This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Abid Ali Awan , KDnuggets Assistant Editor on July 14, 2025 in Python Image by Author | Canva Despite the rapid advancements in data science, many universities and institutions still rely heavily on tools like Excel and SPSS for statistical analysis and reporting. Learn more: [link] 3.
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
Well grab data from a CSV file (like youd download from an e-commerce platform), clean it up, and store it in a proper database for analysis. You grab data from somewhere (Extract), clean it up and make it better (Transform), then put it somewhere useful (Load). Here, were loading our clean data into a proper SQLite database.
By Josep Ferrer , KDnuggets AI Content Specialist on June 10, 2025 in Python Image by Author DuckDB is a fast, in-process analytical database designed for modern data analysis. DuckDB is a free, open-source, in-process OLAP database built for fast, local analytics. Let’s dive in! What Is DuckDB? What Are DuckDB’s Main Features?
Both follow the same principles: processing large volumes of data efficiently and ensuring it is clean, consistent, and ready for use. Data can arrive in batches (hourly reports) or as real-time streams (live web traffic). How will you ensure data completeness and consistency?
Summary: In 2025, datascientists in India will be vital for data-driven decision-making across industries. It highlights the growing opportunities and challenges in India’s dynamic data science landscape. Key Takeaways Datascientists in India require strong programming and machine learning skills for diverse industries.
Ready-to-Use Libraries for (Almost) Every Data Task The language offers popular libraries for almost every data task youll work on — from data cleaning, manipulation, visualization, and building machine learning models. We outline must-know data science libraries in 10 Python Libraries Every DataScientist Should Know.
DuckDB is an SQL database that you can run right in your notebook. Unlike other SQL databases, you don’t need to configure the server. We also did this using a real-life data project that Uber requested in the datascientist recruitment process. Nate Rosidi is a datascientist and in product strategy.
Data from external sources: Web scraping, Google Sheets, Excel, and SQLite databases. Learn Python Platform: Kaggle Level: Beginner to intermediate Why Take It: Short interactive lessons with real-world data. Databases and backend integration: Interact with MySQL and MongoDB using Python.
This is a must-have bookmark for any datascientist working with Python, encompassing everything from data analysis and machine learning to web development and automation. Ideal for datascientists and engineers working with databases and complex data models.
It supports datascientists and engineers working together. mlruns This command uses an SQLite database for metadata storage and saves artifacts in the mlruns directory. It manages the entire machine learning lifecycle. It provides tools to simplify workflows. These tools help develop, deploy, and maintain models.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Next post => Latest Posts The Lifecycle of Feature Engineering: From Raw Data to Model-Ready Inputs 10 Python Math & Statistical Analysis One-Liners 10 GitHub Repositories for Python Projects Building End-to-End Data Pipelines: From Data Ingestion to Analysis (..)
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Latest Posts Build Your Own Simple Data Pipeline with Python and Docker 10 Surprising Things You Can Do with Python’s collections Module The Lifecycle of Feature Engineering: From Raw Data to Model-Ready Inputs 10 Python Math & Statistical Analysis (..)
His company’s tool, a relational foundation model (RFM), is a new kind of pre-trained AI that brings the “zero-shot” capabilities of large language models (LLMs) to structured databases. Expensive and time-consuming bottlenecks prevent most organizations from being truly agile with their data.
Definition and purpose of a data set The core purpose of a data set is to provide a clear, organized method for storing data that can be easily accessed and analyzed. For example, a sales data set can reveal trends in customer purchases over time, informing marketing strategies.
API, Database, Campaign, Analytics, Frontend, Testing, Outreach, CRM] # Conclusion These Python one-liners show how useful Python is for JSON data manipulation. This one-liner extracts and combines elements from nested lists, creating a single flat structure thats easier to work with in subsequent operations.
From Moneyball’s transformative impact on baseball to real-time player tracking in basketball and football, data-driven decision-making is redefining how games are played, coached, and consumed. Sports data offers several benefits for learning and experimentation. It’s relatable — many datascientists are already passionate fans.
Cloud-based implementations The adoption of cloud storage solutions is becoming increasingly common for data lakes. Furthermore, NoSQL databases serve as effective platforms for implementing data lakes, allowing for rapid ingestion and retrieval of diverse data types.
Step 5: Initialize the Database Run the following commands to set up the database: chmod +x start-database.sh./start-database.sh The Postgres database will start in a container at localhost:5432. Python for Modern Data Workflows: Need Help Deciding? You will see the following message at the server side. start-database.sh
Context Manager Pattern for Resource Management When working with resources like files, database connections, or network sockets, you need to ensure they’re properly opened and closed, even if an error occurs. Example: Suppose you’re fetching user data from a database and want to provide context when a database error occurs.
You can also use a backend database such as SQLite or PostgreSQL to store its state. For data privacy, you are responsible for your own privacy as a user deploying LiteLLM yourself, but this approach is more secure since the data never leaves your controlled environment except when sent to the LLM providers.
Organizations manage extensive structured data in databases and data warehouses. Large language models (LLMs) have transformed natural language processing (NLP), yet converting conversational queries into structured data analysis remains complex. This setup uses automatic mounting of the Data Catalog in Amazon Redshift.
Data engineers are the unsung heroes of the data-driven world, laying the essential groundwork that allows organizations to leverage their data for enhanced decision-making and strategic insights. Their role has grown increasingly critical as businesses rely on large volumes of data to inform their operations and strategies.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Latest Posts 10 Surprising Things You Can Do with Python’s collections Module The Lifecycle of Feature Engineering: From Raw Data to Model-Ready Inputs 10 Python Math & Statistical Analysis One-Liners 10 GitHub Repositories for Python Projects Building (..)
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Data Sources and Collection Everything in data science begins with data.
But as data scales, the benefits become more noticeable, especially in memory-bound or performance-critical applications. Nate Rosidi is a datascientist and in product strategy. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.
Whether you’re a datascientist, AI engineer, or business leader, understanding these protocols is essential for building the next generation of intelligent systems. What Are Agentic AI Communication Protocols?
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Latest Posts The Lifecycle of Feature Engineering: From Raw Data to Model-Ready Inputs 10 Python Math & Statistical Analysis One-Liners 10 GitHub Repositories for Python Projects Building End-to-End Data Pipelines: From Data Ingestion to Analysis Bootstrapping (..)
MCP servers are lightweight programs or APIs that expose real-world tools like databases, file systems, or web services to AI models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. So, what exactly is an MCP server and client?
Its sales analysts face a daily challenge: they need to make data-driven decisions but are overwhelmed by the volume of available information. They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels.
If your database administrator has the utmost confidence in the data engineer and vice versa due to their continuous professional growth, then team members will be apt to interact and work more closely together. Who is responsible for data analyzing? Which team member oversees data warehousing?
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying. Not anymore!
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, datascientists, and stakeholders. Chris Pecora is a Generative AI DataScientist at Amazon Web Services.
It allows datascientists and machine learning engineers to interact with their data and models and to visualize and share their work with others with just a few clicks. SageMaker Canvas has also integrated with Data Wrangler , which helps with creating data flows and preparing and analyzing your data.
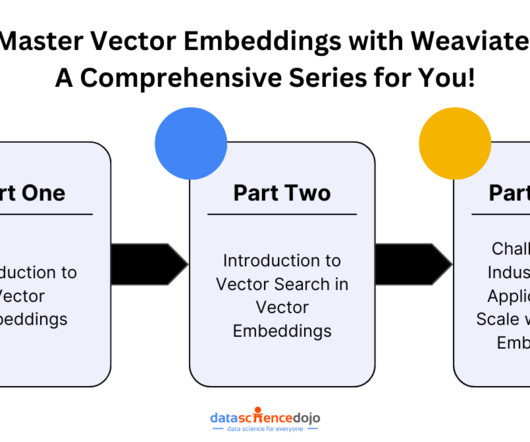
To get you started, Data Science Dojo and Weaviate have teamed up to bring you an exciting webinar series: Master Vector Embeddings with Weaviate. We have carefully curated the series to empower AI enthusiasts, datascientists, and industry professionals with a deep understanding of vector embeddings.
It requires building pipelines that bring in context from user history, prior interactions, tool calls, and internal databases — all in a format that’s easily digestible by a Transformer-based system. Context engineering doesn’t just mean “adding more stuff” to your prompt. billion across its Mumbai and Hyderabad regions, contributing $23.3
The interface provides transparent, citation-backed answers, “every answer is backed by verifiable citations from our comprehensive database” so you can trust the information. Other tools include customizable dashboards to track topics, and a “Reference Check” feature to optimize your own manuscript’s bibliography.
Defining Cloud Computing in Data Science Cloud computing provides on-demand access to computing resources such as servers, storage, databases, and software over the Internet. For Data Science, it means deploying Analytics , Machine Learning , and Big Data solutions on cloud platforms without requiring extensive physical infrastructure.
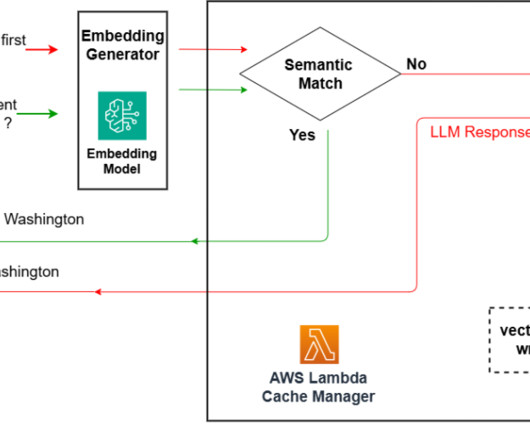
A semantic cache system operates at its core as a database storing numerical vector embeddings of text queries. With OpenSearch Serverless, you can establish a vector database suitable for setting up a robust cache system. The new generation is then sent to the client and used to update the vector database.
Because it’s modular, you can easily extend it, maybe add a search bar using Streamlit, store chunks in a vector database like FAISS for smarter lookups, or even plug this into a chatbot. Examples of Articles Conclusion In this guide, you’ve learned how to build a flexible and powerful PDF processing pipeline using only open-source tools.
Customers are looking for success stories about how best to adopt the culture and new operational solutions to support their datascientists. Datadog is a monitoring service for cloud-scale applications, bringing together data from servers, databases, tools and services to present a unified view of your entire stack.
By providing an integrated environment for data preparation, machine learning, and collaborative analytics, Dataiku empowers teams to harness the full potential of their data without requiring extensive technical expertise. The platform allows datascientists, analysts, and business stakeholders to work together seamlessly.
This is where the concept of a data lake comes in. In this comprehensive blog, we will explore what a data lake is , its core components, how it compares to other data storage solutions like data warehouses and databases, its value, challenges, and deployment in the cloud. Why Do You Need a Data Lake?
Multimodal Retrieval Augmented Generation (MM-RAG) is emerging as a powerful evolution of traditional RAG systems, addressing limitations and expanding capabilities across diverse data types. Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content