This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To get you started, Data Science Dojo and Weaviate have teamed up to bring you an exciting webinar series: Master Vector Embeddings with Weaviate. Whether you’re just starting or looking to refine your expertise, this webinar series is your gateway to the true potential of vector embeddings.
Introduction on Data Warehouses During one of the technical webinars, it was highlighted where the transactional database was rendered no-operational bringing day to day operations to a standstill. This article was published as a part of the Data Science Blogathon.
It requires building pipelines that bring in context from user history, prior interactions, tool calls, and internal databases — all in a format that’s easily digestible by a Transformer-based system. Context engineering doesn’t just mean “adding more stuff” to your prompt.
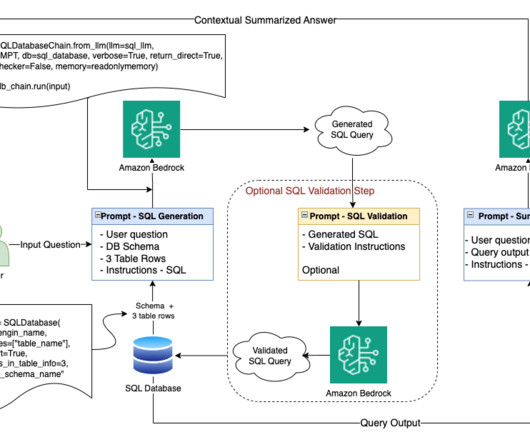
Organizations manage extensive structured data in databases and data warehouses. The system interprets database schemas and context, converting natural language questions into accurate queries while maintaining data reliability standards. Data analysts must translate business questions into SQL queries, creating workflow bottlenecks.
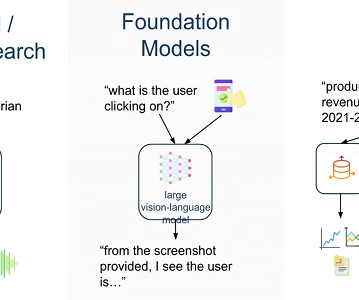
At a recent webinar hosted by Stefan Webb, Developer Advocate and champion of Milvus (an open-source vector database), he walked a global audience through the what, why, and how of building multimodal RAG systems. Enter multimodal embeddings, a powerful advancement enabling systems to understand and relate information across formats.
To ensure consistency and identify when we need to recover a worker, we effectively treat training with traditional database semantics. Traditional databases use “transactions” where each operation is either committed (entirely applied) or rolledback (discarded). Register now! torchft treats each training step the same way.
The SQL language, or Structured Query Language, is essential for managing and manipulating relational databases. It was designed to retrieve and manage data stored in relational databases. This versatile programming language is widely used by database administrators, developers, and data analysts.
PubMed – PubMed is a free search engine accessing primarily the MEDLINE database of references and abstracts on life sciences and biomedical topics. Scopus – Scopus citation database that covers scientific, technical, medical, and social sciences literature.
Each month, ODSC has a few insightful webinars that touch on a range of issues that are important in the data science world, from use cases of machine learning models, to new techniques/frameworks, and more. So here’s a summary of a few recent webinars that you’ll want to watch. This is why we want to begin highlighting them for you.
You can hear more details in the webinar this article is based on, straight from Kaegan Casey, AI/ML Solutions Architect at Seagate. This setup happens once per toolset and is stored in a database. In the end, inference results are consolidated and written to a database. It takes about a week and can be fine-tuned over time.
Database records: Structured data stored in databases. This is particularly important for managing digital content, including: Zoom recordings: Digital meetings and webinars that must be stored securely. Reports: Summaries of activities, findings, or financial performance. Information storage: Locations where records are kept.
So now the question is, how can you use your databases to generate more high-quality leads? It can be a list of tips, a free sample, a book, a set of templates, a webinar, a guide, personal consultancy, etc. Create Webinars. If you have enough resources, make a free webinar. This message shouldn’t be irritating.
RAG transforms unstructured data into embedded chunks stored in vector databases, using semantic similarity matching to retrieve relevant context for LLM queries. Moreover, it combines vector and graph databases to overcome the limitations of traditional LLM applications using ontology-guided knowledge graphs.
Right now is the absolute best time.” by Ankush Das AI may be rewriting the rules of software development, but it hasn’t erased the thrill of being a programmer.
She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. million, representing a 12% growth compared to the previous quarter. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI.
The most popular sources include the United States Computer Emergency Readiness Team (US-CERT), National Vulnerability Database, SecurityFocus, and more. Conferences, Webinars & Meetups. Even though this has since given way to webinars and virtual meetups, offline events should be back on the horizon as early as the coming year.
Each new unit needs validated physical, legal, and postal addresses established a process that isn’t always instantaneous or perfectly synchronized across databases or suppliers. Mismatches between provided addresses and database records may trigger fraud alerts or delay loan approvals. million new housing starts annually.
These steps will guide you through deleting your knowledge base, vector database, AWS Identity and Access Management (IAM) roles, and sample datasets, making sure that you don’t incur unexpected costs. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23.
Join our webinar to explore more Furthermore, users can analyze the impact of executing Turbo actions on the underlying entity KPIs. Watch our new release webinar to learn more about this update. Watch our new release webinar to learn more about this update. Learn more in our announcement blog.
Instana can track calls made to the external endpoint and tell Carlos that there is a database call the external task depends on that is timing out. Now Carlos can focus on getting that database healthy and the activities back on track. Measure Yourself the Way the Business Measures You.”
IBM Db2 : A reliable, high-performance database built for enterprise-level applications, designed to efficiently store, analyze and retrieve data. IBM Db2 serves as the backbone, providing a robust database for storing and managing data. Boasting decades of expertise in reliability, scalability, security and performance.
During the embeddings experiment, the dataset was converted into embeddings, stored in a vector database, and then matched with the embeddings of the question to extract context. The generated query is then run against the database to fetch the relevant context. Based on the initial tests, this method showed great results.
In this approach, the LLM query retrieves relevant documents from a database and passes these into the LLM as additional context. In this example, we will use several audio files from LangChain’s webinar series on YouTube , but feel free to use any files you’d like.
It works by first retrieving relevant responses from a database, then using those responses as context to feed the generative model to produce a final output. For example, retrieving responses from its database before generating a response could provide more relevant and coherent responses. He received his Ph.D.
They dont possess a database of facts or access real-time information. Unless integrated with other systems, LLMs cant access recent data, current events, or proprietary databases. Week 3 of the ODSC East Bootcamp: From Hype to Hands-On with LLMs +RAG This isnt just another webinar that leaves you with buzzwords and more questions.
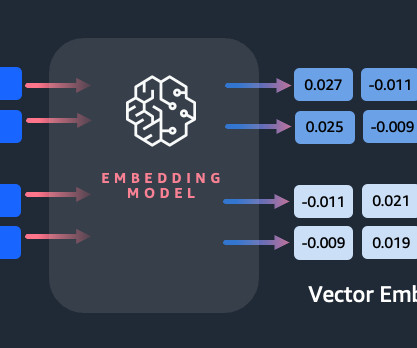
Thus, these embeddings lead to the building of databases that transformers use to generate useful outputs in NLP applications. Today, embeddings have also developed to present new ways of data representation with vector embeddings, leading organizations to choose between traditional and vector databases.
Webinar A Day in the Life of Location Data: Turning Where into How Discover how location data—when properly managed—can unlock operational efficiency, elevate customer experiences, and fuel business transformation at scale. The post Disconnected Location Data?
Agents can make cold calls to numbers in their database and try to convert them to customers. They can notify leads that are interested in future seminars and webinars, as well as new programs and offers. Companies can ensure they have a detailed database of information that call center employees need to answer questions.
The CloudFormation template provisions resources such as Amazon Data Firehose delivery streams, AWS Lambda functions, Amazon S3 buckets, and AWS Glue crawlers and databases. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23.
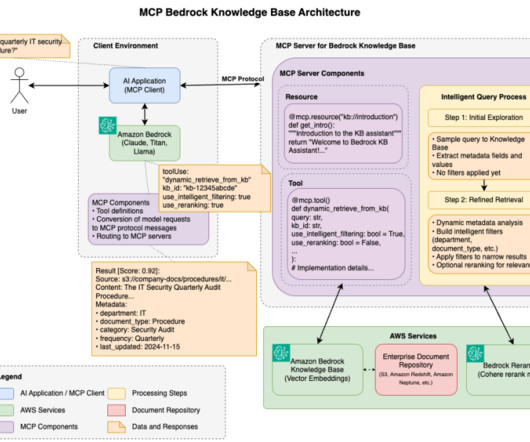
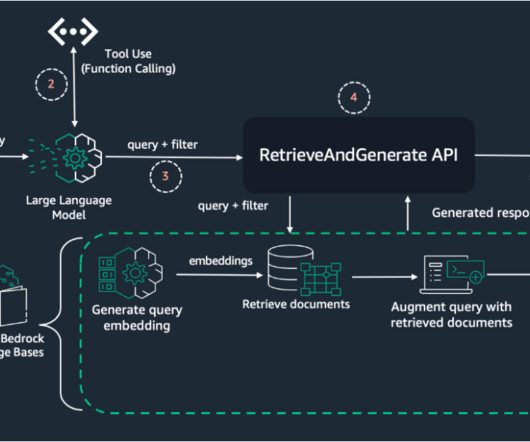
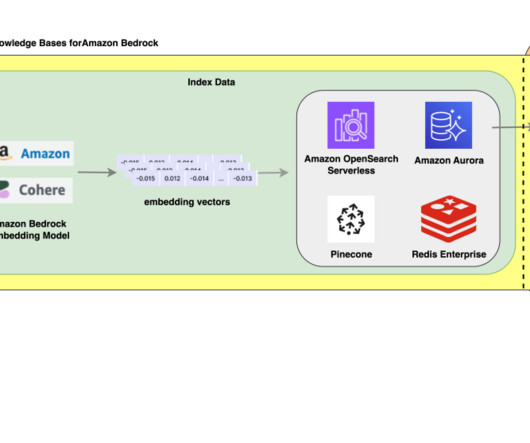
Internally, Amazon Bedrock uses embeddings stored in a vector database to augment user query context at runtime and enable a managed RAG architecture solution. The document embeddings are split into chunks and stored as indexes in a vector database. We use the Amazon letters to shareholders dataset to develop this solution.
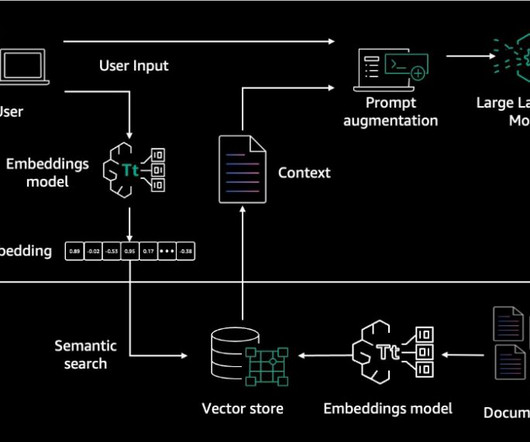
In addition to semantic search, you can use embeddings to augment your prompts for more accurate results through Retrieval Augmented Generation (RAG)—but in order to use them, you’ll need to store them in a database with vector capabilities. The example matches a user’s query to the closest entries in an in-memory vector database.
Past Issues Webinars & Podcasts Upcoming Events Video Archive Podcasts Me, Myself, and AI Subscribe Now Save 22% on Unlimited Access. Sam Ransbotham: … ImageNet is a database of 14-plus million images that … started with a contest about a decade ago for image recognition. It got really, really good over that last decade.
The following figure shows how Amazon Bedrock Data Automation seamlessly integrates with Amazon Bedrock Knowledge Bases to extract insights from unstructured datasets and ingest them into a vector database for efficient retrieval. Finally, the data is stored in a database for downstream applications to consume.
Moving to S/4HANA could involve modernizing the stack from application to database to infrastructure, depending on the current ERP landscape. As with most enterprise IT modernization programs, there is no one-size-fits-all solution.
It offers businesses the capability to capture and process real-time information from diverse sources, such as databases, software applications and cloud services. At the forefront of this event-driven revolution is Apache Kafka, the widely recognized and dominant open-source technology for event streaming.
Context is retrieved from the vector database based on the user query. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. She speaks at internal and external conferences such as AWS re:Invent, AWS Summits, and webinars.
Building Multimodal RAG Systems with Vector Databases Learn how multimodal RAG systems are transforming data retrieval by connecting text, images, and beyond. Webinar: Designing Smart Agent MemoryHow To Go From Raw Data To Actionable Context Wednesday, June 11th, 12:00 PM ET AI agents are only as good as what they remember.
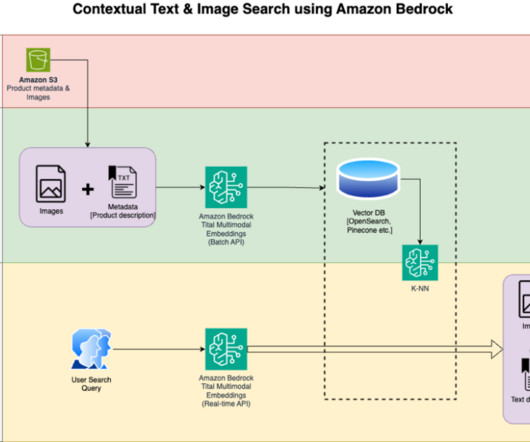
With Amazon Titan Multimodal Embeddings, you can generate embeddings for your content and store them in a vector database. We use Amazon OpenSearch Serverless as a vector database for storing embeddings generated by the Amazon Titan Multimodal Embeddings model. These steps are completed prior to the user interaction steps.
By automating document ingestion, chunking, and embedding, it eliminates the need to manually set up complex vector databases or custom retrieval systems, significantly reducing development complexity and time. She speaks at internal and external conferences such as AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content