This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Josep Ferrer , KDnuggets AI Content Specialist on June 10, 2025 in Python Image by Author DuckDB is a fast, in-process analytical database designed for modern data analysis. DuckDB is a free, open-source, in-process OLAP database built for fast, local analytics. Let’s dive in! What Is DuckDB? What Are DuckDB’s Main Features?
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data! Postgres is the leading open source standard for databases.
Triggers are used in SQL Server to respond to an event in the database server. Trigger automatically gets fired when an event occurs in the database server. Introduction on SQL Server SQL Server is an RDBMS developed and maintained by Microsoft. A trigger is a […].
Distributed databases are fascinating systems that facilitate data storage and management across multiple locations, often leading to enhanced performance and reliability. These databases function seamlessly across different geographical locations or networks, emphasizing data accessibility and availability.
Introduction Azure Functions is a serverless computing service provided by Azure that provides users a platform to write code without having to provision or manage infrastructure in response to a variety of events. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions?
Introduction A data model is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details. This article was published as a part of the Data Science Blogathon.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
centers around wide events, breaking down the silos between metrics, logs, and traces. This article outlines the core ideas and technical challenges of this new paradigm, and introduces how GreptimeDB, a native open-source database for wide events, provides a unified and efficient foundation for next-gen observability platforms.
Timescale, the cloud database company, announced the launch of Timescale Vector, enabling developers to build production AI applications at scale with PostgreSQL. Developers can now bring AI products to market faster, more reliably and efficiently than with traditional vector databases.
What is an online transaction processing database (OLTP)? But the true power of OLTP databases lies beyond the mere execution of transactions, and delving into their inner workings is to unravel a complex tapestry of data management, high-performance computing, and real-time responsiveness.
The recent meltdown of 23andme and what might become of their DNA database got me thinking about this question: What happens to your data when a company goes bankrupt? This latest turn of events, which involves infighting between management and […] The post Ask a Data Ethicist: What Happens to Your Data When a Company Goes Bankrupt?
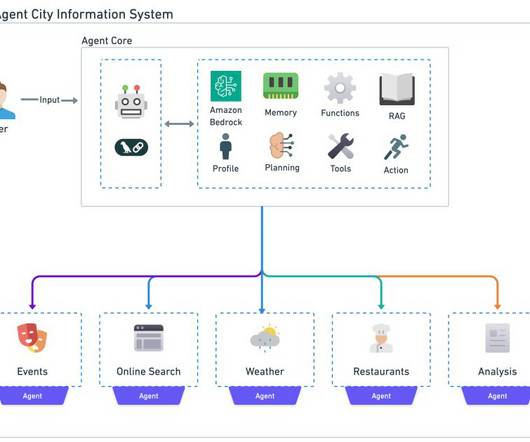
The result is a system that delivers comprehensive details about events, weather, activities, and recommendations for a specified city, illustrating how stateful, multi-agent applications can be built and deployed on Amazon Web Services (AWS) to address real-world challenges.
The database for Process Mining is also establishing itself as an important hub for Data Science and AI applications, as process traces are very granular and informative about what is really going on in the business processes. SAP ERP), the extraction of the data and, above all, the data modeling for the event log.
Unstructured data mobility is not a one-time event, but an opportunity to continually right place data to meet organizational needs. In this contributed article, Krishna Subramanian, COO, president, and co-founder of Komprise, highlights that In the hybrid cloud, AI-enhanced enterprise, unstructured data is everywhere.
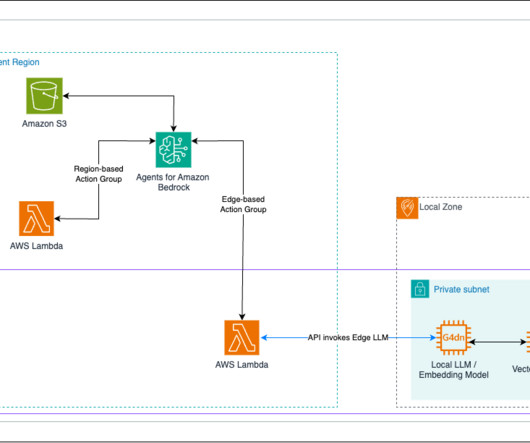
You can use a local vector database either hosted on Amazon Elastic Compute Cloud (Amazon EC2) or using Amazon Relational Database Service (Amazon RDS) for PostgreSQL on the Outpost rack with the pgvector extension to store embeddings. See the following figure for an example.
SQL triggers are like automated routines in a database that execute predefined actions when specific events like INSERT, UPDATE, or DELETE occur in a table. This helps in automating data updation and setting some rules in place. It keeps the data clean and consistent without you having to write extra code every single time.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Error Handling Patterns in Python (Beyond Try-Except) Stop letting errors crash your app.
SirixDB is an embeddable, temporal, evolutionary database system, which uses an append-only approach to store immutable revisions. GitHub - sirixdb/sirix: SirixDB is an embeddable, temporal, evolutionary database system, which uses an append-only approach to store immutable revisions. It keeps the full history of each resource.
In this contributed article, Tom Scott, CEO of Streambased, outlines the path event streaming systems have taken to arrive at the point where they must adopt analytical use cases and looks at some possible futures in this area.
Introduction AWS Lambda Event Notifications allow you to receive notifications when certain events happen in your Amazon S3 bucket. S3 Event Notifications can be used to initiate the Lambda functions, SQS queues, and other AWS services.
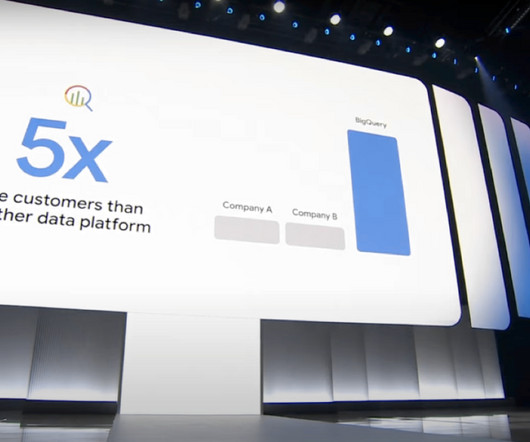
Google Cloud announced a significant number of new features at its Google Cloud Next event last week, with at least 229 new announcements. Buried in that mountain of news, which included new AI chips and agentic AI capabilities, as well as database updates, Google Cloud also made some big moves with
Database Analyst Description Database Analysts focus on managing, analyzing, and optimizing data to support decision-making processes within an organization. They work closely with database administrators to ensure data integrity, develop reporting tools, and conduct thorough analyses to inform business strategies.
Transactional fact tables Transactional fact tables record individual transactions, such as sales events. Database keys associated with fact tables Understanding database keys is essential for relational database architecture, particularly when working with fact tables.
Yet, despite these impressive capabilities, their limitations became more apparent when tasked with providing up-to-date information on global events or expert knowledge in specialized fields. It searches through a vast database that is loaded with the latest information, looking for data related to the user’s query.
Founded out of Berlin in 2021, Qdrant is targeting AI software developers with an open source vector search engine and database for unstructured data, which is an integral part of AI application development particularly as it relates to using real-time data that hasn’t been categorized or labeled. That Qdrant has now raised $7.5
ACID properties stand as cornerstone principles in the realm of transaction processing, ensuring data integrity and reliability in modern databases. ACID properties refer to a set of guidelines that transactions must adhere to within databases, especially in the context of RDBMS.
The available data sources are: Stock Prices Database Contains historical stock price data for publicly traded companies. Analyst Notes Database Knowledge base containing reports from Analysts on their interpretation and analyis of economic events. Stock Prices Database The question is about a stock price.
Introduction Apache Flume is a tool/service/data ingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable. einsteinerupload of.
Introduction Starting with the fundamentals: What is a data stream, also referred to as an event stream or streaming data? At its heart, a data stream is a conceptual framework representing a dataset that is perpetually open-ended and expanding. Its unbounded nature comes from the constant influx of new data over time.
Because training LLMs is a time-consuming process, they do not know about recent events. The library functions as a vector database. This vector allows the system to retrieve the most meaningful information from the vector database. However, they have a major limitation. They lack real-time knowledge. How do we store new data?
Text-to-SQL empowers people to explore data and draw insights using natural language, without requiring specialized database knowledge. Youll find that these features help you tackle enterprise-scale database challenges while making your text-to-SQL experience more robust and efficient.
To further explore this topic, I am surveying real-world serverless, multi-tenant data architectures to understand how different types of systems, such as OLTP databases, real-time OLAP, cloud data warehouses, event streaming systems, and more, implement serverless MT.
The event took place Sept. Always looking forward for a chance to return to my home away from home of Silicon Valley, I jumped at the opportunity to attend my first-ever hardware focused conference, the 2024 AI Hardware and Edge AI put on by Kisaco Research. 9-12, 2024 in beautiful San Jose, Calif., the heart of Silicon Valley.
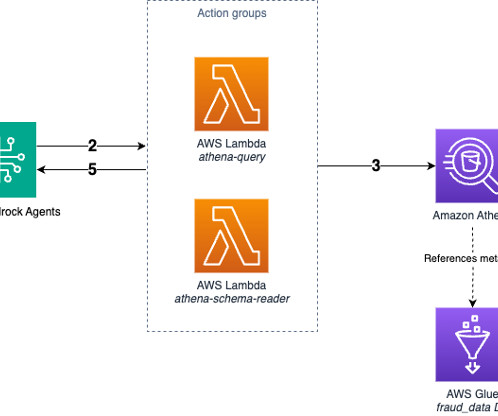
The ingestion pipeline (3) ingests metadata (1) from services (2), including Amazon DataZone, AWS Glue, and Amazon Athena , to a Neptune database after converting the JSON response from the service APIs into an RDF triple format. Run SPARQL queries in the Neptune database to populate additional triples from inference rules.
Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. AWS Lambda is an event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers.
MCP servers are lightweight programs or APIs that expose real-world tools like databases, file systems, or web services to AI models. Big names like Hugging Face and Meta are now running hackathons where participants build MCP servers, clients, and plugins, showing just how hot this space is right now.
Assessing the risk of postoperative cardiovascular events before performing non-cardiac surgery is clinically important. The incidence of major adverse cardiovascular events in the population characterized by the incidence of previous stroke and extremely low LDL-C levels was 15.43
They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. Prompt 2: Were there any major world events in 2016 affecting the sale of Vegetables?
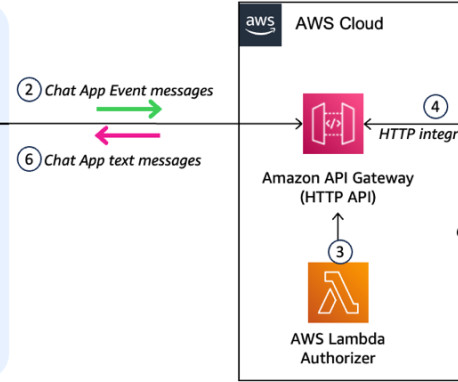
To dispatch interaction events to the solution deployed in this post, Google Chat sends requests to your API Gateway endpoint. First, you will be charged for model inference and for the vector databases you use with Amazon Bedrock Knowledge Bases. The architecture incurs usage cost for several AWS services.
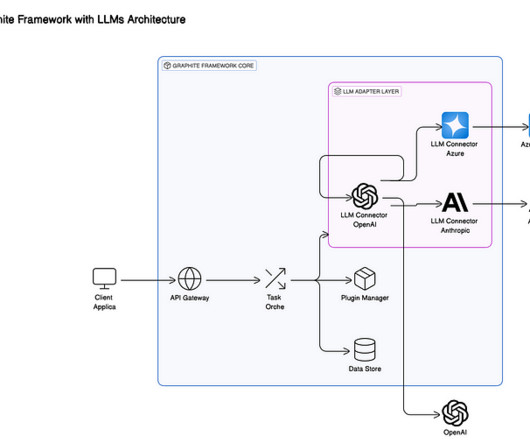
Event-based systems dont just react they forecast. Client Application API Gateway: The first entry point funnels real-world input events into Graphites processing core. Based on incoming event type, past interactions, and memory embeddings, this layer decides what should happen next call a plugin, check a database, or invoke an LLM.
The LLM analyzes the text, identifying key information relevant to the clinical trial, such as patient symptoms, adverse events, medication adherence, and treatment responses. These insights can include: Potential adverse event detection and reporting. Identification of protocol deviations or non-compliance. No problem!
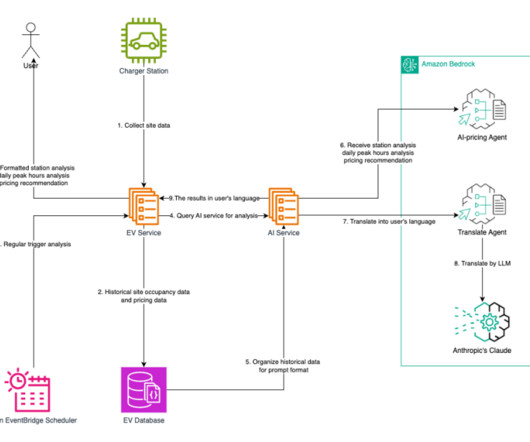
To meet the feature requirements, the system operation process includes the following steps: Charging data is processed through the EV service before entering the database. The charging history data and pricing data are stored in the EV database. Amazon EventBridge Scheduler periodically triggers the EV service to perform analysis.
Summary: Mastering SQL data types improves database efficiency, query performance, and storage management. The blog aims to explore the significant SQL data types, their applications, and how selecting the right type enhances database performance. billion to USD 30.4 billion by 2029 at a CAGR of 10.1%.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content