This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Audience targeting and productivity: Transforming raw data into meaningful stories allows organizations to connect with their audience better, enhancing overall productivity and outcomes. Exploratorydataanalysis (EDA) ExploratoryDataAnalysis (EDA) is a systematic approach within the data exploration framework.
Parallel file systems are sophisticated solutions designed to optimize data storage and retrieval processes across multiple networked servers, facilitating robust I/O operations needed in various computing environments. Definitions and key differences Access methods differ significantly between parallel and distributed file systems.
The session, Business Analytics in Action: Driving Decisions with Data, provided participants with a comprehensive understanding of how analytics can transform business decision-making processes and drive meaningful results. The workshop began with an exploration of the fundamental concepts of business analytics and its evolution over time.
Machinelearning engineer vs data scientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machinelearning engineers and data scientists have gained prominence.
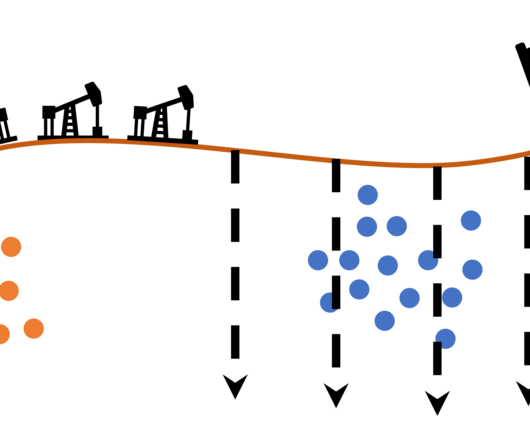
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machinelearning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
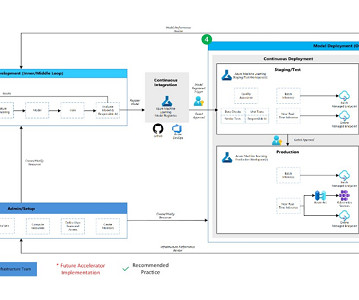
MachineLearning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
Summary: The KNN algorithm in machinelearning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Nevertheless, its applications across classification, regression, and anomaly detection tasks highlight its importance in modern data analytics methodologies.
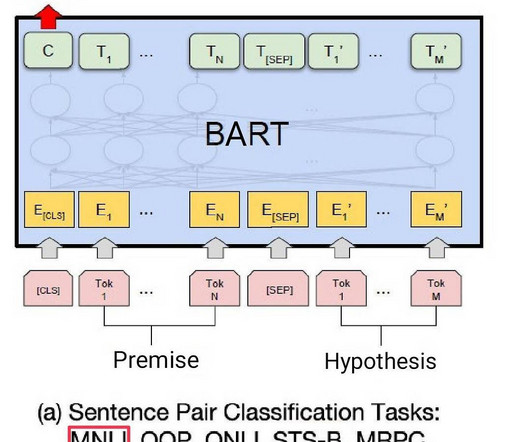
Gungor Basa Technology of Me There is often confusion between the terms artificial intelligence and machinelearning. An agent is learning if it improves its performance based on previous experience. When the agent is a computer, the learning process is called machinelearning (ML) [6, p.
MACHINELEARNING | ARTIFICIAL INTELLIGENCE | PROGRAMMING T2E (stands for text to exam) is a vocabulary exam generator based on the context of where that word is being used in the sentence. The AI generates questions asking for the definition of the vocabulary that made it to the end after the entire filtering process.
The machinelearning (ML) model classifies new incoming customer requests as soon as they arrive and redirects them to predefined queues, which allows our dedicated client success agents to focus on the contents of the emails according to their skills and provide appropriate responses. Huy Dang Data Scientist at Scalable GmbH.
I initially conducted detailed exploratorydataanalysis (EDA) to understand the dataset, identifying challenges like duplicate entries and missing Coordinate Reference System (CRS) information. I'd definitely would try more models pre-trained on remote sensing data. What motivated you to compete in this challenge?
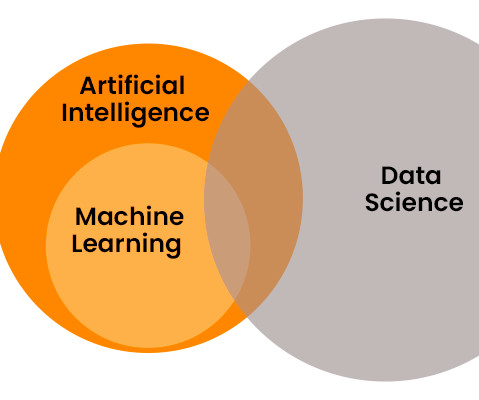
Summary: In the tech landscape of 2024, the distinctions between Data Science and MachineLearning are pivotal. Data Science extracts insights, while MachineLearning focuses on self-learning algorithms. AI refers to developing machines capable of performing tasks that require human intelligence.
These are multifaceted problems in which, by definition, certain entities should first be identified. An entire statistical analysis of those entities in the dataset should be carried out. Finally, specific algorithms should run on top of that analysis. It’s an open-source Python package for ExploratoryDataAnalysis of text.
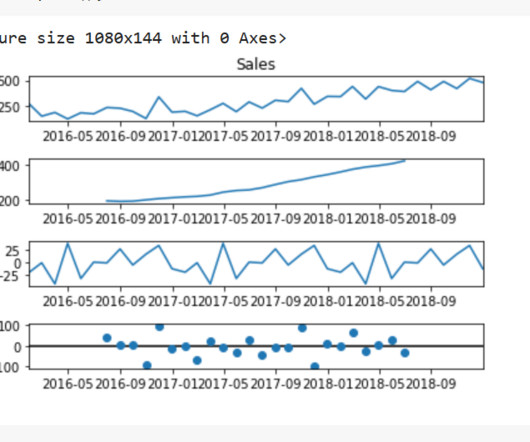
Understanding Model Monitoring Model monitoring is the process of continuously monitoring the performance of a machine-learning model over time. For time series data, model monitoring typically involves tracking a set of performance metrics over time to detect any changes or anomalies in the data that may impact the model’s accuracy.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machinelearning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
You will collect and clean data from multiple sources, ensuring it is suitable for analysis. You will perform ExploratoryDataAnalysis to uncover patterns and insights hidden within the data. Data Integration Data integration combines data from different sources into a single dataset.
Programs like Pickl.AI’s Data Science Job Guarantee Course promise data expertise including statistics, Power BI , MachineLearning and guarantee job placement upon completion. It emphasises probabilistic modeling and Statistical inference for analysing big data and extracting information.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machinelearning and deep learning. Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence.
Enterprises adopting machinelearning often experience significant challenges going from raw data to a deployable model. There are many reasons for that: Finding the Data: Data is rarely in one place. These capabilities take the form of: Exploratorydataanalysis to prepare basic features from raw data.
For example, your team could create a repository where data scientists, machinelearning engineers, and other associates interested in data science work can share, contribute, and consume Python classes and functions within their model build process. Just to start off with a very high-level question. Good question.
The process of statistical modelling involves the following steps: Problem Definition: Here, you clearly define the research question first that you want to address using statistical modeling. Data Collection: Based on the question or problem identified, you need to collect data that represents the problem that you are studying.
For example, your team could create a repository where data scientists, machinelearning engineers, and other associates interested in data science work can share, contribute, and consume Python classes and functions within their model build process. Just to start off with a very high-level question. Good question.
For example, your team could create a repository where data scientists, machinelearning engineers, and other associates interested in data science work can share, contribute, and consume Python classes and functions within their model build process. Just to start off with a very high-level question. Good question.
Firstly, we have the definition of the training set, which is refers to the training sample , which has features and labels. We have used packages like XGBoost, pandas, numpy, matplotlib, and a few packages from scikit-learn. Although we have already addressed this in the first blog post of this series, let’s go over it again.
Getting machinelearning to solve some of the hardest problems in an organization is great. In this article, I will share my learnings of how successful ML platforms work in an eCommerce and what are the best practices a Team needs to follow during the course of building it. are present in the data.
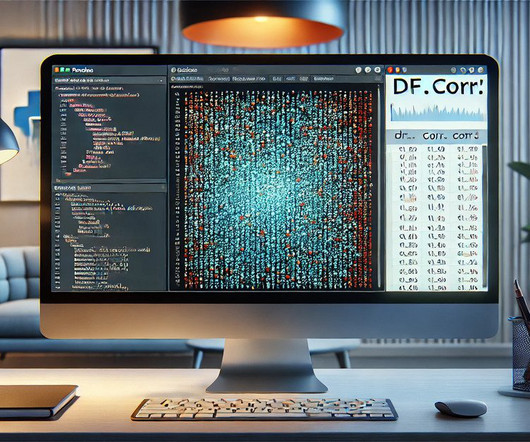
Definition and Purpose of the corr() Method The corr() method is essential for performing correlation analysis in Pandas. This method is a foundational tool in exploratoryDataAnalysis, enabling analysts to uncover hidden patterns and make data-driven decisions.
Using ChatGPT for Test Automation | LambdaTest Stage 5: Deployment Generative AI can be used to automate the deployment of software systems, e.g. generate Infrastructure-as-code definition, container build scripts, Continuous Integration/Continuous Deployment pipeline or GitOps pipeline. New developers should learn basic concepts (e.g.
AdaBoos t A formal definition of AdaBoost (Adaptive Boosting) is “the combination of the output of weak learners into a weighted sum, representing the final output.” A bit of exploratorydataanalysis (EDA) on the dataset would show many NaN (Not-a-Number or Undefined) values. But that leaves a lot of things vague. .
Well, thanks to the wonders of MachineLearning and the wizardry of Python programming, we’re not far from turning that imagination into reality. Last Updated on July 15, 2023 by Editorial Team Author(s): Muttineni Sai Rohith Originally published on Towards AI. Sounds like something out of a sci-fi movie, right?
In this article, we present a comprehensive overview of the most commonly used data visualization functions and tools, with a particular focus on their applications in machinelearning projects, especially those involving computer vision. What is data visualization?
As an assistant vice president, he developed data science and machinelearning models to price bonds more accurately. In most cases, there is no definitive right or wrong answer, he says. There are eight of what he calls spokes in data science. Continuing education is important, Anand says.
In the Unsupervised Wisdom Challenge , participants were tasked with identifying novel, effective methods of using unsupervised machinelearning to extract insights about older adult falls from narrative medical record data. I enjoy participating in machinelearning/data-science challenges and have been doing it for a while.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content