This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hadoop has become synonymous with big data processing, transforming how organizations manage vast quantities of information. As businesses increasingly rely on data for decision-making, Hadoop’s open-source framework has emerged as a key player, offering a powerful solution for handling diverse and complex datasets.
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Hadoop systems and data lakes are frequently mentioned together.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around data lakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with data lakes. DataWarehouse.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. Hadoop, Snowflake, Databricks and other products have rapidly gained adoption.
Furthermore, it has been estimated that by 2025, the cumulative data generated will triple to reach nearly 175 zettabytes. Demands from business decision makers for real-time data access is also seeing an unprecedented rise at present, in order to facilitate well-informed, educated business decisions.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ?
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
Big data engineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on big data to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
Familiarize yourself with essential data technologies: Data engineers often work with large, complex data sets, and it’s important to be familiar with technologies like Hadoop, Spark, and Hive that can help you process and analyze this data.
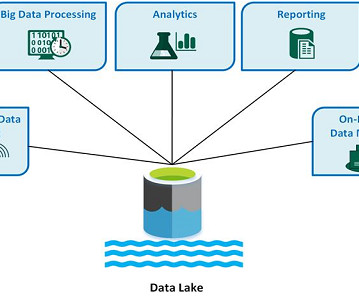
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
Introduction to Big Data Tools In todays data-driven world, organisations are inundated with vast amounts of information generated from various sources, including social media, IoT devices, transactions, and more. Big Data tools are essential for effectively managing and analysing this wealth of information.
Understanding Data Engineering Data engineering is collecting, storing, and organising data so businesses can use it effectively. It involves building systems that move and transform raw data into a usable format. Without data engineering , companies would struggle to analyse information and make informed decisions.
Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and big data frameworks (Hadoop, Apache Spark).
It’s no longer enough to build the datawarehouse. Dave Wells, analyst with the Eckerson Group suggests that realizing the promise of the datawarehouse requires a paradigm shift in the way we think about data along with a change in how we access and use it.
The goal is to ensure that data is available, reliable, and accessible for analysis, ultimately driving insights and informed decision-making within organisations. Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights.
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a datawarehouse or a database. In the extraction phase, the data is collected from various sources and brought into a staging area.
With the explosive growth of big data over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its big data pipeline.
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. And you should have experience working with big data platforms such as Hadoop or Apache Spark. Your skill set should include the ability to write in the programming languages Python, SAS, R and Scala.
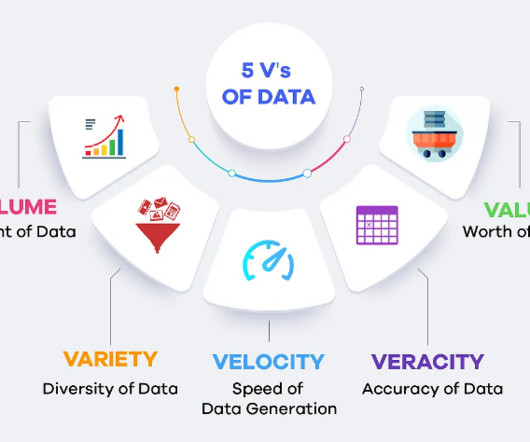
Volume It refers to the sheer amount of data generated daily, which can range from terabytes to petabytes. Organisations must develop strategies to store and manage this vast amount of information effectively. Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
Summary: Understanding Business Intelligence Architecture is essential for organizations seeking to harness data effectively. This framework includes components like data sources, integration, storage, analysis, visualization, and information delivery. Data Lakes: These store raw, unprocessed data in its original format.
Data has to be stored somewhere. Datawarehouses are repositories for your cleaned, processed data, but what about all that unstructured data your organization is starting to notice? What is a data lake? Delta Lake Delta Lake is the first open-source data lakehouse architecture service on this list.
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. Role of Data Scientists Data Scientists are the architects of data analysis.
It moves beyond the vast amount of data to discover patterns and stories hidden inside. By leveraging big data, organizations and institutions can uncover valuable insights, predict trends, and make informed decisions that significantly influence their strategic directions and operational efficiencies.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital. Also Read: Top 10 Data Science tools for 2024. What is ETL?
They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. This involves working closely with data analysts and data scientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making.
It covers best practices for ensuring scalability, reliability, and performance while addressing common challenges, enabling businesses to transform raw data into valuable, actionable insights for informed decision-making. As stated above, data pipelines represent the backbone of modern data architecture.
They set up a couple of clusters and began processing queries at a much faster speed than anything they had experienced with Apache Hive, a distributed datawarehouse system, on their data lake. It can ingest data from offline batch data sources (such as Hadoop and flat files) as well as online data sources (such as Kafka).
Walking you through the biggest challenges we have found when migrating our customer’s data from a legacy system to Snowflake. Background Information on Migrating to Snowflake So you’ve decided to move from your current data warehousing solution to Snowflake, and you want to know what challenges await you.
It requires data science tools to first clean, prepare and analyze unstructured big data. Machine learning can then “learn” from the data to create insights that improve performance or inform predictions. Data from various sources, collected in different forms, require data entry and compilation.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? We only have the video without any information.
With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration. Overview In the era of Big Data , organizations inundated with vast amounts of information generated from various sources.
As a result, Gartner estimates that poor data quality costs organizations an average of $13 million annually. High-quality data significantly reduces the risk of costly errors, and the resulting penalties or legal issues. Completeness determines whether all required data fields are filled with appropriate and valid information.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content