This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Database replication is a crucial process that ensures data is consistently available across various systems and locations. What is database replication? Database replication involves creating copies of data across different servers or databases, which ensures that all users and applications have access to the same data at all times.
This type of data maintains a clear structure, usually in rows and columns, which makes it easy to store and retrieve using database systems. Definition and characteristics of structured data Structured data is typically characterized by its organization within fixed fields in databases.
For instance, a sales department may maintain its own database that is incompatible with the accounting department’s system. This can involve creating a unified database accessible to all relevant stakeholders. The post Understanding Data Silos: Definition, Challenges, and Solutions appeared first on Pickl.AI.
An approach to requirements definition for vibe coding is using a language model to help produce a production requirements document (PRD). This is perhaps the most significant departure from the casual definition of vibe coding. For the category column, fill any missing values with the string unknown. Return the cleaned DataFrame.
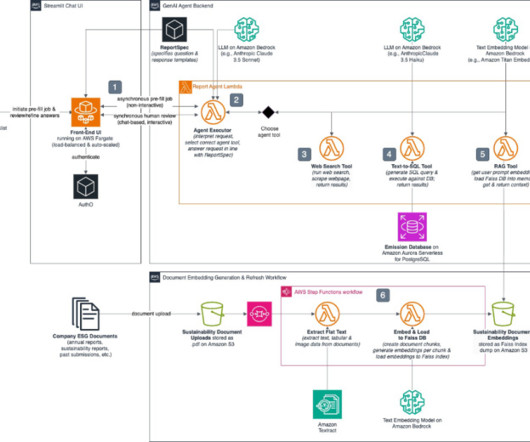
Data for a single report includes thousands of data points from a multitude of sources including official documentation, databases, unstructured document stores, utility bills, and emails. Report GenAI pre-fills reports by drawing on existing databases, document stores and web searches. on Amazon Bedrock.
We also offer hosted and on-premise versions with OCR, extra metadata, all embedding providers, and managed vector databases for teams that want a fully managed pipeline. 200k+ tokens) with many SQL snippets, query results and database metadata (e.g. Your private database for all ai interactions. table and column info).
It also provides capabilities for ETL (Extract, Transform, Load) and Reverse ETL processes. Pre-Requisites Below are a few of the most important, but not exhaustive, list of prerequisites required to start using the connector: For an on-premises PostgreSQL database, set the wal_level to logical.
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETL pipeline orchestration. ETL ProcessBasics So what exactly is ETL? filling missing values with AI predictions).
The ETL (extract, transform, and load) technology market also boomed as the means of accessing and moving that data, with the necessary translations and mappings required to get the data out of source schemas and into the new DW target schema. Business glossaries and early best practices for data governance and stewardship began to emerge.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
Summary: This comprehensive guide delves into the structure of Database Management System (DBMS), detailing its key components, including the database engine, database schema, and user interfaces. Database Management Systems (DBMS) serve as the backbone of data handling.
Summary: Choosing the right ETL tool is crucial for seamless data integration. At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. What is ETL?
To keep myself sane, I use Airflow to automate tasks with simple, reusable pieces of code for frequently repeated elements of projects, for example: Web scraping ETLDatabase management Feature building and data validation And much more! link] We finally have the definition of the DAG. What’s Airflow, and why’s it so good?
In this article, we will delve into the concept of data lakes, explore their differences from data warehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Before we address the questions, ‘ What is data version control ?’ and ‘Why is it important for data lakes?’
Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks. The following figure shows schema definition and model which reference it. This can be achieved by enabling the awslogs log driver within the logConfiguration parameters of the task definitions.
- a beginner question Let’s start with the basic thing if I talk about the formal definition of Data Science so it’s like “Data science encompasses preparing data for analysis, including cleansing, aggregating, and manipulating the data to perform advanced data analysis” , is the definition enough explanation of data science?
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Data Architect Designs complex databases and blueprints for data management systems.
The processed output is stored in a database or data warehouse, such as Amazon Relational Database Service (Amazon RDS). It can automate extract, transform, and load (ETL) processes, so multiple long-running ETL jobs run in order and complete successfully without manual orchestration.
A quick search on the Internet provides multiple definitions by technology-leading companies such as IBM, Amazon, and Oracle. The Datamart’s data is usually stored in databases containing a moving frame required for data analysis, not the full history of data.
These components include various things like; what kind of sources of data will one do their analysis on, the ETL processes involved, and where it would store large-scale information among others. If you follow all these tips, then definitely you will have a well-designed and optimized data warehouse as per your business requirements.
Additionally, using spatial joins lets you show the relationships between data with varying spatial definitions. Hyper Supercharge your analytics with in-memory data engine Hyper is Tableau's blazingly fast SQL engine that lets you do fast real-time analytics, interactive exploration, and ETL transformations through Tableau Prep.
The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. A business glossary is critical to aligning an organization around the definition of business terms. Robust data governance starts with understanding the definition of data. Open Data Quality Initiative.
Unlike operational databases focused on daily tasks, data warehouses are designed for analysis, enabling historical trend exploration and informed decision-making. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture. ETL tools act like skilled miners , extracting data from various source systems.
Reverse ETL tools. The modern data stack is also the consequence of a shift in analysis workflow, fromextract, transform, load (ETL) to extract, load, transform (ELT). A Note on the Shift from ETL to ELT. In the past, data movement was defined by ETL: extract, transform, and load. Extract, load, Transform (ELT) tools.
One Data Engineer: Cloud database integration with our cloud expert. ” Hence the very first thing to do is to make sure that the data being used is of high quality and that any errors or anomalies are detected and corrected before proceeding with ETL and data sourcing. We primarily used ETL services offered by AWS.
There’s no need for developers or analysts to manually adjust table schemas or modify ETL (Extract, Transform, Load) processes whenever the source data structure changes. The Snowflake account is set up with a demo database and schema to load data. Click on +Files button to upload the sample files.
Extraction, transformation and loading (ETL) tools dominated the data integration scene at the time, used primarily for data warehousing and business intelligence. The first two use cases are primarily aimed at a technical audience, as the lineage definitions apply to actual physical assets.
While traditional data warehouses made use of an Extract-Transform-Load (ETL) process to ingest data, data lakes instead rely on an Extract-Load-Transform (ELT) process. This adds an additional ETL step, making the data even more stale. data platforms and databases), all interacting with one another to provide greater value.
As an example, an IT team could easily take the knowledge of database deployment from on-premises and deploy the same solution in the cloud on an always-running virtual machine. Data Processing: Snowflake can process large datasets and perform data transformations, making it suitable for ETL (Extract, Transform, Load) processes.
As a result, we are presented with specialized data platforms, databases, and warehouses. Platform and More dbt is a database deployment & development platform. It is version-controlled and scalable, maintains referential integrity, and tests/deploys database objects. Today, the MDS is composed of multiple players.
Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes. A Lake Formation database populated with the TPC data. internal in the certificate subject definition. When you’re connected, you can interactively view a database tree and table preview or schema.
Document Hierarchy Structures Maintain thorough documentation of hierarchy designs, including definitions, relationships, and data sources. Avoid excessive levels that may slow down query performance. Instead, focus on the most relevant levels for analysis. This documentation is invaluable for future reference and modifications.
Document and Communicate Maintain thorough documentation of fact table designs, including definitions, calculations, and relationships. Establish data governance policies and processes to ensure consistency in definitions, calculations, and data sources. Consider factors such as data volume, query patterns, and hardware constraints.
Definition and Explanation of Data Pipelines A data pipeline is a series of interconnected steps that ingest raw data from various sources, process it through cleaning, transformation, and integration stages, and ultimately deliver refined data to end users or downstream systems.
Definition and Core Components Microsoft Fabric is a unified solution integrating various data services into a single ecosystem. Data Factory : Simplifies the creation of ETL pipelines to integrate data from diverse sources. Definition and Functionality Power BI is much more than a tool for creating charts and graphs.
It also includes the mapping definition to construct the input for the specified AI service. The notifications Lambda will get the information related to the prediction ID from DynamoDB, update the entry with status value to “completed” or “error,” and perform the necessary action depending on the callback mode saved in the database record.
For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly. Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. mp4,webm, etc.), and audio files (.wav,mp3,acc,
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
While dealing with larger quantities of data, you will likely be working with Data Engineers to create ETL (extract, transform, load) pipelines to get data from new sources. You will need to learn to query different databases depending on which ones your company uses.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. I term it as a feature definition store. How is DAGWorks different from other popular solutions? Stefan: You’re exactly right.
Vector Database : A vector database is a specialized database designed to efficiently store, manage, and retrieve high-dimensional vectors, also known as vector embeddings. Vector databases support similarity search operations, allowing users to find vectors most similar to a given query vector.
You may also like Building a Machine Learning Platform [Definitive Guide] Consideration for data platform Setting up the Data Platform in the right way is key to the success of an ML Platform. 2 It also helps to standardize feature definitions across teams.
This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. Business-Focused Operation Model: Teams can shed countless hours of managing long-running and complex ETL pipelines that do not scale. This noticeably saves time on copying and drastically reduces data storage costs.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content