This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In machinelearning, few ideas have managed to unify complexity the way the periodic table once did for chemistry. Now, researchers from MIT, Microsoft, and Google are attempting to do just that with I-Con, or Information Contrastive Learning. This ballroom analogy extends to all of machinelearning.
Supervisedlearning is a powerful approach within the expansive field of machinelearning that relies on labeled data to teach algorithms how to make predictions. What is supervisedlearning? Supervisedlearning refers to a subset of machinelearning techniques where algorithms learn from labeled datasets.
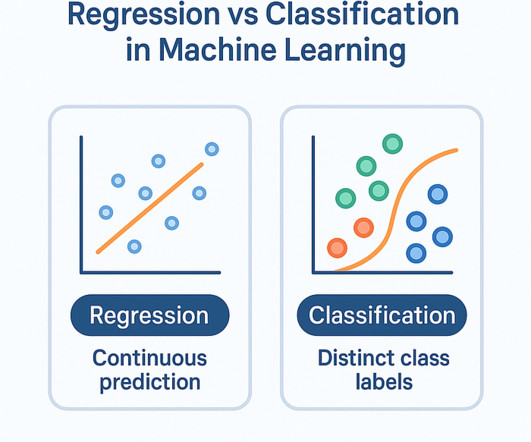
Regression vs Classification in MachineLearning Why Most Beginners Get This Wrong | M004 If youre learningMachineLearning and think supervisedlearning is straightforward, think again. Not just the textbook definitions, but the thinking process behind choosing the right type of model.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machinelearning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
A validation set is a critical element in the machinelearning process, particularly for those working within the realms of supervisedlearning. What is a validation set in machinelearning? Dataset splits in machinelearning Proper management of datasets is foundational in machinelearning.
Increasingly, FMs are completing tasks that were previously solved by supervisedlearning, which is a subset of machinelearning (ML) that involves training algorithms using a labeled dataset. An FM-driven solution can also provide rationale for outputs, whereas a traditional classifier lacks this capability.
Machinelearning is playing a very important role in improving the functionality of task management applications. However, recent advances in applying transfer learning to NLP allows us to train a custom language model in a matter of minutes on a modest GPU, using relatively small datasets,” writes author Euan Wielewski.
Welcome to this comprehensive guide on Azure MachineLearning , Microsoft’s powerful cloud-based platform that’s revolutionizing how organizations build, deploy, and manage machinelearning models. This is where Azure MachineLearning shines by democratizing access to advanced AI capabilities.
Beginner’s Guide to ML-001: Introducing the Wonderful World of MachineLearning: An Introduction Everyone is using mobile or web applications which are based on one or other machinelearning algorithms. You might be using machinelearning algorithms from everything you see on OTT or everything you shop online.
Understanding Supervised vs Unsupervised Learning: A Comparative Overview Introduction Hello dear readers, hope you’re doing just fine! (Or Or even better than that) Machinelearning has transformed the way businesses operate by automating processes, analyzing data patterns, and improving decision-making.
Machine teaching is redefining how we interact with artificial intelligence (AI) and machinelearning (ML). As industries increasingly adopt AI solutions, professionals without a technical background can now step into the realm of machinelearning, leveraging powerful algorithms to automate tasks and improve decision-making.
Definition and characteristics of structured data Structured data is typically characterized by its organization within fixed fields in databases. Machinelearning Structured data is crucial in machinelearning applications. It provides clear and organized datasets essential for training supervisedlearning models.
Instance-based learning (IBL) is a fascinating approach within the realm of machinelearning that emphasizes the importance of individual data points rather than abstracting information into generalized models. This method allows systems to utilize specific historical examples to inform predictions about new instances.
Ground truth is a fundamental concept in machinelearning, representing the accurate, labeled data that serves as a crucial reference point for training and validating predictive models. What is ground truth in machinelearning?
I believe current Q-learning algorithms are not readily scalable, at least to long-horizon problems that require more than (say) 100 semantic decision steps. My definition of scalability here is the ability to solve more challenging, longer-horizon problems with more data (of sufficient coverage), compute, and time. Let me clarify.
Moving across the typical machinelearning lifecycle can be a nightmare. Machinelearning platforms are increasingly looking to be the “fix” to successfully consolidate all the components of MLOps from development to production. What is a machinelearning platform? That’s where this guide comes in!
Support Vector Machines (SVM) are a cornerstone of machinelearning, providing powerful techniques for classifying and predicting outcomes in complex datasets. What are Support Vector Machines (SVM)? Support Vector Machines (SVM) are a type of supervisedlearning algorithm designed for classification and regression tasks.
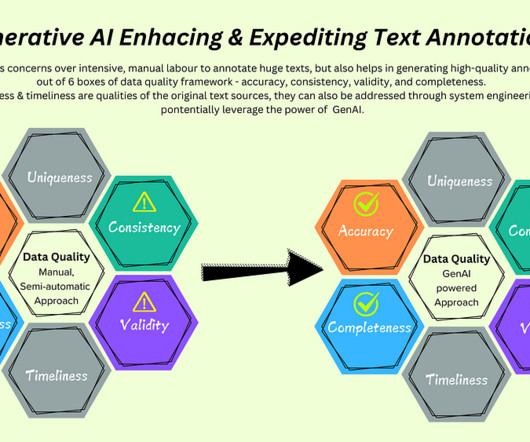
How do you tell the MachineLearning models the meaning of a particular word, especially when they are quantitatively intelligent and lexically challenged? This definitely estimates the spectrum of usage of text annotations to cater to the demands of the AI revolution across various industries. Behind the Medium paywall?
The functionality of deep learning Deep learning relies heavily on the architecture of neural networks, which consist of interconnected layers that process information similarly to the human brain. Definition of neural networks Neural networks are designed to recognize patterns in data.
Definition and characteristics of algorithms Algorithms are characterized by their systematic procedures. Machinelearning as an algorithm example Machinelearning encompasses a variety of algorithms that learn from data and improve over time.
“Self-Supervised methods […] are going to be the main method to train neural nets before we train them for difficult tasks” — Yann LeCun Well! Let’s have a look at this Self-SupervisedLearning! Let’s have a look at Self-SupervisedLearning. That is why it is called Self -SupervisedLearning.
Summary: The blog provides a comprehensive overview of MachineLearning Models, emphasising their significance in modern technology. It covers types of MachineLearning, key concepts, and essential steps for building effective models. The global MachineLearning market was valued at USD 35.80
Summary: This article compares Artificial Intelligence (AI) vs MachineLearning (ML), clarifying their definitions, applications, and key differences. While AI aims to replicate human intelligence across various domains, ML focuses on learning from data to improve performance. What is MachineLearning?
Robotic process automation vs machinelearning is a common debate in the world of automation and artificial intelligence. Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. What is machinelearning (ML)?
Summary: Entropy in MachineLearning quantifies uncertainty, driving better decision-making in algorithms. It optimises decision trees, probabilistic models, clustering, and reinforcement learning. This concept, pivotal in understanding data structures and communication systems, plays a significant role in MachineLearning.
NOTES, DEEP LEARNING, REMOTE SENSING, ADVANCED METHODS, SELF-SUPERVISEDLEARNING A note of the paper I have read Photo by Kelly Sikkema on Unsplash Hi everyone, In today’s story, I would share notes I took from 32 pages of Wang et al., Taxonomy of the self-supervisedlearning Wang et al. 2022’s paper.
It enhances visualisation, improves model performance, and mitigates overfitting, making it easier to interpret data and extract meaningful insights in MachineLearning and statistics. Dimensionality reduction in MachineLearning enhances model performance and improves data visualisation by focusing on the most significant dimensions.
The below animation demonstrates this process: 0:00 / 1× Since the Language Model is, by definition, a probability distribution over word sequences, we generate text by simply recursively asking for the most likely next word given all of our previous words. Yes, it really is that simple. Can we do better?
We wrote this post while working on Prodigy , our new annotation tool for radically efficient machine teaching. Prodigy features many of the ideas and solutions for data collection and supervisedlearning outlined in this blog post. It’s a cloud-free, downloadable tool and comes with powerful active learning models.
Teaching Through Data The purpose of annotating data is to tell machinelearning models exactly what we want them to know. Teaching a machine to learn through annotation can be likened to teaching a toddler shapes and colors using flashcards, where the annotations are the flashcards and annotators are the teacher.
How to Use MachineLearning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. Data forecasting has come a long way since formidable data processing-boosting technologies such as machinelearning were introduced. Some of them may even be deemed outdated by now.
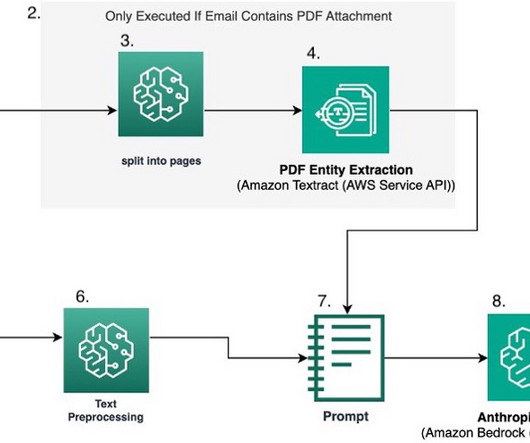
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machinelearning (ML) models in a cost-sensitive environment. When you evaluate a case, evaluate the definitions in order and label the case with the first definition that fits.
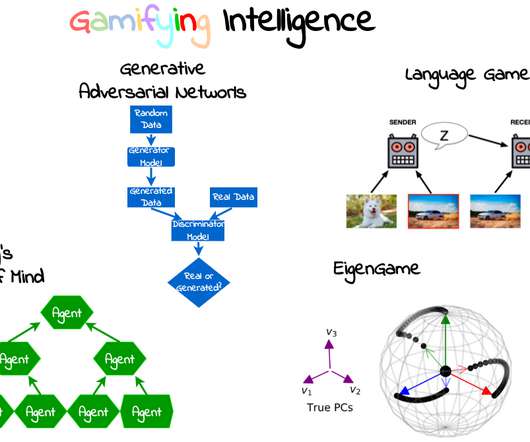
Our internal agents are playing games until they learn how to cooperate and trick us into believing we are an individual. Gamification There are many definitions for what a game is. How can you tell which features are the most appropriate, before giving them to a machinelearning model? Many AI researchers think there is.
Photo by Robo Wunderkind on Unsplash In general , a data scientist should have a basic understanding of the following concepts related to kernels in machinelearning: 1. Support Vector Machine Support Vector Machine ( SVM ) is a supervisedlearning algorithm used for classification and regression analysis.
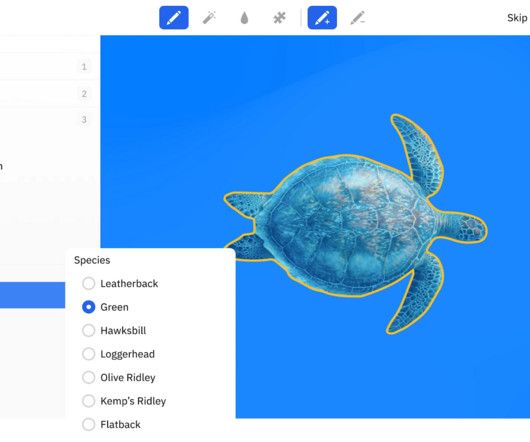
Image labeling and annotation are the foundational steps in accurately labeling the image data and developing machinelearning (ML) models for the computer vision task. In this article, you will learn about the importance of image annotation and what you should know for annotating image files for machinelearning at scale.
That’s definitely new. Once you’re past prototyping and want to deliver the best system you can, supervisedlearning will often give you better efficiency, accuracy and reliability than in-context learning for non-generative tasks — tasks where there is a specific right answer that you want the model to find.
Interpretability and Explainable AI Learning on Graphs and Other Geometries & Topologies Learning Theory Neurosymbolic & Hybrid AI Systems (Physics-Informed, Logic & Formal Reasoning, etc.) Optimization Other Topics in MachineLearning (i.e., Lee Other Topics In MachineLearning (I.e.,
I definitely recommend watching this one for all learners out here! Ramcharan12345 is looking to collaborate with AI devs who can leverage spaCy for NLP, utilize scikit-learn for supervisedlearning on historical data for symptom mapping, and implement TensorFlow/Keras for neural network-based risk prediction.
Robotic process automation vs machinelearning is a common debate in the world of automation and artificial intelligence. Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. What is machinelearning (ML)?
A definition from the book ‘Data Mining: Practical MachineLearning Tools and Techniques’, written by, Ian Witten and Eibe Frank describes Data mining as follows: “ Data mining is the extraction of implicit, previously unknown, and potentially useful information from data. Classification. Regression.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machinelearning and deep learning. Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence.
I lead product marketing efforts for TensorFlow and multiple open-source and machinelearning initiatives at Google. The first of these questions that we often see coming from our community is that in an age of big data, is the sheer volume of available data the primary determinant of machinelearning success?
I lead product marketing efforts for TensorFlow and multiple open-source and machinelearning initiatives at Google. The first of these questions that we often see coming from our community is that in an age of big data, is the sheer volume of available data the primary determinant of machinelearning success?
I lead product marketing efforts for TensorFlow and multiple open-source and machinelearning initiatives at Google. The first of these questions that we often see coming from our community is that in an age of big data, is the sheer volume of available data the primary determinant of machinelearning success?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content