This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Get a Demo DATA + AI SUMMIT JUNE 9–12 | SAN FRANCISCO Data + AI Summit is almost here — don’t miss the chance to join us in San Francisco! Modern development workflow : Branching a database should be as easy as branching a code repository, and it should be near instantaneous. REGISTER Ready to get started?
Get a Demo DATA + AI SUMMIT JUNE 9–12 | SAN FRANCISCO Data + AI Summit is almost here — don’t miss the chance to join us in San Francisco! REGISTER Ready to get started? This approach democratizes agent development, allowing domain experts to contribute directly to system improvement without deep technical expertise in AI infrastructure.
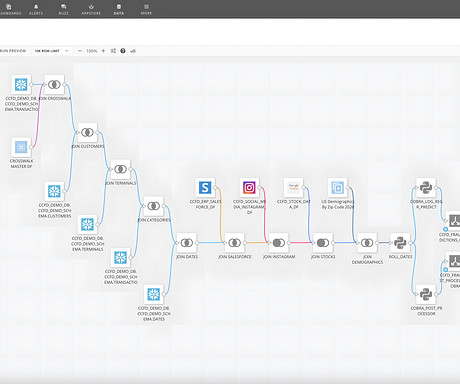
Recapping the Cloud Amplifier and Snowflake Demo The combined power of Snowflake and Domo’s Cloud Amplifier is the best-kept secret in data management right now — and we’re reaching new heights every day. If you missed our demo, we dive into the technical intricacies of architecting it below. Instagram) used in the demo Why Snowflake?
We also offer hosted and on-premise versions with OCR, extra metadata, all embedding providers, and managed vector databases for teams that want a fully managed pipeline. or book a demo: https://cal.com/shreyashn/chonkie-demo. 200k+ tokens) with many SQL snippets, query results and database metadata (e.g.
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
The assistant is connected to internal and external systems, with the capability to query various sources such as SQL databases, Amazon CloudWatch logs, and third-party tools to check the live system health status. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
Data engineers can create and manage extract, transform, and load (ETL) pipelines directly within Unified Studio using Visual ETL. For Project name , enter a name (for example, demo ). Expand your database starting from glue_db_. The admin also publishes the data to SageMaker Catalog in SageMaker Lakehouse.
With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources. Under Quick setup settings , for Name , enter a name (for example, demo). For Project name , enter a name (for example, demo). Expand your database starting from glue_db_. Choose Continue. option("multiLine", "true").option("header",
The general perception is that you can simply feed data into an embedding model to generate vector embeddings and then transfer these vectors into your vector database to retrieve the desired results. how to perform a vector search Many vector database providers promote their capabilities with descriptors like easy, user-friendly, and simple.
It’s a foundational skill for working with relational databases Just about every data scientist or analyst will have to work with relational databases in their careers. Another boon for efficient work that SQL provides is its simple and consistent syntax that allows for collaboration across multiple databases.
As you can see in the above demo, it is incredibly simple to use INFER_SCHEMA and SCHEMA EVOLUTION features to speed up data ingestion into Snowflake. There’s no need for developers or analysts to manually adjust table schemas or modify ETL (Extract, Transform, Load) processes whenever the source data structure changes.
The evolution of Presto at Uber Beginning of a data analytics journey Uber began their analytical journey with a traditional analytical database platform at the core of their analytics. They stood up a file-based data lake alongside their analytical database. Uber has made the Presto query engine connect to real-time databases.
The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. for the popular database SQL Server. In Alation, lineage provides added advantages of being able to add data flow objects, such as ETL transformations, perform impact analysis, and manually edit lineage.
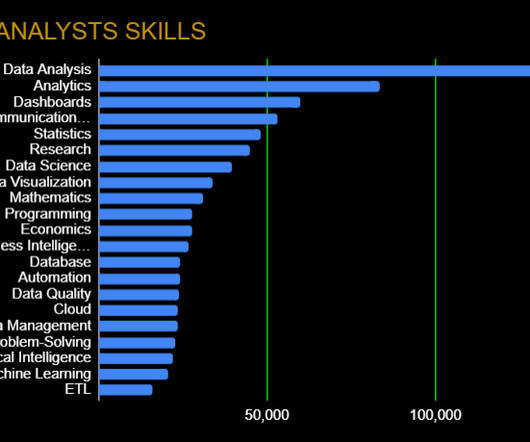
Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential. Cloud Services: Google Cloud Platform, AWS, Azure.
There was a software product demo showcasing its ability to scan every layer of your application code, and I was intrigued to see how it worked. The product collected an impressive amount of metadata, from the user interface to the database structure. At the time, I was at a technology conference.
Reading & executing from.sql scripts We can use.sql files that are opened and executed from the notebook through a database connector library. connection_params: A dictionary containing PostgreSQL connection parameters, such as 'host', 'port', 'database', 'user', and 'password'.
Get a Demo DATA + AI SUMMIT Data + AI Summit Happening Now Watch the free livestream of the keynotes! Join now Ready to get started? The design draws on years of observing real-world Apache Spark workloads, codifying what we’ve learned into a declarative API that covers the most common patterns - including both batch and streaming flows.
Applications may draw data from different databases, sometimes in different formats. Creating a sustainable data culture means efficiently and accurately integrating data to help prevent future silos, either through the use of scripting or Extract, Transform and Load (ETL) tools. ??Using Subscribe to Alation's Blog.
We can then give you a demo, learn more about your monitoring needs, and help you to deploy or customize a solution for your organization. Tasks can be used to automate data processing workflows, such as ETL jobs, data ingestion, and data transformation. SQL commands allow users to create, modify, suspend, resume, and drop tasks.
SQL stands for Structured Query Language, essential for querying and manipulating data stored in relational databases. The SELECT statement retrieves data from a database, while SELECT DISTINCT eliminates duplicate rows from the result set. Data Warehousing and ETL Processes What is a data warehouse, and why is it important?
Vector Database : A vector database is a specialized database designed to efficiently store, manage, and retrieve high-dimensional vectors, also known as vector embeddings. Vector databases support similarity search operations, allowing users to find vectors most similar to a given query vector.
I'm JD, a Software Engineer with experience touching many parts of the stack (frontend, backend, databases, data & ETL pipelines, you name it). With over 3 years of working with ETL pipelines and REST API integrations and development, I understand how to develop and maintain robust and scalable data systems.
You can bring data from operational databases and applications into your lakehouse in near real time through zero-ETL integrations. To access RMS backed catalog databases from Spark, each RMS database requires its own Spark session catalog configuration. For Project name , enter demo. and Amazon EMR 7.5.0
Get a Demo Login Try Databricks Blog / Data Warehousing / Article Databricks at SIGMOD 2025 Databricks is proud to be a platinum sponsor of SIGMOD 2025 in Berlin, Germany. Accepted Demo Papers Blink twice - automatic workload pinning and regression detection for Versionless Apache Spark using retries.
I've built the archival and database software on Lucee & MySQL to store images and automate, and I use OpenAI to analyze images and extra meta data. Demos & tutorials: Harness Builder → https://www.youtube.com/watch?v=JfQVB_iTD1I Both are in a pretty rough state, but usable for the intrepid.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content