This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors. Enter KNearestNeighbor (k-NN), a technique that personifies the very essence of propinquity and Neighborly dynamics.
For businesses, RAG offers a powerful way to use internal knowledge by connecting company documentation to a generative AI model. When an employee asks a question, the RAG system retrieves relevant information from the company’s internal documents and uses this context to generate an accurate, company-specific response.
In this tutorial, well explore how OpenSearch performs k-NN (k-NearestNeighbor) search on embeddings. Beyond Keyword Matching) Traditional keyword-based search works by matching exact words in a query to those present in indexed documents. Implement and analyze search results using Python scripts.
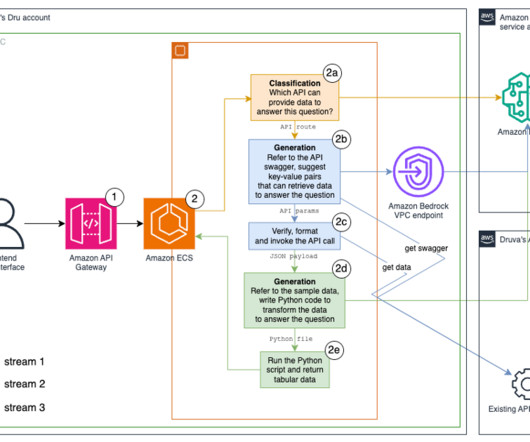
Intelligent responses and a direct conduit to Druva’s documentation – Users can gain in-depth knowledge about product features and functionalities without manual searches or watching training videos. Generate and run data transformation Python code. A custom Python function runs the Python code and returns the answer in tabular format.
We shall look at various types of machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code. In-depth Documentation- R facilitates repeatability by analyzing data using a script-based methodology.
This centralized system consolidates a wide range of data sources, including detailed reports, FAQs, and technical documents. The system integrates structured data, such as tables containing product properties and specifications, with unstructured text documents that provide in-depth product descriptions and usage guidelines.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
We shall look at various machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. In addition, it’s also adapted to many other programming languages, such as Python or SQL.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI.
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
Broadly speaking, a retriever is a module that takes a query as input and outputs relevant documents from one or more knowledge sources relevant to that query. Document ingestion In a RAG architecture, documents are often stored in a vector store. You must use the same embedding model at ingestion time and at search time.
The KNearestNeighbors (KNN) algorithm of machine learning stands out for its simplicity and effectiveness. What are KNearestNeighbors in Machine Learning? Definition of KNN Algorithm KNearestNeighbors (KNN) is a simple yet powerful machine learning algorithm for classification and regression tasks.
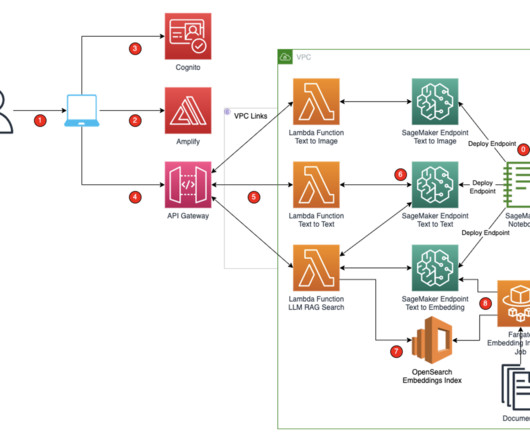
Embeddings for documents are generated using the text-to-embeddings model and these embeddings are indexed into OpenSearch Service. A k-NearestNeighbor (k-NN) index is enabled to allow searching of embeddings from the OpenSearch Service. For this post, you use the AWS Cloud Development Kit (AWS CDK) using Python.
Python is still one of the most popular programming languages that developers flock to. In this blog, we’re going to take a look at some of the top Python libraries of 2023 and see what exactly makes them tick. In this blog, we’re going to take a look at some of the top Python libraries of 2023 and see what exactly makes them tick.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
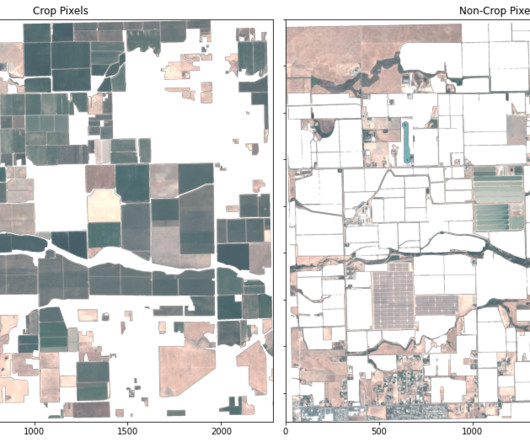
In this analysis, we use a K-nearestneighbors (KNN) model to conduct crop segmentation, and we compare these results with ground truth imagery on an agricultural region. Access Planet data To help users get accurate and actionable data faster, Planet has also developed the Planet Software Development Kit (SDK) for Python.
You will create a connector to SageMaker with Amazon Titan Text Embeddings V2 to create embeddings for a set of documents with population statistics. Python The code has been tested with Python version 3.13. Alternately, you can follow the Boto 3 documentation to make sure you use the right credentials.
In today’s blog, we will see some very interesting Python Machine Learning projects with source code. This is one of the best Machine learning projects in Python. Doctor-Patient Appointment System in Python using Flask Hey guys, in this blog we will see a Doctor-Patient Appointment System for Hospitals built in Python using Flask.
OpenSearch Service offers kNN search, which can enhance search in use cases such as product recommendations, fraud detection, and image, video, and some specific semantic scenarios like document and query similarity. Initializes the OpenSearch Service client using the Boto3 Python library. Solution overview.
Implementing this unified image and text search application consists of two phases: k-NN reference index – In this phase, you pass a set of corpus documents or product images through a CLIP model to encode them into embeddings. You save those embeddings into a k-NN index in OpenSearch Service. unsqueeze(0).to(device)
Alternatively, you can use a serverless Lambda function to extract frames of a stored video file with the Python OpenCV library. You store the embeddings of the video frame as a k-nearestneighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3).
You can reach the documentation from here. For each sample in the minority class, it selects knearestneighbors from the same class. It then selects one of these kneighbors at random and computes the difference between the feature vector of the original sample and the selected neighbor.
J Jupyter Notebook: An open-source web application that allows users to create and share documents containing live code, equations, visualisations, and narrative text. Joblib: A Python library used for lightweight pipelining in Python, handy for saving and loading large data structures.
Image classification Text categorization Document sorting Sentiment analysis Medical image diagnosis Advantages Pool-based active learning can leverage relationships between data points through techniques like density-based sampling and cluster analysis. Traditional Active Learning has the following characteristics.
These complex data formats are usually unstructured, structurally only a set of bytes in a given field, about which the user often has no reliable information due to incomplete documentation. To implement our automated download system, we used Selenium in Python to control the browser using a Firefox driver.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content