This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
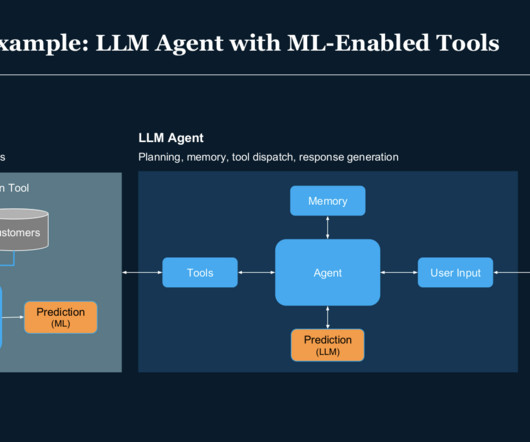
Building ML infrastructure and integrating ML models with the larger business are major bottlenecks to AI adoption [1,2,3]. IBM Db2 can help solve these problems with its built-in ML infrastructure. In this post, I will show how to develop, deploy, and use a decisiontree model in a Db2 database.
This ensemble learning method harnesses the collective strength of numerous decisiontrees to improve prediction accuracy significantly. Its strength lies in the combination of multiple decisiontrees to create a more accurate and reliable predictive model. How does Random Forest work?
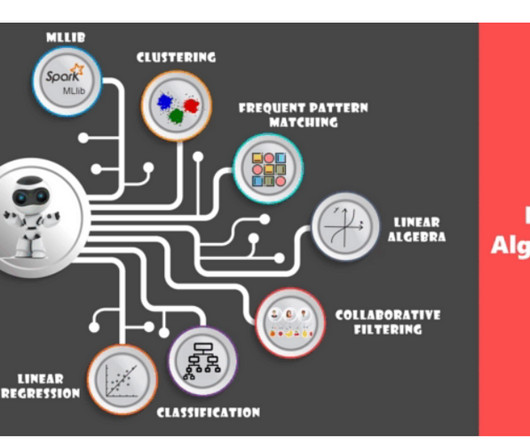
Pyspark MLlib | Classification using Pyspark ML In the previous sections, we discussed about RDD, Dataframes, and Pyspark concepts. In this article, we will discuss about Pyspark MLlib and Spark ML. Our final DataFrame containing the required information is as below: Let's split the data for training and testing.
Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. DecisionTrees visualize decision-making processes for better understanding. Linear Regression predicts continuous outcomes, like housing prices.
The answer to this dilemma is Arize AI, the team leading the charge on ML observability and evaluation in production. Known for their open-source tool Arize Phoenix, they are helping AI teams unlock visibility into how their agents really work, spotting breakdowns, tracing decision-making, and refining agent behavior in real time.
It provides a clear, structured format that enables easy manipulation, comparison, and visualization of information. Tabular data consists of structured information organized in rows and columns, resembling a spreadsheet layout. Importance of system reliability Maintaining the reliability of ML systems is crucial.
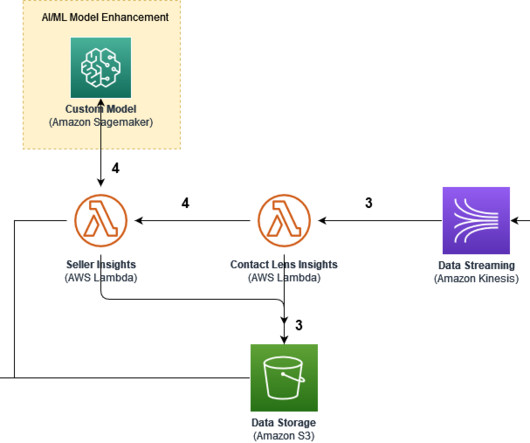
The large volume of contacts creates a challenge for CSBA to extract key information from the transcripts that helps sellers promptly address customer needs and improve customer experience. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
With the growing use of machine learning (ML) models to handle, store, and manage data, the efficiency and impact of enterprises have also increased. Categorical data is one such form of information that is handled by ML models using different methods. Learn about 101 ML algorithms for data science with cheat sheets 5.
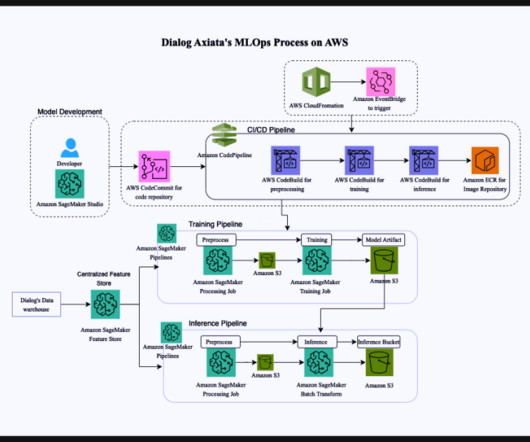
They focused on improving customer service using data with artificial intelligence (AI) and ML and saw positive results, with their Group AI Maturity increasing from 50% to 80%, according to the TM Forum’s AI Maturity Index. million subscribers, which amounts to 57% of the Sri Lankan mobile market.
At the same time, massive breaches are exposing sensitive personally identifiable information (PII) at an unnerving rate. The main difference is the use of counterfeit information. The bad actor creates fake names, contact information, or biometric data instead of stealing every piece of PII they can.
Feature selection is a critical component in the development of effective machine learning (ML) models. By systematically narrowing down the vast array of potential features, data analysts can enhance the model’s focus on the most informative elements.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. Machine learning(ML) is evolving at a very fast pace. Machine learning(ML) is evolving at a very fast pace. Models […]
Key reasons include: Contextual coherence Maintaining state makes sure that the application can track the flow of information, leading to more coherent and contextually relevant outputs. Background State persistence in generative AI applications refers to the ability to maintain and recall information across multiple interactions.
These tools enable data analysis, model building, and algorithm optimization, forming the backbone of ML applications. Introduction Machine Learning (ML) often seems like magic. Think of ML algorithms as sophisticated tools. Dimensionality reduction simplifies datasets while preserving critical information.
I’ve passed many ML courses before, so that I can compare. The course covers the basics of Deep Learning and Neural Networks and also explains DecisionTree algorithms. You start with the working ML model. Lesson #4: How to train large models on Kaggle Lots of beginners use Kaggle notebooks for ML.
Light & Wonder teamed up with the Amazon ML Solutions Lab to use events data streamed from LnW Connect to enable machine learning (ML)-powered predictive maintenance for slot machines. Predictive maintenance is a common ML use case for businesses with physical equipment or machinery assets.
This creditworthiness is influenced by several key factors: Credit History: The primary source of information is usually the applicant’s credit history, which is a detailed record of all past borrowing and repayment, including late payments and defaults. This is where credit-decisioning models are essential.
Generative AI is by no means a replacement for the previous wave of AI/ML (now sometimes referred to as ‘traditional AI/ML’), which continues to deliver significant value, and represents a distinct approach with its own advantages. In the end, we explain how MLOps can help accelerate the process and bring these models to production.
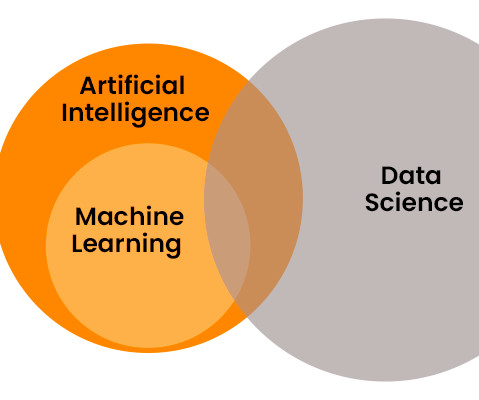
2024 Tech breakdown: Understanding Data Science vs ML vs AI Quoting Eric Schmidt , the former CEO of Google, ‘There were 5 exabytes of information created between the dawn of civilisation through 2003, but that much information is now created every two days.’ billion by 2032. billion in 2023 to an impressive $225.91
How to Scale Your Data Quality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
How to Use Machine Learning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. ML-based predictive models nowadays may consider time-dependent components — seasonality, trends, cycles, irregular components, etc. — to
One relies on structured, labeled information to make predictions, while the other uncovers hidden patterns in raw data. Definition of Supervised Learning and Unsupervised Learning Supervised learning is a process where an ML model is trained using labeled data. These are known as supervised learning and unsupervised learning.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decisiontree.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decisiontree.
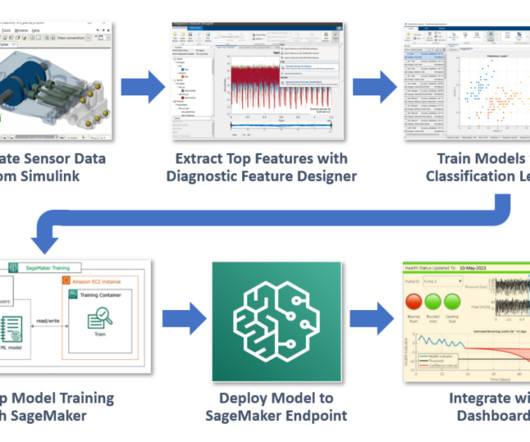
First, we extract features from a subset of the full dataset using the Diagnostic Feature Designer app, and then run the model training locally with a MATLAB decisiontree model. You can set up and train a simple decisiontree classifier locally. We start by training a classifier model on our desktop with MATLAB.
Evaluating ML model performance is essential for ensuring the reliability, quality, accuracy and effectiveness of your ML models. In this blog post, we dive into all aspects of ML model performance: which metrics to use to measure performance, best practices that can help and where MLOps fits in. Why Evaluate Model Performance?
Machine learning (ML) and deep learning (DL) form the foundation of conversational AI development. ML algorithms understand language in the NLU subprocesses and generate human language within the NLG subprocesses. DL, a subset of ML, excels at understanding context and generating human-like responses.
Additionally, the elimination of human loop processes has made it possible for AI/ML to construct training data for data annotation and labeling, which has a major influence on geospatial data. This function can be improved by AI and ML, which allow GIS to produce insights, automate procedures, and learn from data.
With the emergence of machine learning (ML), developers now have an innovative approach for optimizing AngularJS performance. In this article, we’ll explore the concept of using ML to enhance AngularJS performance and provide practical tips for implementing ML strategies in your development process.
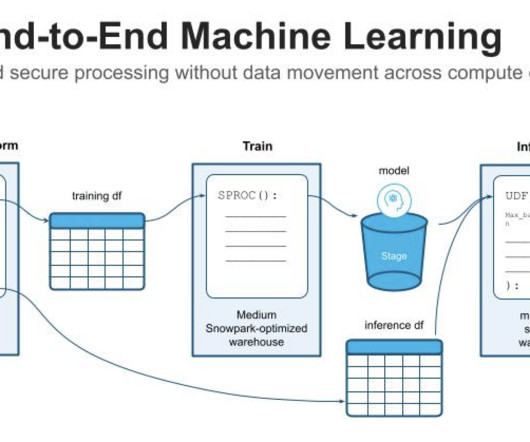
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
Machine learning (ML) has proven that it is here with us for the long haul, everyone who had their doubts by calling it a phase should by now realize how wrong they are, ML has being used in various sector’s of society such as medicine, geospatial data, finance, statistics and robotics.
As part of its goal to help people live longer, healthier lives, Genomics England is interested in facilitating more accurate identification of cancer subtypes and severity, using machine learning (ML). We provide insights on interpretability, robustness, and best practices of architecting complex ML workflows on AWS with Amazon SageMaker.
Feature Extraction Feature Extraction is basically extracting relevant information from the pre-processed image that can be used for classification. Classification In Classification, we use an ML Algorithm to classify the digit based on its features. Support Vector Machines (SVMs) are another ML models that can be used for HDR.
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decisiontrees, and reinforcement learning. Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
This is where the power of machine learning (ML) comes into play. Flow analysis tools like IPFIX, NetFlow, and sFlow collect flow data, which includes information about source and destination IPs, ports, and protocols. One of the primary applications of ML in network traffic analysis is anomaly detection.
We shall look at various machine learning algorithms such as decisiontrees, random forest, K nearest neighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. I wrote about Python ML here. Join thousands of data leaders on the AI newsletter.
In the last 10 years, AI and ML models have become bigger and more sophisticated — they’re deeper, more complex, with more parameters, and trained on much more data, resulting in some of the most transformative outcomes in the history of machine learning.
ML algorithms can be broadly divided into supervised learning , unsupervised learning , and reinforcement learning. How is it actually looks in a real life process of ML investigation? In this article, I will cover all of them. Regression is a technique to predict the real continuous value. It’s a fantastic world, trust me!
This region faces dry conditions and high demand for water, and these forecasts are essential for making informeddecisions. Vitaly Bondar: ML Team lead in theMind (formerly Neuromation) company with 6 years of experience in ML/AI and almost 20 years of experience in the industry.
Introduction Machine Learning (ML) is revolutionising the business world by enabling companies to make smarter, data-driven decisions. As an advanced technology that learns from data patterns, ML automates processes, enhances efficiency, and personalises customer experiences. Data : Data serves as the foundation for ML.
As Data Scientists, we all have worked on an ML classification model. In this article, we will talk about feasible techniques to deal with such a large-scale ML Classification model. In this article, you will learn: 1 What are some examples of large-scale ML classification models? Let’s take a look at some of them.
In this blog, I will explain how financial institutions leverage ML to improve their credit risk models and its effect on the outcome. How Does ML Benefit Credit Risk Modelling? Expected Loss: EAD x PD x LGD This entire calculation can be offloaded to ML models, without compromising speed, accuracy or agility.
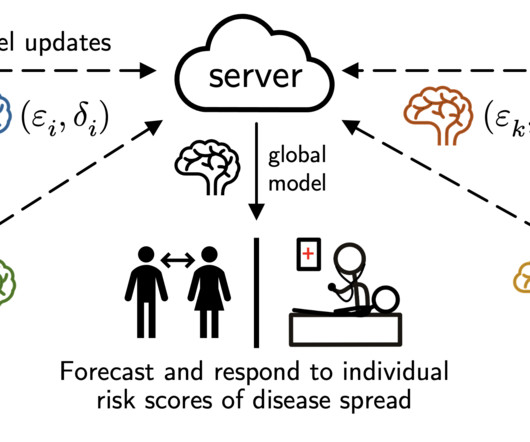
Unfortunately, while this data contains a wealth of useful information for disease forecasting, the data itself may be highly sensitive and stored in disparate locations (e.g., Graphs generally complicate DP : we are often used to ML settings where we can clearly define the privacy granularity and how it relates to an actual individual (e.g.
ML works with structured data, while DL processes complex, unstructured data. ML requires less computing power, whereas DL excels with large datasets. Introduction In todays world of AI, both Machine Learning (ML) and Deep Learning (DL) are transforming industries, yet many confuse the two. What is Machine Learning?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content