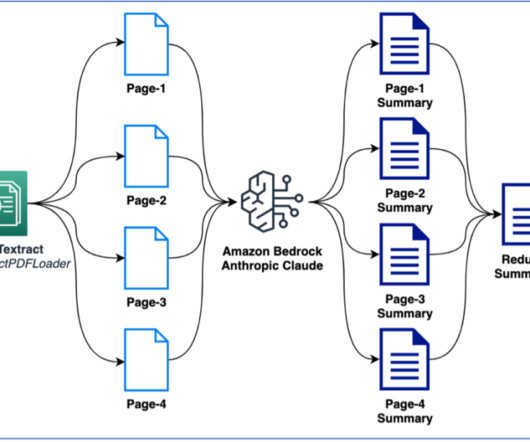
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
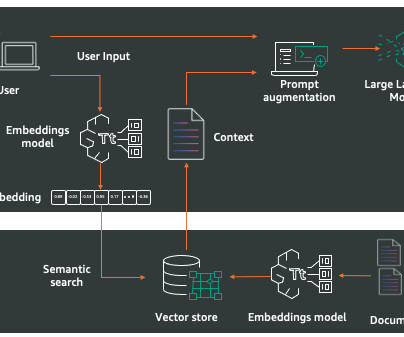
For businesses, RAG offers a powerful way to use internal knowledge by connecting company documentation to a generative AI model. When an employee asks a question, the RAG system retrieves relevant information from the company’s internal documents and uses this context to generate an accurate, company-specific response.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
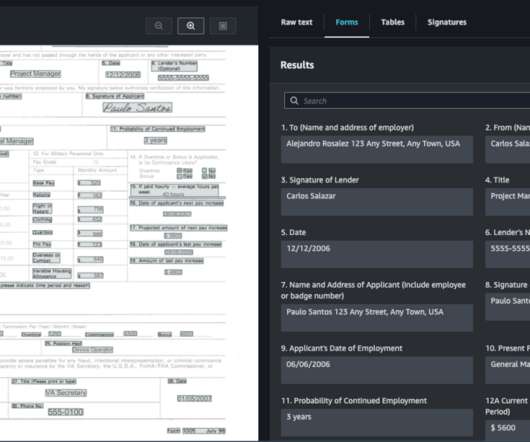
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Signatures is a feature within Amazon Textract that offers the ability to automatically detect signatures on any document.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. For a detailed walkthrough on fine-tuning the Meta Llama 3.2 Vision models.
Amazon SageMaker provides a number of options for users who are looking for a solution to host their machine learning (ML) models. For that use case, SageMaker provides SageMaker single model endpoints (SMEs), which allow you to deploy a single ML model against a logical endpoint.
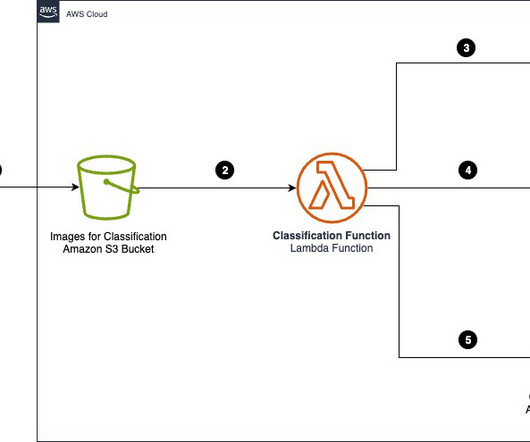
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Queries is a feature that enables you to extract specific pieces of information from varying, complex documents using natural language.
For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. What if there was a way to process documents intelligently and make them searchable in with high accuracy?
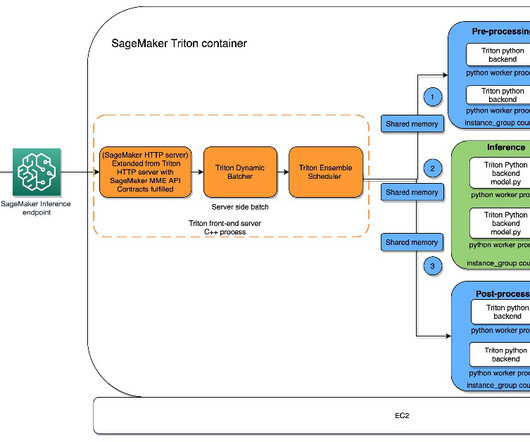
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and effortlessly build, train, and deploy machine learning (ML) models at any scale. Deploy traditional models to SageMaker endpoints In the following examples, we showcase how to use ModelBuilder to deploy traditional ML models.
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. As the global Python market is projected to reach USD 100.6
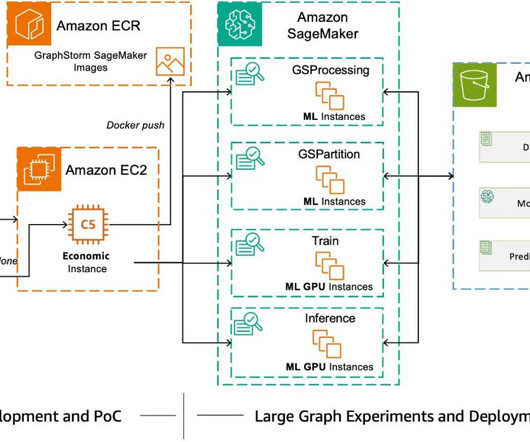
GraphStorm is a low-code enterprise graph machine learning (ML) framework that provides ML practitioners a simple way of building, training, and deploying graph ML solutions on industry-scale graph data. billion edges after adding reverse edges. seconds Evaluation Summary Total evaluations: 11 Average evaluation time: 1.90
Use cases include document summarization to help readers focus on key points of a document and transforming unstructured text into standardized formats to highlight important attributes. In the following sections, we show how to get started with document summarization by deploying Falcon 7B on SageMaker Jumpstart.
Formalizing and documenting this invaluable resource can help organizations maintain institutional memory, drive innovation, enhance decision-making processes, and accelerate onboarding for new employees. However, effectively capturing and documenting this knowledge presents significant challenges.
Today, we’re introducing the new capability to chat with your document with zero setup in Knowledge Bases for Amazon Bedrock. With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data.
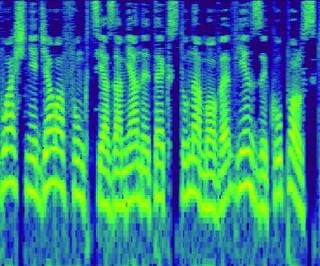
These applications are all enabled by a strong ecosystem of open-source Python packages for working with image data. In this post, we provide an overview of open-source Python packages for extracting features from speech audio data. Now that we all know a little bit about speech waveforms, back to Python!
Summary: Features of Python Programming Language is a versatile, beginner-friendly language known for its simple syntax, vast libraries, and cross-platform compatibility. With continuous updates and strong community support, Python remains a top choice for developers. Learn Python with Pickl.AI Learn Python with Pickl.AI
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machine learning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. In this post, we build a Docker image that includes the Python 3.11
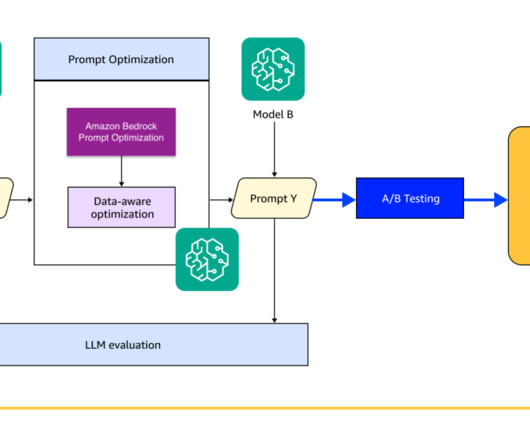
The following example shows how prompt optimization converts a typical prompt for a summarization task on Anthropics Claude Haiku into a well-structured prompt for an Amazon Nova model, with sections that begin with special markdown tags such as ## Task, ### Summarization Instructions , and ### Document to Summarize.
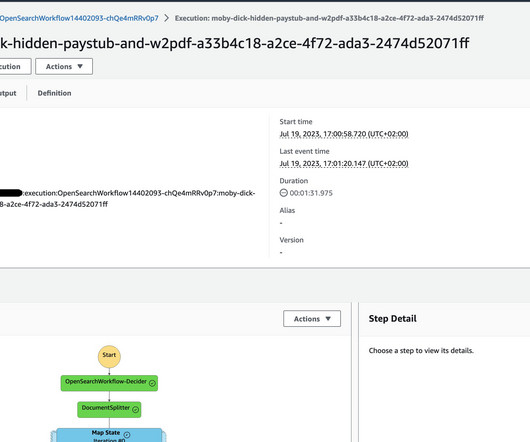
These diagrams serve as essential communication tools for stakeholders, documentation of compliance requirements, and blueprints for implementation teams. Set up your environment Before you can start creating diagrams, you need to set up your environment with Amazon Q CLI, the AWS Diagram MCP server, and AWS Documentation MCP server.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
Hugging Face Spaces is a platform for deploying and sharing machine learning (ML) applications with the community. It offers an interactive interface, enabling users to explore ML models directly in their browser without the need for local setup. app.py: This file will contain the main app logic. We recommend PyImageSearch University.
This content builds on posts such as Deploy a Slack gateway for Amazon Bedrock by adding integrations to Amazon Bedrock Knowledge Bases and Amazon Bedrock Guardrails, and the Bolt for Python library to simplify Slack message acknowledgement and authentication requirements. Chunks are vectorized and stored in a vector database.
The second approach is using SageMaker JumpStart, a machine learning (ML) hub, with foundation models (FMs), built-in algorithms, and pre-built ML solutions. This resource includes integration examples, API documentation, and programming samples. You can deploy pre-trained models using either the Amazon SageMaker console or SDK.
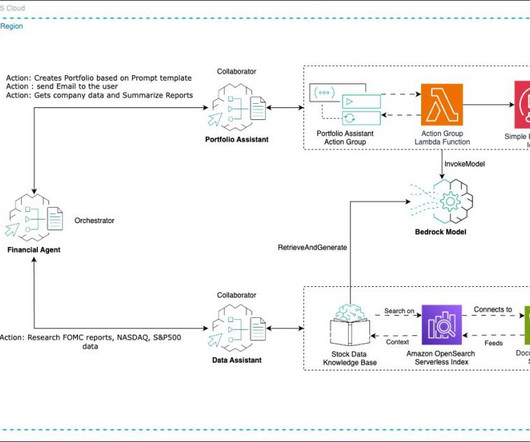
It efficiently manages the distribution of automated reports and handles stakeholder communications, providing properly formatted emails containing portfolio information and document summaries that reach their intended recipients. Note that additional documents can be incorporated to enhance your data assistant agents capabilities.
Amazon SageMaker AI provides a fully managed service for deploying these machine learning (ML) models with multiple inference options, allowing organizations to optimize for cost, latency, and throughput. In this application, we install or update a few libraries for running Llama.cpp in Python.
In this post, we dive into how organizations can use Amazon SageMaker AI , a fully managed service that allows you to build, train, and deploy ML models at scale, and can build AI agents using CrewAI, a popular agentic framework and open source models like DeepSeek-R1. Having access to a JupyterLab IDE with Python 3.9, 3.10, or 3.11
VoxelGPT offers seamless integration of natural language queries with practical Python code. Search documentation, API specifications, and tutorials : VoxelGPT provides access to the complete collection of FiftyOne documentation, assisting users in quickly finding answers to FiftyOne-related questions.
embedding NIM is optimized for multilingual and cross-lingual text question-answering retrieval with support for long documents (up to 8,192 tokens) and dynamic embedding size (Matryoshka Embeddings). reranking NIM is optimized for providing a logit score that represents how relevant a document is to a given query.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content