This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Embedded methods : Perform feature selection during model training using techniques like Lasso (L1 regularization) or decisiontree feature importance. Wrapper methods : Evaluate feature subsets by training models on different combinations and selecting the one that yields the best performance (e.g., recursive feature elimination).
Gradient boosting involves training a series of weak learners (often decisiontrees) where each subsequent tree corrects the errors of the previous ones, creating a strong predictive model. How to Use CatBoost in Python Let’s look at how to get started with CatBoost in Python. First, install the library using: !
Trees playing Baseball by author using DALLE 3. Decisiontrees form the backbone of some of the most popular machine learning models in industry today, such as Random Forests, Gradient Boosted Trees, and XGBoost. One of the biggest advantages of decisiontrees is their interpretability. Image by author.
Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive. Popular tools for implementing it include WEKA, RapidMiner, and Python libraries like mlxtend. R and Python Libraries Both R and Python offer several libraries that support associative classification tasks.
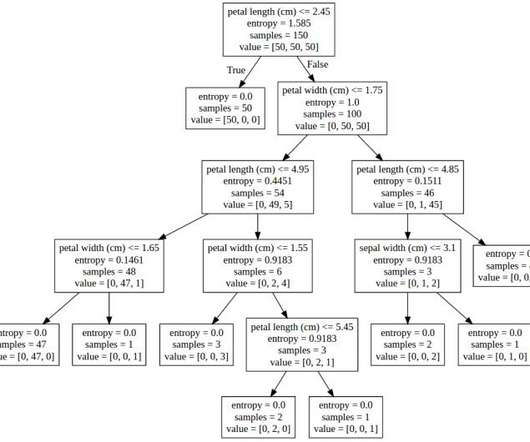
Using Accuracy Score in Python In Python, we can calculate accuracy using the accuracy_score function from the sklearn.metrics module. So, accuracy is: Case Study: Predicting the Iris Dataset with a DecisionTree The Iris dataset contains flower measurements that classify flowers into three types: Setosa, Versicolor, and Virginica.
The algorithm’s construction begins by creating multiple decisiontrees, each built through a process of repeatedly cutting the data space with random hyperplanes. This partitioning continues until each data point is isolated, creating a forest of trees that captures the underlying structure of the data.
Cleaning data sets can be automated using Talend, Alteryx, or Python libraries such as Pandas and NumPy.Data validation is better done on platforms like Informatica or custom-designed workflows with embedded quality rules that assure consistency and accuracy for large volumes of data.
Some examples of supervised algorithms are linear regression, logistic regression, support vector machines, and decisiontrees. Some of the commonly known algorithms of this category are: DecisionTrees : These models split the data into branches to reach a decision, making them highly interpretable.
We begin with a clear, approachable guide to Python and core computer science concepts ideal if youre just starting out or brushing up on the basics. Whats AI Weekly This week in Whats AI, I dive into Python Fundamentals and CS Concepts. But from there, things go deeper.
DecisiontreesDecisiontrees form the backbone of XGBoost. In this context, Gradient Boosted DecisionTrees (GBDT) sequentially build trees, where each tree aims to correct the errors of the previous one. caret in R: Access to XGBoost enhances model training capabilities.
Introduction In this article, we are going to learn about DecisionTree Machine Learning algorithm. We will build a Machine learning model using a decisiontree algorithm and we use a news dataset for this. The post DecisionTree Machine Learning Algorithm Using Python appeared first on Analytics Vidhya.
The post All About DecisionTree from Scratch with Python Implementation appeared first on Analytics Vidhya. Introduction Photo by Tim Foster on Unsplash If you see, you will find out that today, ensemble learnings are more popular and used by.
A Simple Analogy to Explain DecisionTree vs. Random Forest Let’s start with a thought experiment that will illustrate the difference between a decision. The post DecisionTree vs. Random Forest – Which Algorithm Should you Use? appeared first on Analytics Vidhya.
The post A Comprehensive Guide to Decisiontrees appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon. In this series, we will start by discussing how to.
Understanding the problem of Overfitting in DecisionTrees and solving it by. Quick Guide to Cost Complexity Pruning of DecisionTrees appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. The post Let’s Solve Overfitting!
This post will look at a few different ways of attempting to simplify decisiontree representation and, ultimately, interpretability. All code is in Python, with Scikit-learn being used for the decisiontree modeling.
Overview What Is Decision Classification Tree Algorithm How to build. The post Beginner’s Guide To DecisionTree Classification Using Python appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon.
This tutorial covers decisiontrees for classification also known as classification trees, including the anatomy of classification trees, how classification trees make predictions, using scikit-learn to make classification trees, and hyperparameter tuning.
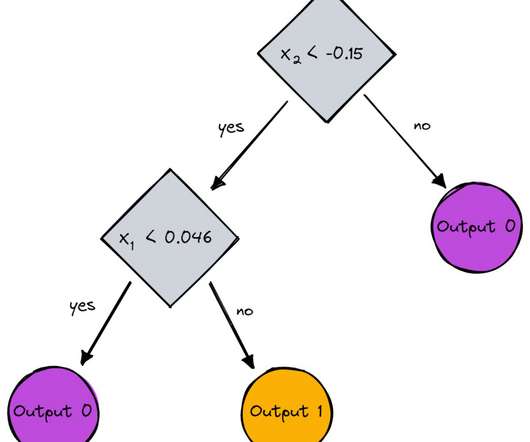
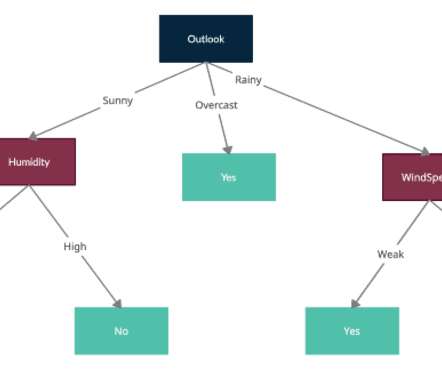
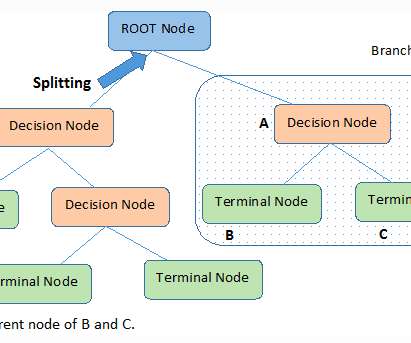
Introduction Decisiontrees, a fundamental tool in machine learning, are used for both classification and regression. With each internal node representing a decision based on a feature and each leaf node representing an outcome, decisiontrees mirror human decision-making processes, making them accessible and interpretable.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction A Gradient Boosting Decisiontree or a GBDT is a. The post Complete guide on how to Use LightGBM in Python appeared first on Analytics Vidhya.
DECISIONTREEDecisiontree learning or classification Trees are a. The post Implement Of DecisionTree Using Chi_Square Automatic Interaction Detection appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon.
The post Analyzing DecisionTree and K-means Clustering using Iris dataset. ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction: As we all know, Artificial Intelligence is being widely. appeared first on Analytics Vidhya.
It's a programming language designed for writing good CLI scripts, so it's aiming to replace Bash but is much more Python-like, and offers unique syntax and a bunch of in-built support for scripting. Uses lldb's Python scripting extensions to register commands, and handle memory access.
You'll learn how to create a decisiontree, how to do tree bagging, and how to do tree boosting. Check out this tutorial walking you through a comparison of XGBoost and Random Forest.
Also: DecisionTree Algorithm, Explained; Data Science Projects That Will Land You The Job in 2022; The 6 Python Machine Learning Tools Every Data Scientist Should Know About; Naïve Bayes Algorithm: Everything You Need to Know.
Free Python Automation Course • Machine Learning Algorithms Explained in Less Than 1 Minute Each • Parallel Processing Large File in Python • 12 Most Challenging Data Science Interview Questions • DecisionTree Algorithm, Explained.
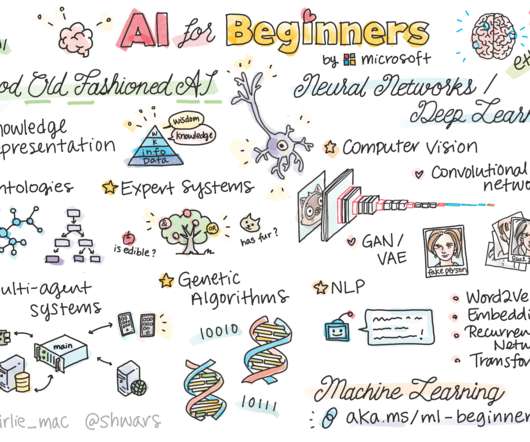
How to Perform Motion Detection Using Python • The Complete Collection of Data Science Projects – Part 2 • Free AI for Beginners Course • DecisionTree Algorithm, Explained • What Does ETL Have to Do with Machine Learning?
Also: How to Learn Math for Machine Learning; 7 Steps to Mastering Machine Learning with Python in 2022; Top Programming Languages and Their Uses; The Complete Collection of Data Science Cheat Sheets – Part 1.
Also: 12 Essential VSCode Extensions for Data Science; DecisionTree Algorithm, Explained; Statistics and Probability for Data Science; 15 Python Coding Interview Questions You Must Know For Data Science.
Also: DecisionTree Algorithm, Explained; Naïve Bayes Algorithm: Everything You Need to Know; Top Programming Languages and Their Uses; 5 Different Ways to Load Data in Python.
Also: DecisionTree Algorithm, Explained; 15 Python Coding Interview Questions You Must Know For Data Science; Naïve Bayes Algorithm: Everything You Need to Know; KDnuggets Top Posts for May 2022: 9 Free Harvard Courses to Learn Data Science in 2022.
These algorithms are decisiontrees and random forests. Introduction to Classification Algorithms In this article, we shall analyze loan risk using 2 different supervised learning classification algorithms. At the outset, the basic features and the concepts involved would be discussed followed by a […].
Also: DecisionTree Algorithm, Explained; 15 Python Coding Interview Questions You Must Know For Data Science; Naïve Bayes Algorithm: Everything You Need to Know; Primary Supervised Learning Algorithms Used in Machine Learning.
Also: DecisionTree Algorithm, Explained; 20 Basic Linux Commands for Data Science Beginners; 15 Python Coding Interview Questions You Must Know For Data Science; Naïve Bayes Algorithm: Everything You Need to Know.
Also: DecisionTree Algorithm, Explained; How to Become a Machine Learning Engineer; The Complete Collection of Data Science Books – Part 2; 15 Python Coding Interview Questions You Must Know For Data Science.
How LinkedIn Uses Machine Learning To Rank Your Feed • Confusion Matrix, Precision, and Recall Explained • Matrix Multiplication for Data Science (or Machine Learning) • Machine Learning from scratch: DecisionTrees • 7 Python Projects for Beginners.
Free AI for Beginners Course • How to Perform Motion Detection Using Python • 3 Free Statistics Courses for Data Science • The 5 Hardest Things to Do in SQL • DecisionTree Algorithm, Explained.
How to Select Rows and Columns in Pandas Using [ ],loc, iloc,at and.iat • Top Free Git GUI Clients for Beginners • DecisionTree Algorithm, Explained • 7 Techniques to Handle Imbalanced Data • Free Algorithms in Python Course.
Introduction In the previous article, we understood the complete flow of the decisiontree algorithm. when we already have a decisiontree algorithm. Similar to the decisiontree. In this article, let‘s understand why we need to learn about the random forest. Why do we need Random forest?
Also: DecisionTree Algorithm, Explained; Naïve Bayes Algorithm: Everything You Need to Know; Why Are So Many Data Scientists Quitting Their Jobs?; Top Programming Languages and Their Uses.
Also: DecisionTree Algorithm, Explained; 21 Cheat Sheets for Data Science Interviews; 15 Python Coding Interview Questions You Must Know For Data Science; Learn MLOps with This Free Course.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content