This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
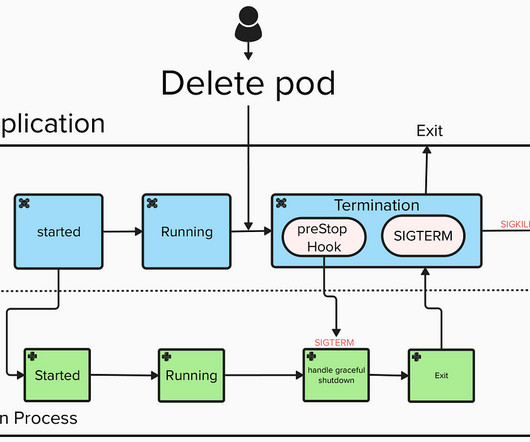
The need for handling this issue became more evident after we began implementing streaming jobs in our Apache Spark ETL platform. The system terminated the pod without warning while the Python process ran the job. Signal Handling : The Python process underneath catches this signal and handles it by raising an exception.
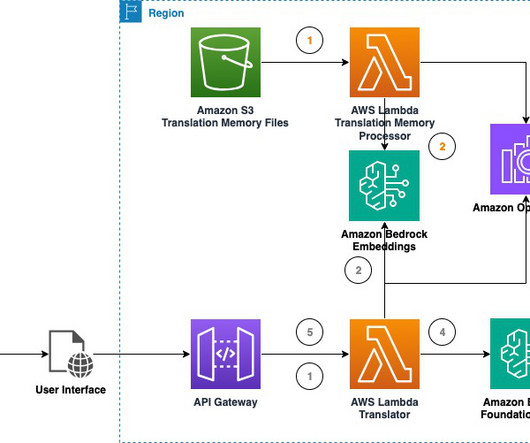
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. This is covered in detail later in the post.
Emergence of the term “data lakehouse” The term “data lakehouse” first appeared in documentation around 2017, with significant attention drawn by Databricks in 2020. Programming language support: Compatibility with programming languages like Python, Scala, and other APIs.
This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations. Documentation and Disaster Recovery Made Easy Data is the lifeblood of any organization, and losing it can be catastrophic. using for loops in Python). So why using IaC for Cloud Data Infrastructures?
To start, get to know some key terms from the demo: Snowflake: The centralized source of truth for our initial data Magic ETL: Domo’s tool for combining and preparing data tables ERP: A supplemental data source from Salesforce Geographic: A supplemental data source (i.e., Visit Snowflake API Documentation and Domo’s Cloud Amplifier Resources.
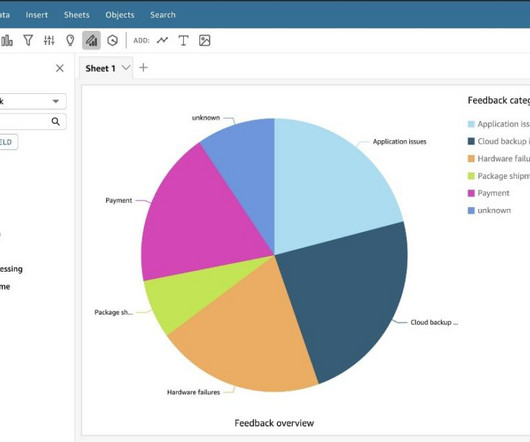
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed data engine Daft [link] is open-sourced and runs on 800k CPU cores daily. WE'RE GROWING - COME GROW WITH US!
Python: https://github.com/chonkie-inc/chonkie TypeScript: https://github.com/chonkie-inc/chonkie-ts Here's a video showing our code chunker: https://youtu.be/Xclkh6bU1P0. . Is Chonkie primarily for people looking to process documents in some sort of real-time scenario?
This solution supports the validation of adherence to existing obligations by analyzing governance documents and controls in place and mapping them to applicable LRRs. This approach enables centralized access and sharing while minimizing extract, transform and load (ETL) processes and data duplication. Furthermore, watsonx.ai
Summary: Choosing the right ETL tool is crucial for seamless data integration. At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. What is ETL?
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud data warehouse like Snowflake. Intuitive Workflow Design Workflows should be easy to follow and visually organized, much like clean, well-structured SQL or Python code.
To keep myself sane, I use Airflow to automate tasks with simple, reusable pieces of code for frequently repeated elements of projects, for example: Web scraping ETL Database management Feature building and data validation And much more! Take a quick look at the architecture diagram below, from the Airflow documentation.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. Step 1: Set up two Amazon Bedrock knowledge bases This step creates two Amazon Bedrock knowledge bases.
PowerBI, Tableau) and programming languages like R and Python in the form of bar graphs, scatter line plots, histograms, and much more. What are ETL and data pipelines? The source of extraction of data can be files like text files, excel sheets, word documents, databases like relational as well as non-relational, and also the APIs.
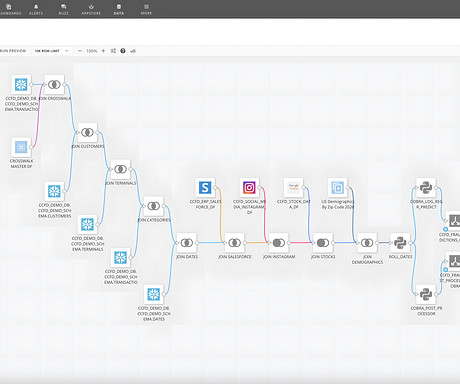
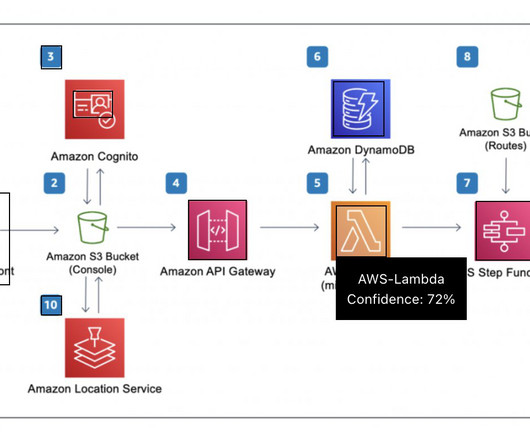
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. Using architecture diagrams as an example, the solution needs to search through reference links and technical documents for architecture diagrams and identify the services present.
Extraction, Transform, Load (ETL). Dataform enables the creation of a central repository for defining data throughout an organisation, as well as discovering datasets and documenting data in a catalogue. It allows users to organise, monitor and schedule ETL processes through the use of Python. Master data management.
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. These jobs can be run immediately or on a recurring time schedule without the need for data workers to refactor code as Python modules. Refer to SageMaker documentation for detailed instructions.
Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Python, SQL, and Apache Spark are essential for data engineering workflows. PythonPython is one of the most popular programming languages for data engineering. Start your journey with Pickl.AI
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks. Every Airflow task calls Amazon ECS tasks with some overrides.
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation.
They usually operate outside any data governance structure; often, no documentation exists outside the user’s mind. Host in SharePoint or Google Docs A simple and common option is to leave the data in a spreadsheet but host it in a document management service. This allows for easy sharing and collaboration on the data.
Documentation: Keep detailed documentation of the deployed model, including its architecture, training data, and performance metrics, so that it can be understood and managed effectively. If you aren’t aware already, let’s introduce the concept of ETL. We primarily used ETL services offered by AWS.
Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets. Usability Do interfaces and documentation enable business analysts and data scientists to leverage systems? Prioritize libraries with strong community support like Python and R.
Putting the T for Transformation in ELT (ETL) is essential to any data pipeline. In Snowflake, stored procedures can be created in normal SQL and in Javascript, Python, Java, and Scala (the latter three need to be made using the Snowpark API). Coalesce’s top features include column-level lineage and auto-generated documentation.
You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. This is necessary because additional Python modules need to be installed. Similarly, if you need to complete a Python process, you will need the Python operator.
Reverse ETL tools. The modern data stack is also the consequence of a shift in analysis workflow, fromextract, transform, load (ETL) to extract, load, transform (ELT). A Note on the Shift from ETL to ELT. In the past, data movement was defined by ETL: extract, transform, and load. Extract, load, Transform (ELT) tools.
Apache Airflow Airflow is an open-source ETL software that is very useful when paired with Snowflake. Airflow is entirely in Python, so it’s relatively easy for those with some Python experience to get started using it. Airflow uses Directed Acyclic Graphs (DAGs) to represent workflows as tasks with defined dependencies.
Additionally, a clear majority of current projects ( 85% to be exact) leverage open-source programming languages like Python and R rather than proprietary options. At the core are versatile open-source languages like Python and R that provide accessible foundations for statistical analysis and model building.
This also means that it comes with a large community and comprehensive documentation. Thanks to its various operators, it is integrated with Python, Spark, Bash, SQL, and more. Flexibility: Its use cases are wider than just machine learning; for example, we can use it to set up ETL pipelines. It is lightweight.
References : Links to internal or external documentation with background information or specific information used within the analysis presented in the notebook. You could link this section to any other piece of documentation. documentation. If a reviewer wants more detail, they can always look at the Python module directly.
Explore their features, functionalities, and best practices for creating reports, dashboards, and visualizations. Develop programming skills: Enhance your programming skills, particularly in languages commonly used in BI development such as SQL, Python, or R.
For instance, if the collected data was a text document in the form of a PDF, the data preprocessing—or preparation stage —can extract tables from this document. The pipeline in this stage can convert the document into CSV files, and you can then analyze it using a tool like Pandas.
that evolution continues with major advances in streaming, Python, SQL, and semi-structured data. Data Engineer, 84.51° What’s Next Stay tuned for more details in the Apache Spark documentation. With the recent release of Apache Spark 4.0, You can read more about the release here.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. With multiple families in plan, the first release is the Slate family of models, which represent an encoder-only architecture.
And that’s when what usually happens, happened: We came for the ML models, we stayed for the ETLs. But even when the ETLs were well thought out, they were a bit “outdated” in their approach. ETL Pipeline ETL Pipeline | Source: Author The pipeline is triggered by Eventbridge , and can be done either manually or by cron.
Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance. It’s not a widely known programming language like Java, Python, or SQL. ECL sounds compelling, but it is a new programming language and has fewer users than languages like Python or SQL.
Advanced Data Processing Capabilities KNIME provides a wide range of nodes for data extraction, transformation, and loading (ETL), but it also offers advanced data manipulation and processing capabilities. This includes machine learning , statistical modeling, and text mining, among others.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. You could almost think of Hamilton as DBT for Python functions. It gives a very opinionary way of writing Python.
In that case, ThoughtSpot also leverages ELT/ETL tools and Mode, a code-first AI-powered data solution that gives data teams everything they need to go from raw data to the modern BI stack. However, ThoughtSpot can often work around these issues using custom connectors, ETL/ELT processes, or APIs, bridging the gap between the two.
Tips When Considering Streamsets Data Collector: As a Snowflake partner, Streamsets includes very intricate documentation on using Data Collector with Snowflake, including this book you can read here. This allows users to utilize Python to customize transformations. Data Collector can use Snowflake’s native Snowpipe in its pipelines.
See the Power BI documentation. Data Processing Within KNIME’s toolkit, you’ll find an extensive array of nodes catering to data extraction, transformation, and loading (ETL). You can, however, code in Python, R, Java, JavaScript, or CSS within KNIME if you want. Execute the workflow. Check your Power BI Workspace!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content