This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Well grab data from a CSV file (like youd download from an e-commerce platform), clean it up, and store it in a proper database for analysis. Step 3: Load In a real project, you might be loading into a database, sending to an API, or pushing to cloud storage. Here, were loading our clean data into a proper SQLite database.
His company’s tool, a relational foundation model (RFM), is a new kind of pre-trained AI that brings the “zero-shot” capabilities of large language models (LLMs) to structured databases. How Kumo is generalizing transformers for databases Kumo’s approach, “relational deeplearning,” sidesteps this manual process with two key insights.
Key Skills: Mastery in machine learning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods. Stanford AI Lab recommends proficiency in deeplearning, especially if working in experimental or cutting-edge areas.
Ideal for data scientists and engineers working with databases and complex data models. Awesome Data Science: Learn and Apply Data Science Link: academic/awesome-datascience An open-source repository that helps you learn data science from the beginning and also assists you in building a strong portfolio by working on real-life problems.
Vector Databases and Embedding Strategies : RAG systems rely on semantic search to find relevant information, requiring documents converted into vector embeddings that capture meaning rather than keywords. Vector Database Solutions store and search the embeddings that power RAG systems.
Relational Graph Transformers represent the next evolution in Relational DeepLearning, allowing AI systems to seamlessly navigate and learn from data spread across multiple tables.
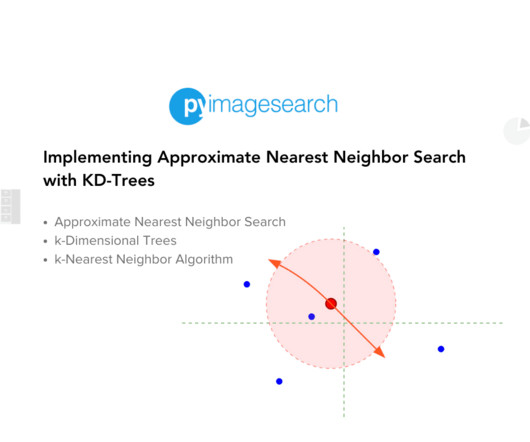
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. Imagine a database with billions of samples ( ) (e.g., So, how can we perform efficient searches in such big databases? These scenarios demand efficient algorithms to process and retrieve relevant data swiftly.
I have given a few resources that might help you learn NLP: Coursera: DeepLearning.AI Natural Language Processing Specialization - Focuses on NLP techniques and applications (Recommended) Stanford CS224n (YouTube): Natural Language Processing with DeepLearning - A comprehensive lecture series on NLP with deeplearning.
Fast forward a few years, and as deeplearning explodes in popularity, NVIDIA creates cuDNN, a specialized library built on top of CUDA that’s specifically designed to make neural networks run faster than a caffeinated cheetah. It’s the Swiss Army knife of GPU computing cuDNN: Specialized for deeplearning operations only.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
This process was inspired by our success working with Databricks on our deeplearning frameworks. This is particularly important given the diversity of referral forms and the need for compliance within heavily regulated EHR environments like Epic. While we use Azure AI Document Intelligence for OCR and OpenAI’s GPT-4.0
Cybersecurity professionals validate database configurations before processing valuable data, scan the codebase of new applications before their release, investigate incidents, and identify root causes, among other tasks. Since DL falls under ML, this discussion will primarily focus on machine learning.
Trainium chips are purpose-built for deeplearning training of 100 billion and larger parameter models. Model training on Trainium is supported by the AWS Neuron SDK, which provides compiler, runtime, and profiling tools that unlock high-performance and cost-effective deeplearning acceleration.
Harnessing the power of deeplearning , these advanced AI systems can read, interpret, and generate human-like language at remarkable scale. Large Language Models (LLMs) process and understand human language using advanced deeplearning techniques—primarily transformers. How Do LLMs Work? Generate code for integrations.
Currently in my job, I face challenges like looking for databases, harmonizing and incorporating them into our AI pipelines. Daniel : I got started in data science during the last years of my undergraduate studies, where I first learned about machine learning.
SQL remains crucial for database querying, especially given India’s large IT services ecosystem. Machine Learning & AI: Hands-on experience with supervised and unsupervised algorithms, deeplearning frameworks (TensorFlow, PyTorch), and natural language processing (NLP) is highly valued.
Built-in Dependency Injection FastAPI provides a powerful dependency injection system, making it easy to manage shared resources like databases, authentication services, and configuration settings. Adding a POST Request Endpoint A POST request is used to create new resources, such as adding a new item to a database. Thats not the case.
The following question requires complex industry knowledge-based analysis of data from multiple columns in the ETF database. The results are similar to fine-tuning LLMs without the complexities of fine-tuning models. Use case examples Let’s look at a few sample prompts with generated analysis.
To address this, machine learning models attempt to predict how genes will behave under perturbation before actually conducting experiments. These models use knowledge graphs databases of known biological interactionsto infer how a new gene disruption might affect a cell.
This model makes predictions while receiving streaming inputs and predictions are stored in a database. The retailer might evolve their recommendation system to incorporate deeplearning models that consider user browsing history, demographic data, and current trends. using Kafka, Kinesis, or a queue type of input).
Amazon Redshift is a database optimized for online analytical processing (OLAP), which generally entails analyzing large amounts of data and performing complex analysis, as might be done by analysts looking at historical stock prices. Finance domain The Finance domain has two tables: Stock Price and Research Budgets.
DeepSeek AI is an advanced AI genomics platform that allows experts to solve complex problems using cutting-edge deeplearning, neural networks, and natural language processing (NLP). DeepSeek AI can learn and improve over time, as opposed to being governed by static, pre-defined principles. Lets begin! What is DeepSeek AI?
SageMaker AI provides distributed training libraries and supports various distributed training options for deeplearning tasks. Expand your database starting from glue_db_. For this post, we use the PyTorch framework and use Hugging Face open source FMs for fine-tuning. Under Lakehouse , expand AwsDataCatalog.
Fine-Tuning Techniques: Fine-tuning adjusts the model’s internal parameters based on the retrieved knowledge, enhancing its ability to produce accurate and contextually appropriate outputs.
This approach consists of the following parameters: Model definition We define a sequential deeplearning model using the Keras library from TensorFlow. It boasts advanced capabilities like chat with data, advanced Retrieval Augmented Generation (RAG), and agents, enabling complex tasks such as reasoning, code execution, or API calls.
Adaptive RAG Systems with Knowledge Graphs: Building Reinforcement-Learning-Driven AI Applications David vonThenen, Senior AI/ML Engineer at DigitalOcean Learn how to build self-improving RAG systems by combining knowledge graphs with reinforcement learning for smarter, more dynamic AI applications.
These systems leverage extensive knowledge databases to provide informed recommendations and solutions. Machine learning Machine learning involves analyzing data to develop algorithms that enhance over time. This self-improvement allows machines to make increasingly accurate decisions as they assimilate new information.
He focuses on building deeplearning-based AI and computer vision solutions for AWS customers. This modular approach simplifies maintenance, updates, and scalability of your AI applications. Shubham also has a background in building distributed, scalable, high-volume-high-throughput systems in IoT architectures.
This skill simplifies the data extraction process, allowing security analysts to conduct investigations more efficiently without requiring deep technical knowledge. Given a database schema, the model is provided with three examples pairing a natural-language question with its corresponding SQL query.
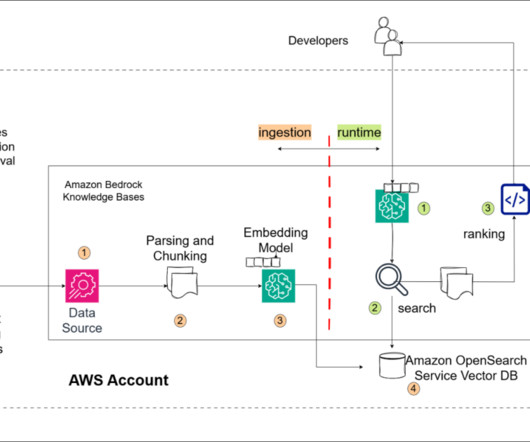
This involved creating a pipeline for data ingestion, preprocessing, metadata extraction, and indexing in a vector database. Similarity search and retrieval – The system retrieves the most relevant chunks in the vector database based on similarity scores to the query.
Course information: 86+ total classes 115+ hours hours of on-demand code walkthrough videos Last updated: May 2025 4.84 (128 Ratings) 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computer vision and deeplearning. Or has to involve complex mathematics and equations?
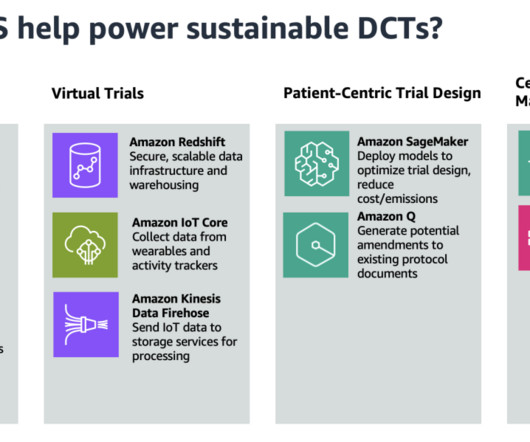
According to sources from government databases and research institutions, there are around 300,000–600,000 clinical trials conducted globally each year, amplifying this impact by several hundred thousand times. With a centralized data lake, organizations can avoid the duplication of data across separate trial databases.
Ragas can be used to evaluate the performance of an information retriever (the component that retrieves relevant information from a database) using metrics like context precision and recall. About the Authors Deepak Dalakoti, PhD, is a DeepLearning Architect at the Generative AI Innovation Centre in Sydney, Australia.
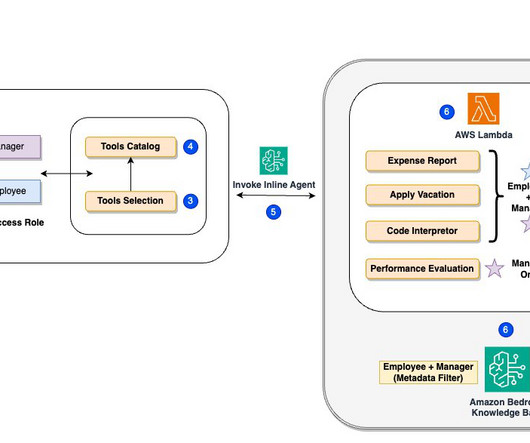
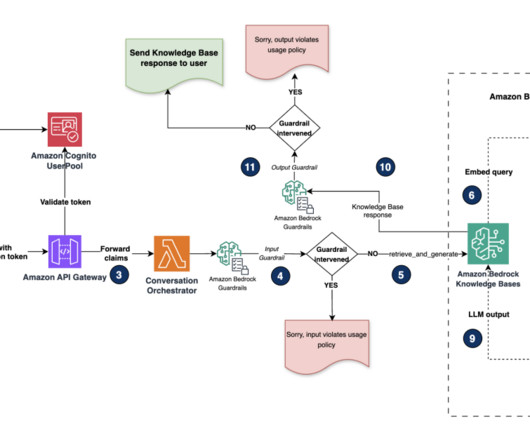
The following diagram illustrates how RBAC works with metadata filtering in the vector database. Amazon Bedrock Knowledge Bases performs similarity searches on the OpenSearch Service vector database and retrieves relevant chunks (optionally, you can improve the relevance of query responses using a reranker model in the knowledge base).
LLMs are those trained on a large amount of text data, using deeplearning technology to grasp the statistical relationship between words, sentences, and other elements of language. Some of these systems cross-check the responses with the trusted database or source. It uses the transformer architecture.
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Association rule mining Association rule mining identifies interesting relations between variables in large databases.
This work has practical implications for AI systems that rely on private database searches or real-time regression, enabling them to provide useful results while safeguarding sensitive information from attackers.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases.
Just as a judge relies on a clerk to pull specific case files before making a decision, an LLM with RAG can query databases or documents in real time to support its compliance decisions. By organizing compliance data into a graph, the system captures context and connections that linear text databases might miss. as a regulation node).
Can we learn a foundation model for time series and interrogate them with a chatbot, reason over them with intelligent agents, and perform other useful applications of Generative AI? In this post and accompanying notebook , we examine recent work on foundation models for time series, focusing on one model in particular: TimesFM (Das et al.,
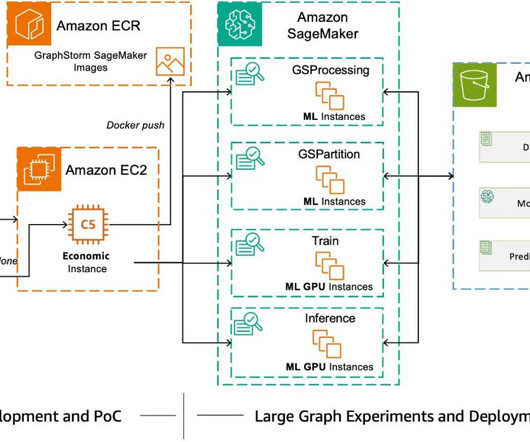
Xiang Song is a Senior Applied Scientist at Amazon Web Services, where he develops deeplearning frameworks including GraphStorm, DGL, and DGL-KE. He led the development of Amazon Neptune ML, a new capability of Neptune that uses graph neural networks for graphs stored in a Neptune graph database.
AI at Qualtrics Qualtrics has a deep history of using advanced ML to power its industry-leading experience management platform. Early 2020, with the push for deeplearning and transformer models, Qualtrics created its first enterprise-level ML platform called Socrates.
The questions require deep domain knowledge in various verticals; they are unambiguous and resistant to simple internet lookups or database retrieval. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks. Start with H=84.nnEach
Previously, as Director of AI Engineering at Clearbit, he transformed AI into a core profit driver, growing a thriving user base and spearheading advancements in large-scale vector databases. His team also put Meta’s first deeplearning model on-device.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content