This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Analytics databases play a crucial role in driving insights and decision-making in today’s data-driven world. By providing a structured way to analyze historical data, these databases empower organizations to uncover trends and patterns that inform strategies and optimize operations. What are analytics databases?
Introduction In relational databases, retaining information security and integrity is paramount. SQL’s Data Control Language (DCL) empowers you with the essential tools to control user privileges, ensuring only specific people can access and control database items.
We create more information every day— and most of this data is high-dimensional and complex. Hence, it becomes hard to study using ordinary relational databases. Introduction We are currently living in an age where data is overwhelming us.
Introduction Managing complicated, interrelated information is more important than ever in today’s data-driven society. Traditional databases, while still valuable, often falter when it comes to handling highly connected data. Enter the unsung heroes of the data world: graph databases.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
Introduction In the dynamic realm of contemporary applications, real-time databases are pivotal for maintaining smooth data management and immediate updates. Engineered to handle substantial data volumes, these databases offer instantaneous access to information.
In this contributed article, April Miller, a senior IT and cybersecurity writer for ReHack Magazine, believes that If you need a new database for your business, Amazon Web Services DynamoDB and Apache Cassandra are two of the most prominent options.
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. In today’s digital world, businesses must make data-driven decisions to manage huge sets of information. Rules are put in place by databases to ensure data integrity and minimize redundancy.
Traditional hea l t h c a r e databases struggle to grasp the complex relationships between patients and their clinical histories. Vector databases are revolutionizing healthcare data management. Unlike traditional, table-like structures, they excel at handling the intricate, multi-dimensional nature of patient information.
Many organizations today are unlocking the power of their data by using graph databases to feed downstream analytics, enahance visualizations, and more. Watch this essential video with Senzing CEO Jeff Jonas on how adding entity resolution to a graph database condenses network graphs to improve analytics and save your analysts time.
To keep up with these rapid developments, it’s crucial to stay informed through reliable and insightful sources. In this blog, we will explore the top 7 LLM, data science, and AI blogs of 2024 that have been instrumental in disseminating detailed and updated information in these dynamic fields.
Introduction Searching for specific patterns within the data is often necessary when working with databases. The LIKE operator allows you to perform pattern matching on text data, making it a powerful tool for filtering and retrieving information from a database. This is where the SQL LIKE operator comes in handy.
Fortunately, we’re in close touch with vendors from this vast ecosystem, so we’re in a unique position to inform you about all that’s new and exciting. Our massive industry database is growing all the time so stay tuned for the latest news items describing technology that may make you and your organization more competitive.
It powers business decisions, drives AI models, and keeps databases running efficiently. Without proper organization, databases become bloated, slow, and unreliable. Essentially, data normalization is a database design technique that structures data efficiently. Think about itdata is everywhere.
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
Vector databases play a pivotal role in managing complex data environments, especially in the realms of artificial intelligence and machine learning. These databases allow for rapid processing, enabling applications from semantic search to fraud detection, thereby enhancing user experiences and security. What are vector databases?
In this post, we describe a solution to integrate generative AI applications with relational databases like Amazon Aurora PostgreSQL-Compatible Edition using RDS Data API (Data API) for simplified database interactions, Amazon Bedrock for AI model access, Amazon Bedrock Agents for task automation and Amazon Bedrock Knowledge Bases for context information (..)
Fortunately, we’re in close touch with vendors from this vast ecosystem, so we’re in a unique position to inform you about all that’s new and exciting. Our massive industry database is growing all the time so stay tuned for the latest news items describing technology that may make you and your organization more competitive.
Fortunately, we’re in close touch with vendors from this vast ecosystem, so we’re in a unique position to inform you about all that’s new and exciting. Our massive industry database is growing all the time so stay tuned for the latest news items describing technology that may make you and your organization more competitive.
Fortunately, we’re in close touch with vendors from this vast ecosystem, so we’re in a unique position to inform you about all that’s new and exciting. Our massive industry database is growing all the time so stay tuned for the latest news items describing technology that may make you and your organization more competitive.
Nearest neighbour search over dense vector collections has important applications in information retrieval, retrieval augmented generation (RAG), and content ranking. Performing efficient search over large vector collections is a well studied problem with many existing approaches and open source implementations.
By employing a multi-modal approach, the solution connects relevant data elements across various databases. The solution is designed to provide customers with a detailed, personalized explanation of their preferred features, empowering them to make informed decisions.
Introduction In relational databases, where data is meticulously organized in tables, understanding their structure is essential. SQL’s DESCRIBE (or DESC in some database systems) command gives you to become a data detective, peering into the internal makeup of your tables and extracting valuable information.
Fortunately, we’re in close touch with vendors from this vast ecosystem, so we’re in a unique position to inform you about all that’s new and exciting. Our massive industry database is growing all the time so stay tuned for the latest news items describing technology that may make you and your organization more competitive.
This approach not only enhances efficiency, but also provides valuable insights that can help automotive businesses make more informed decisions. The information contained in these datasets—the images and the corresponding metadata—is converted to numerical vectors using a process called multimodal embedding.
According to the Bureau of Labor Statistics , the outlook for information technology and computer science jobs is projected to grow by 15 percent between 2021 and 2031, a rate much faster than the average for all occupations. Future of the Role The demand for Information Security Analysts is expected to grow substantially.
Artificial intelligence (AI) has transformed how humans interact with information in two major wayssearch applications and generative AI. AWS recommends Amazon OpenSearch Service as a vector database for Amazon Bedrock as the building blocks to power your solution for these workloads.
Fortunately, we’re in close touch with vendors from this vast ecosystem, so we’re in a unique position to inform you about all that’s new and exciting. Our massive industry database is growing all the time so stay tuned for the latest news items describing technology that may make you and your organization more competitive.
Introduction Structured Query Language (SQL) is the backbone of relational database management systems, empowering users to interact with and retrieve information from databases. When working with databases, sorting the data in a specific order is often necessary to make it more meaningful and easier to analyze.
This option is used for filtering records in order to give out specific data from the database files. Suppose you have a huge list of customers storing their information in your database; you need to search for customers from a specific […] The post Understanding SQL WHERE Clause appeared first on Analytics Vidhya.
Published: June 11, 2025 Announcements 5 min read by Ali Ghodsi , Stas Kelvich , Heikki Linnakangas , Nikita Shamgunov , Arsalan Tavakoli-Shiraji , Patrick Wendell , Reynold Xin and Matei Zaharia Share this post Keep up with us Subscribe Summary Operational databases were not designed for today’s AI-driven applications.
“Carbon will make it easier for Perplexity’s answer engine to be informed by diverse sources of information, whether that data resides in internal databases, cloud storage, or document repositories.” ” Carbon raised a $1.3 million seed round in 2023.
Introduction In SQL, comparison operators are crucial for querying databases. It excludes specific data from query results, making it vital for database management. This operator refines data retrieval, ensuring you get relevant information. They help compare values and filter data based on conditions.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Introduction Ever wonder how to get a complete picture of your company from different databases? This lets you analyze and report on all your information at once. SQL can help! Merging data from tables is like putting puzzle pieces together. In this article, we’ll explore how to use SQL queries like JOIN, UNION, etc.
Introduction When working with databases and analyzing data, ranking records is very important for organizing information based on certain conditions. One ranking function called `DENSE_RANK()` is useful because it assigns ranks to rows without leaving any empty spaces or gaps.
Retrieval-Augmented Generation (RAG) In advanced systems, embeddings are used to retrieve relevant information from external datasets during the text generation process. Hence, it is a smart way to find information by looking at the meaning behind data instead of exact keywords.
As a result, the enterprise can build a chatbot capable of understanding and responding to customer inquiries with context-aware, accurate information, significantly reducing response times and enhancing customer satisfaction. It will ensure seamless integration of the business’s internal knowledge base and external data sources.
Yet, despite these impressive capabilities, their limitations became more apparent when tasked with providing up-to-date information on global events or expert knowledge in specialized fields. Revisit the best large language models of 2023 Enter RAG and finetuning RAG revolutionizes the way language models access and use information.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval. The solution uses the data domain to construct prompt inputs for the generative LLM.
Experts in the field teach these concepts, giving you the assurance of receiving the latest information. Any serious applications of LLMs require an understanding of nuances in how LLMs work, embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more. What is vector similarity search?
We are at the threshold of the most significant changes in information management, data governance, and analytics since the inventions of the relational database and SQL. Most advances over the past 30 years have been the result of Moores Law: faster processing, denser storage, and greater bandwidth.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




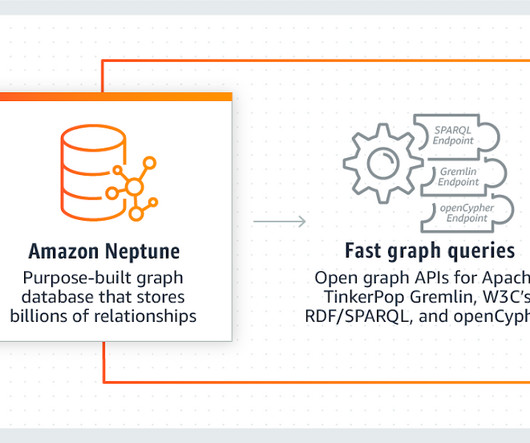





















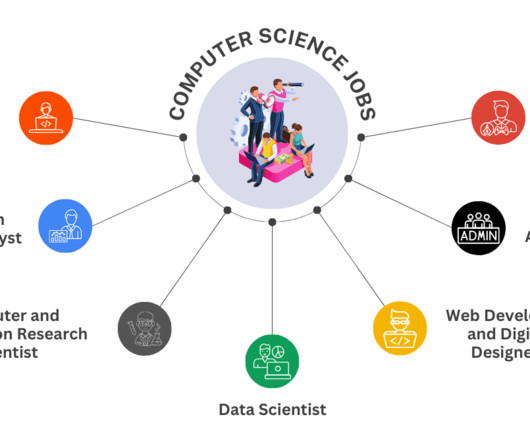










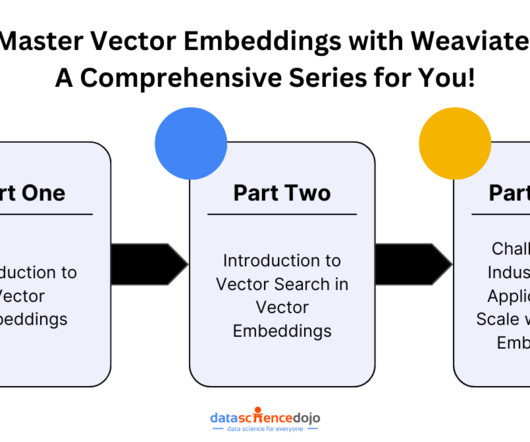
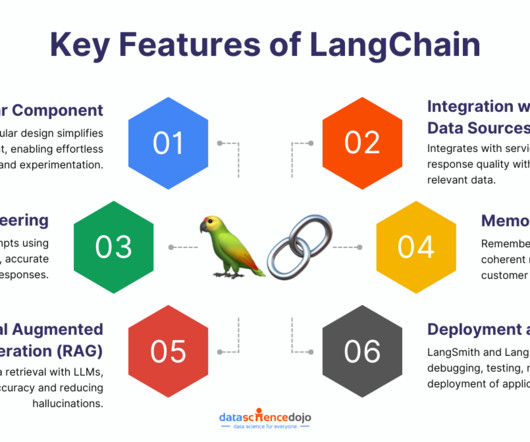


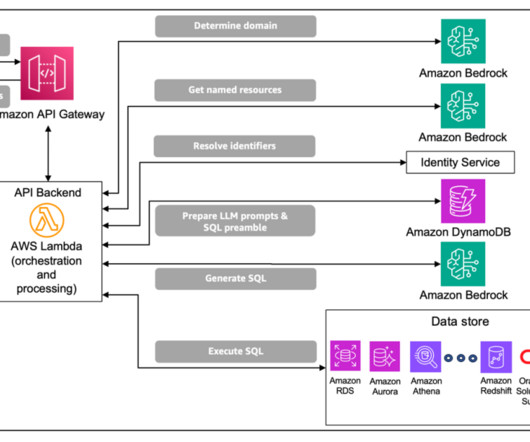








Let's personalize your content