This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Josep Ferrer , KDnuggets AI Content Specialist on June 10, 2025 in Python Image by Author DuckDB is a fast, in-process analytical database designed for modern data analysis. DuckDB is a free, open-source, in-process OLAP database built for fast, local analytics. Let’s dive in! What Is DuckDB? What Are DuckDB’s Main Features?
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
Introduction Apache CouchDB is an open-source, document-based NoSQL database developed by Apache Software Foundation and used by big companies like Apple, GenCorp Technologies, and Wells Fargo. The post Introduction to Apache CouchDB using Python appeared first on Analytics Vidhya.
py # (Optional) to mark directory as Python package You can leave the __init.py__ file empty, as its main purpose is simply to indicate that this directory should be treated as a Python package. Tools Required(requirements.txt) The necessary libraries required are: PyPDF : A pure Python library to read and write PDF files.
Introduction Elasticsearch is primarily a document-based NoSQL database, meaning developers do not need any prior knowledge of SQL to use it. Still, it is much more than just a NoSQL database. The post Introduction to Elasticsearch using Python appeared first on Analytics Vidhya.
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on June 9, 2025 in Python Image by Author | Ideogram Have you ever spent several hours on repetitive tasks that leave you feeling bored and… unproductive? But you can automate most of this boring stuff with Python. I totally get it. Let’s get started.
Python is a powerful and versatile programming language that has become increasingly popular in the field of data science. NumPy NumPy is a fundamental package for scientific computing in Python. Seaborn Seaborn is a library for creating attractive and informative statistical graphics in Python.
Introduction Large Language Models like langchain and deep lake have come a long way in Document Q&A and information retrieval. However, a […] The post Ask your Documents with Langchain and Deep Lake! These models know a lot about the world, but sometimes, they struggle to know when they don’t know something.
Home Table of Contents Getting Started with Python and FastAPI: A Complete Beginner’s Guide Introduction to FastAPI Python What Is FastAPI? Your First Python FastAPI Endpoint Writing a Simple “Hello, World!” Jump Right To The Downloads Section Introduction to FastAPI Python What Is FastAPI?
That’s where Python comes in. Python is a powerful programming language that offers a wide range of tools and libraries for retrieving, analyzing, and visualizing stock market data. Using Python to retrieve fundamental stock market data – Source: Freepik How to retrieve fundamental stock market data using Python?
Introduction Vector Databases have become the go-to place for storing and indexing the representations of unstructured and structured data. In the ever-evolving landscape of […] The post A Deep Dive into Qdrant, the Rust-Based Vector Database appeared first on Analytics Vidhya.
mlruns This command uses an SQLite database for metadata storage and saves artifacts in the mlruns directory. A project contains: Source code : The Python scripts or notebooks for training and evaluation. Document and Test : Keep thorough documentation and perform unit tests on ML workflows. or evaluate.py.
Introduction In a world filled with information, PDF documents have become a staple for sharing and preserving valuable data. In this article, we introduce you to the […] The post Chat with PDFs | Empowering Textual Interaction with Python and OpenAI appeared first on Analytics Vidhya.
Traditional methods of understanding code structures involve reading through numerous files and documentation, which can be time-consuming and error-prone. Step 5: Initialize the Database Run the following commands to set up the database: chmod +x start-database.sh./start-database.sh message":"Hello from GitDiagram API!"}
Among such tools, today we will learn about the workings and functions of ChromaDB, an open-source vector database to store embeddings from […] The post Build Semantic Search Applications Using Open Source Vector Database ChromaDB appeared first on Analytics Vidhya.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 10 FREE AI Tools That’ll Save You 10+ Hours a Week No tech skills needed.
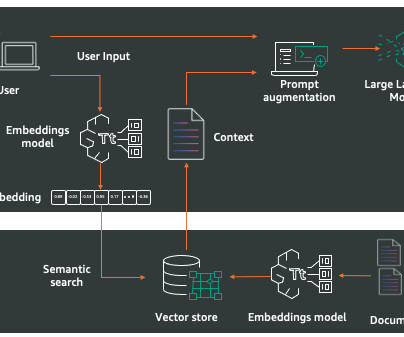
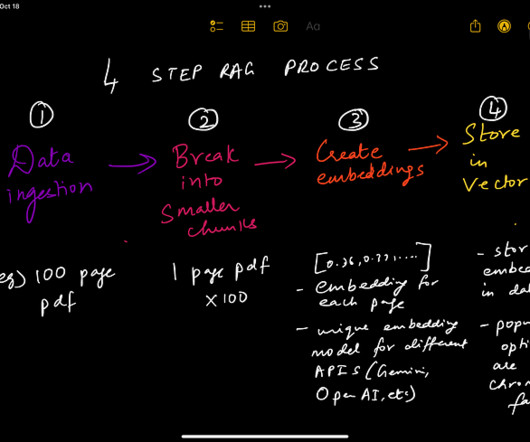
Retrieval Augmented Generation generally consists of Three major steps, I will explain them briefly down below – Information Retrieval The very first step involves retrieving relevant information from a knowledge base, database, or vector database, where we store the embeddings of the data from which we will retrieve information.
One of the fascinating applications of these models is developing custom question-answering or chatbots that draw from personal or organizational data sources. […] The post Building Custom Q&A Applications Using LangChain and Pinecone Vector Database appeared first on Analytics Vidhya.
MCP servers are lightweight programs or APIs that expose real-world tools like databases, file systems, or web services to AI models. Big names like Hugging Face and Meta are now running hackathons where participants build MCP servers, clients, and plugins, showing just how hot this space is right now.
It supports a variety of data sources, including APIs, databases, and PDFs. Key components of LlamaIndex: The key components of LlamaIndex are as follows: Data connectors: These components allow LlamaIndex to ingest data from a variety of sources, such as APIs, databases, and PDFs.
Whether we are analyzing IoT data streams, managing scheduled events, processing document uploads, responding to database changes, etc. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions? appeared first on Analytics Vidhya.
Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities. Using the query embedding and the metadata filter, relevant documents are retrieved from the knowledge base.
While Python and R are popular for analysis and machine learning, SQL and database management are often overlooked. However, data is typically stored in databases and requires SQL or business intelligence tools for access. In this guide, we provide a comprehensive overview of various types of databases and their differences.
Introduction MongoDB is a free open-source No-SQL documentdatabase. ArticleVideo Book This article was published as a part of the Data Science Blogathon. The post How To Create An Aggregation Pipeline In MongoDB appeared first on Analytics Vidhya.
Python is a versatile programming language known for its simplicity and readability. If you’re looking to sharpen your Python skills and take on exciting projects, we’ve compiled a list of 16 Python projects that cover various domains, including communication, gaming, management systems, and more.
Software engineering skills: familiarity with Python, virtual environments, and package installation. Python libraries: comfort importing and using packages and file I/O. If any of these are new, consider reviewing a quick Python tutorial or AI primer before proceeding. It scores documents based on: 1.
Workflow Automation: Connect any two apps or websites and automate tasks without integrations, perfect for auto filling forms, updating databases, or sending messages. PDF Data Extraction: Upload a document, highlight the fields you need, and Magical AI will transfer them into online forms or databases, saving you hours of tedious work.
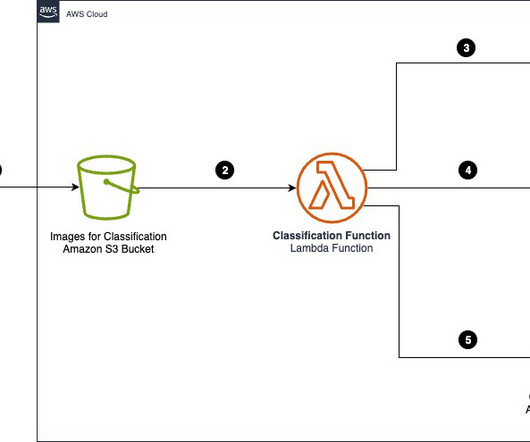
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
Harrison Chase’s brainchild, LangChain, is a Python library designed to help you leverage the power of LLMs to build custom NLP applications. Document Loaders and Utils: LangChain’s Document Loaders and Utils modules simplify data access and computation. PyPDF2: Python library used to read and manipulate PDF files.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
This content builds on posts such as Deploy a Slack gateway for Amazon Bedrock by adding integrations to Amazon Bedrock Knowledge Bases and Amazon Bedrock Guardrails, and the Bolt for Python library to simplify Slack message acknowledgement and authentication requirements. Chunks are vectorized and stored in a vector database.
One of the fields of professionals that are so important for data science projects are Python developers. What is the Python programming language? What Is Python? Python is a powerful programming language that is widely used in many different industries today. million Python developers in the world today!
Agent architecture The following diagram illustrates the serverless agent architecture with standard authorization and real-time interaction, and an LLM agent layer using Amazon Bedrock Agents for multi-knowledge base and backend orchestration using API or Python executors. Domain-scoped agents enable code reuse across multiple agents.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
This centralized system consolidates a wide range of data sources, including detailed reports, FAQs, and technical documents. The system integrates structured data, such as tables containing product properties and specifications, with unstructured text documents that provide in-depth product descriptions and usage guidelines.
Today, we’re introducing the new capability to chat with your document with zero setup in Knowledge Bases for Amazon Bedrock. With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data.
In this blog post, I’ll walk you through the process of creating a simple interactive question-answering application using Python, Gemini Flash Pro API, LangChain, and Gradio. A beginner friendly introduction and application of RAG As an amateur photographer, I am experimenting with ways I can use generative AI to get better at my craft.
For businesses, RAG offers a powerful way to use internal knowledge by connecting company documentation to a generative AI model. When an employee asks a question, the RAG system retrieves relevant information from the company’s internal documents and uses this context to generate an accurate, company-specific response.
Streamlit is an open source framework for data scientists to efficiently create interactive web-based data applications in pure Python. Solution overview This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base.
In the illustration below, we are showing how different types of applications can access a database using REST API. The GET method is idempotent, which means that multiple identical requests will have the same effect as a single request. Example Code: ‘requests’ is a Python library used for making HTTP requests in Python.
RAG helps models access a specific library or database, making it suitable for tasks that require factual accuracy. What is Retrieval-Augmented Generation (RAG) and when to use it Retrieval-Augmented Generation (RAG) is a method that integrates the capabilities of a language model with a specific library or database.
These diagrams serve as essential communication tools for stakeholders, documentation of compliance requirements, and blueprints for implementation teams. Set up your environment Before you can start creating diagrams, you need to set up your environment with Amazon Q CLI, the AWS Diagram MCP server, and AWS Documentation MCP server.
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. As the global Python market is projected to reach USD 100.6
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content