This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Kanwal Mehreen , KDnuggets Technical Editor & Content Specialist on July 4, 2025 in MachineLearning Image by Author | Canva If you like building machinelearning models and experimenting with new stuff, that’s really cool — but to be honest, it only becomes useful to others once you make it available to them.
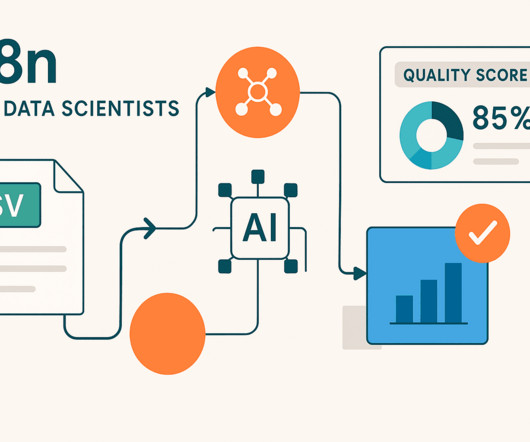
Whats the overall dataquality score? Most data scientists spend 15-30 minutes manually exploring each new dataset—loading it into pandas, running.info() ,describe() , and.isnull().sum() sum() , then creating visualizations to understand missing data patterns. Perfect for on-demand dataquality checks.
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
Instead of writing the same cleaning code repeatedly, a well-designed pipeline saves time and ensures consistency across your data science projects. In this article, well build a reusable data cleaning and validation pipeline that handles common dataquality issues while providing detailed feedback about what was fixed.
Born in India and raised in Japan, Vinod brings a global perspective to data science and machinelearning education. Vinod focuses on creating accessible learning pathways for complex topics like agentic AI, performance optimization, and AI engineering.
This one-liner computes all three key statistics in a single expression, providing a comprehensive overview of your datas central characteristics. Find Outliers Using Interquartile Range Identifying outliers is necessary for dataquality assessment and anomaly detection. times the IQR from the quartile boundaries.
By Abid Ali Awan , KDnuggets Assistant Editor on July 1, 2025 in Data Science Image by Author | Canva Awesome lists are some of the most popular repositories on GitHub, often attracting thousands of stars from the community. It is ideal for data science projects, machinelearning experiments, and anyone who wants to work with real-world data.
Overfitting in machinelearning is a common challenge that can significantly impact a model’s performance. It occurs when a model becomes too tailored to the training data, resulting in its inability to generalize effectively to new, unseen datasets. What is overfitting in machinelearning?
During this phase, the pipeline identifies and pulls relevant data while maintaining connections to disparate systems that may operate on different schedules and formats. Next the transform phase represents the core processing stage, where extracted data undergoes cleaning, validation, and restructuring.
Its key goals are to ensure dataquality, consistency, and usability and align data with analytical models or reporting needs. This involves cleaning, standardizing, merging datasets, and applying business logic.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models MachineLearning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
By Jayita Gulati on July 16, 2025 in MachineLearning Image by Editor In data science and machinelearning, raw data is rarely suitable for direct consumption by algorithms. Data audit : Identify variable types (e.g., sum, difference, ratio, product) on existing variables.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models MachineLearning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Fun Python Projects for Absolute Beginners Bored of theory?
When you understand distributions, you can spot dataquality issues instantly. What youll learn: Start with descriptive statistics. You can start with clean data from sources like seaborns built-in datasets, then graduate to messier real-world data. Why its essential: Your data is in matrices.
However, the rapid explosion of data in terms of volume, speed, and diversity has brought about significant challenges in keeping that data reliable and high-quality.
Summary: Adaptive MachineLearning is a cutting-edge technology that allows systems to learn and adapt in real-time by processing new data continuously. This capability is particularly important in today’s fast-paced environments, where data changes rapidly and requires systems that can learn and adapt in real time.
Noisy data can create significant obstacles in the realms of data analysis and machinelearning. Understanding the complexities of noisy data is essential for improving dataquality and enhancing the outcomes of predictive algorithms. What is noisy data?
Summary: MachineLearning’s key features include automation, which reduces human involvement, and scalability, which handles massive data. It uses predictive modelling to forecast future events and adaptiveness to improve with new data, plus generalization to analyse fresh data. What is MachineLearning?
Over time, the relevance of GIGO has evolved, finding application not just in computing but also in data science, machinelearning, and even social sciences. As data became more integral to operations in various sectors, understanding GIGO has become increasingly essential.
By Iván Palomares Carrascosa , KDnuggets Technical Content Specialist on July 4, 2025 in Python Image by Author | Ideogram Principal component analysis (PCA) is one of the most popular techniques for reducing the dimensionality of high-dimensional data. He trains and guides others in harnessing AI in the real world.
Data preparation for LLM fine-tuning Proper data preparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes. Importance of qualitydata in fine-tuning Dataquality is paramount in the fine-tuning process.
These enhancements allow for faster querying and analysis, often utilizing machinelearning (ML) algorithms and visualization tools. Usage by organizations Organizations across various sectors leverage data lakes to enhance their data capabilities.
Neuron is the SDK used to run deep learning workloads on Trainium and Inferentia based instances. This data makes sure models are being trained smoothly and reliably. If failures increase, it may signal issues with dataquality, model configurations, or resource limitations that need to be addressed.
Data mining Data mining techniques identify trends and patterns in vast data collections, helping organizations uncover hidden opportunities. Retail analytics In retail, analytics forecast consumer behavior, optimizing inventory and sales strategies based on data-driven insights.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. But what if we could predict a student’s engagement level before they begin?
It combines the cost-effectiveness and flexibility of data lakes with the performance and reliability of data warehouses. This hybrid approach facilitates advanced analytics, machinelearning, and business intelligence, streamlining data processing and insights generation.
Role of data governance Data governance is crucial for fostering an environment where data usage is responsible and compliant with regulations. Governance policies establish standards for dataquality, ensuring that analytics outcomes are reliable and actionable.
Augmented analytics is revolutionizing how organizations interact with their data. By harnessing the power of machinelearning (ML) and natural language processing (NLP), businesses can streamline their data analysis processes and make more informed decisions.
SageMaker JumpStart is a machinelearning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
Data versioning is a fascinating concept that plays a crucial role in modern data management, especially in machinelearning. As datasets evolve through various modifications, the ability to track changes ensures that data scientists can maintain accuracy and integrity in their projects. What is data versioning?
This approach recognizes that even the most sophisticated models are only as good as the data they are trained on. As industries increasingly rely on AI for decision-making, understanding the significance of dataquality becomes critical for success. What is data-centric AI? Reduces errors related to data inconsistencies.
Cost efficiency Organizations can achieve cost efficiency through the shift toward real-time data streaming. Dataquality and governance Domain-specific ownership leads to enhanced dataquality since those closest to the data are responsible for maintaining it.
You’ll discover how skills like data handling and machinelearning form the backbone of AI innovation, while communication and collaboration ensure your ideas make an impact beyond the technical realm. Key languages include: Python: Known for its simplicity and versatility, Python is the most widely used language in AI.
The paper identifies three key considerations for evaluating AI-enabled decision support systems (AI-DSS): scope, dataquality, and human-machine interaction. Rudners technical expertise in robustness and transparency of machinelearning systems provides a foundation for the policy recommendations in the brief.
Artificial Intelligence (AI) stands at the forefront of transforming data governance strategies, offering innovative solutions that enhance data integrity and security. In this post, let’s understand the growing role of AI in data governance, making it more dynamic, efficient, and secure. You can connect with him on LinkedIn.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machinelearning (ML) or generative AI. About the Authors Isaac Cameron is Lead Solutions Architect at Tecton, guiding customers in designing and deploying real-time machinelearning applications.
Their applications include dimensionality reduction, feature learning, noise reduction, and generative modelling. Autoencoders enhance performance in downstream tasks and provide robustness against overfitting, making them versatile tools in MachineLearning. They help improve dataquality by filtering out noise.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machinelearning (ML) models across your AWS accounts. Siamak Nariman is a Senior Product Manager at AWS. Madhubalasri B.
Training-serving skew is a significant concern in the machinelearning domain, affecting the reliability of models in practical applications. Understanding how discrepancies between training data and operational data can impact model performance is essential for developing robust systems. What is training-serving skew?
Define AI-driven Practices AI-driven practices are centred on processing data, identifying trends and patterns, making forecasts, and, most importantly, requiring minimum human intervention. Data forms the backbone of AI systems, feeding into the core input for machinelearning algorithms to generate their predictions and insights.
De-duplication has always been essential to maintaining the quality of WorldCat by enhancing cataloging efficiency and streamlining quality. At OCLC, we’ve invested resources into a hybrid approach, leveraging AI to process vast amounts of data while ensuring catalogers and OCLC experts remain at the center of decision-making.
The SageMaker Jumpstart machinelearning hub offers a suite of tools for building, training, and deploying machinelearning models at scale. When combined with Snorkel Flow, it becomes a powerful enabler for enterprises seeking to harness the full potential of their proprietary data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content