This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
It supports advanced features such as result highlighting, flexible pagination, and k-nearestneighbor (k-NN) search for vector and semantic search use cases. Lexical search relies on exact keyword matching between the query and documents. The querys encoding is then compared to pre-computed document embeddings.
Amazon Titan Text Embeddings models generate meaningful semantic representations of documents, paragraphs, and sentences. It supports exact and approximate nearest-neighbor algorithms and multiple storage and matching engines. He is focused on OpenSearch Serverless and has years of experience in networking, security and AI/ML.
In this tutorial, well explore how OpenSearch performs k-NN (k-NearestNeighbor) search on embeddings. Beyond Keyword Matching) Traditional keyword-based search works by matching exact words in a query to those present in indexed documents. It uses vector similarity (e.g.,
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. Dr. Hemant Joshi has over 20 years of industry experience building products and services with AI/ML technologies.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? This will be a good way to get familiar with ML. Types of Machine Learning for GIS 1.
Broadly speaking, a retriever is a module that takes a query as input and outputs relevant documents from one or more knowledge sources relevant to that query. Document ingestion In a RAG architecture, documents are often stored in a vector store. You must use the same embedding model at ingestion time and at search time.
For more information on managing credentials securely, see the AWS Boto3 documentation. For example: aws s3 cp /Users/username/Documents/training/loafers s3://footwear-dataset/ --recursive Confirm the upload : Go back to the S3 console, open your bucket, and verify that the images have been successfully uploaded to the bucket.
k-NearestNeighbors (k-NN) k-NN is a simple algorithm that classifies new instances based on the majority class among its knearest neighbours in the training dataset. Example: Organising documents into a tree structure based on topic similarity for better information retrieval systems.
The KNearestNeighbors (KNN) algorithm of machine learning stands out for its simplicity and effectiveness. What are KNearestNeighbors in Machine Learning? Definition of KNN Algorithm KNearestNeighbors (KNN) is a simple yet powerful machine learning algorithm for classification and regression tasks.
We shall look at various machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. In-depth Documentation- R facilitates repeatability by analyzing data using a script-based methodology.
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
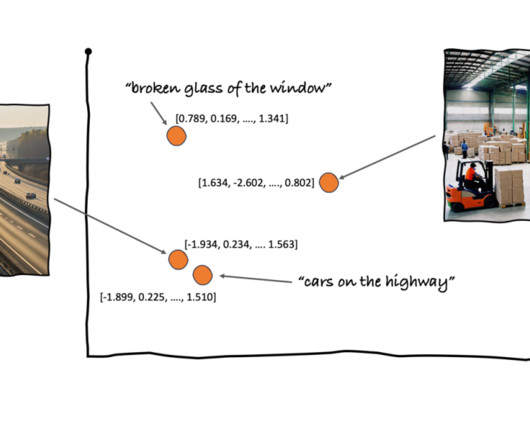
We performed a k-nearestneighbor (k-NN) search to retrieve the most relevant embedding matching the question. SlideVQA: A Dataset for Document Visual Question Answering on Multiple Images. Archana is an aspiring member of the AI/ML technical field community at AWS. 13636-13645. 10.1609/aaai.v37i11.26598.
Full-Text and Structured Search: Powers fast, scalable, and accurate search for e-commerce, enterprise search, and document retrieval systems. Semantic search improves accuracy by leveraging machine learning (ML), natural language processing (NLP), and vector search techniques to deliver more relevant, intent-driven results.
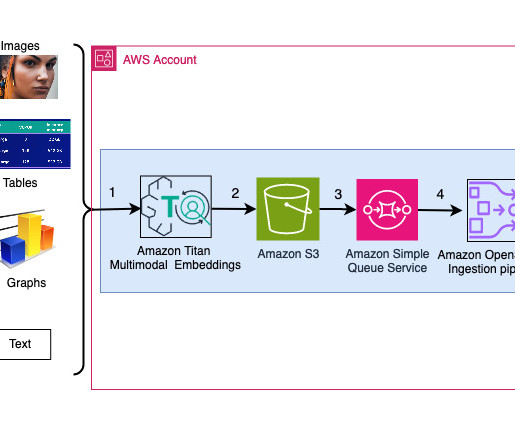
Embeddings for documents are generated using the text-to-embeddings model and these embeddings are indexed into OpenSearch Service. A k-NearestNeighbor (k-NN) index is enabled to allow searching of embeddings from the OpenSearch Service.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
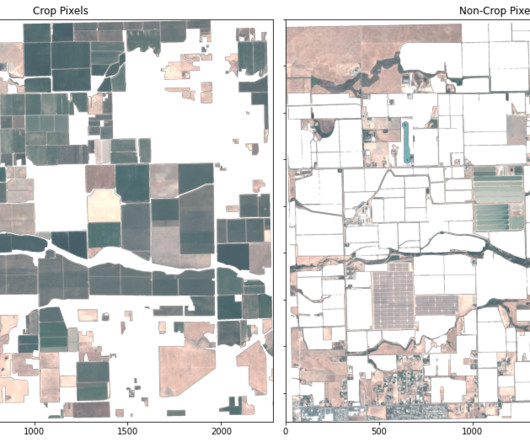
In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image. Identifying crop regions is a core step towards gaining agricultural insights, and the combination of rich geospatial data and ML can lead to insights that drive decisions and actions.
Powering Neural Search : Enables advanced similarity-based retrieval using OpenSearchs k-NN (k-NearestNeighbors) indexing. Registering the Model in OpenSearch We first register the model using OpenSearchs ML Commons API. The function in utils.py The function in utils.py The following function from utils.py
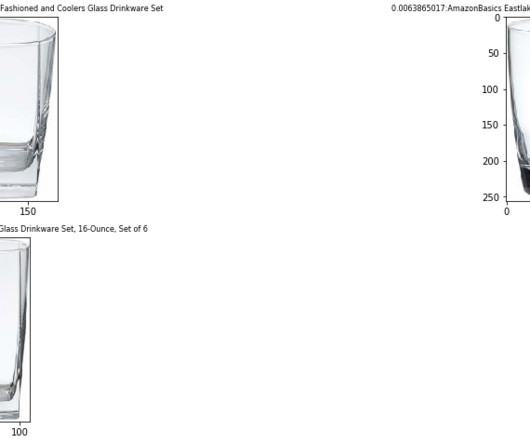
This event in the SQS queue acts as a trigger to run the OSI pipeline, which in turn ingests the data (JSON file) as documents into the OpenSearch Serverless index. We perform a k-nearestneighbor (k=1) search to retrieve the most relevant embedding matching the user query. get('hits')[0].get('_source').get('image_path')
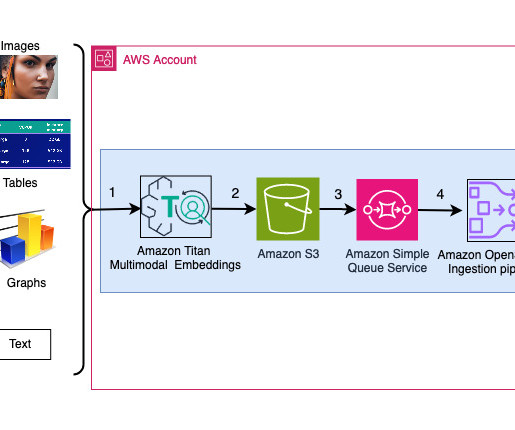
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machine learning (ML). Deploy the solution as a local web application. About the Authors.
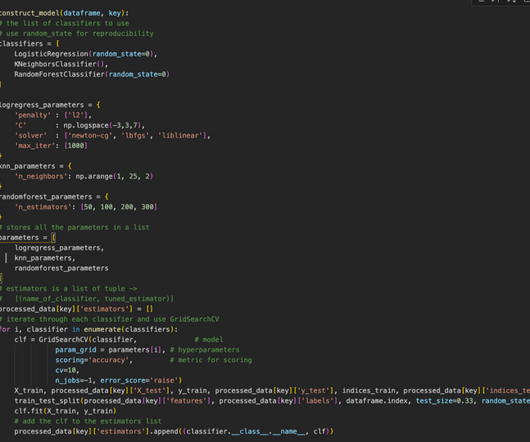
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Kinesis Video Streams makes it straightforward to securely stream video from connected devices to AWS for analytics, machine learning (ML), playback, and other processing. He is passionate about IoT, AI/ML and building smart home devices. It enables real-time video ingestion, storage, encoding, and streaming across devices.
This includes sales collateral, customer engagements, external web data, machine learning (ML) insights, and more. AI-driven recommendations – By combining generative AI with ML, we deliver intelligent suggestions for products, services, applicable use cases, and next steps.
You will create a connector to SageMaker with Amazon Titan Text Embeddings V2 to create embeddings for a set of documents with population statistics. Alternately, you can follow the Boto 3 documentation to make sure you use the right credentials. For more information, see Creating connectors for third-party ML platforms.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. You save those embeddings into a k-NN index in OpenSearch Service. PyTorch is an open-source ML framework that accelerates the path from research prototyping to production deployment.
It is easy to use, with a well-documented API and a wide range of tutorials and examples available. First, it’s easy to use, the code is easy to learn and it has a well-documented API. Scikit-learn is also open-source, which makes it a popular choice for both academic and commercial use. What really makes Django are a few things.
You can reach the documentation from here. For each sample in the minority class, it selects knearestneighbors from the same class. It then selects one of these kneighbors at random and computes the difference between the feature vector of the original sample and the selected neighbor.
Figure 5 Feature Extraction and Evaluation Because most classifiers and learning algorithms require numerical feature vectors with a fixed size rather than raw text documents with variable length, they cannot analyse the text documents in their original form. The accuracy of the ML model indicates how many times it was correct overall.
It can also be thought of as the ‘Hello World of ML world. Document Scanner using OpenCV So guys, in this blog we will see how we can build a very simple yet powerful Document scanner using OpenCV. So, In this blog, we will see how to implement it. This is one of my favorite projects because of its simplicity and its power.
Image classification Text categorization Document sorting Sentiment analysis Medical image diagnosis Advantages Pool-based active learning can leverage relationships between data points through techniques like density-based sampling and cluster analysis. Traditional Active Learning has the following characteristics.
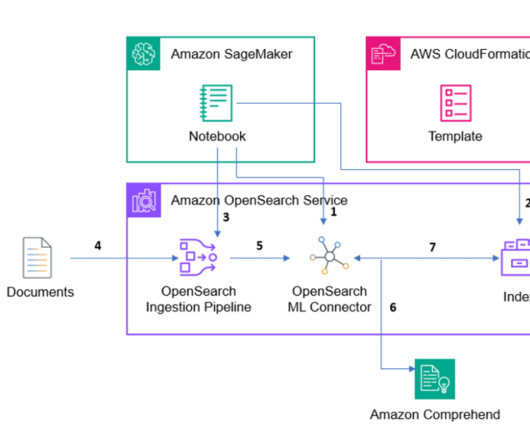
OpenSearch offers a wide range of third-party machine learning (ML) connectors to support this augmentation. This post highlights two of these third-party ML connectors. In this post, we show you how to use this connector to invoke the LangDetect API to detect the languages of ingested documents.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content