This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, the success of any data project hinges on a critical, often overlooked phase: gathering requirements. Conversely, clear, well-documented requirements set the foundation for a project that meets objectives, aligns with stakeholder expectations, and delivers measurable value. Key questions to ask: What data sources are required?
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
It possesses a suite of features that streamline data tasks and amplify the performance of LLMs for a variety of applications, including: Data Connectors: Data connectors simplify the integration of data from various sources to the data repository, bypassing manual and error-prone extraction, transformation, and loading (ETL) processes.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
Follow five essential steps for success in making your data AI ready with data integration. Define clear goals, assess your data landscape, choose the right tools, ensure dataquality and governance, and continuously optimize your integration processes.
Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models. Author(s): Richie Bachala Originally published on Towards AI.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue DataQuality , Amazon Redshift ML , and Amazon QuickSight. To learn more, see the documentation. To learn more, see the documentation.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
The storage and processing of data through a cloud-based system of applications. Master data management. The techniques for managing organisational data in a standardised approach that minimises inefficiency. Extraction, Transform, Load (ETL). Data transformation. Microsoft Azure.
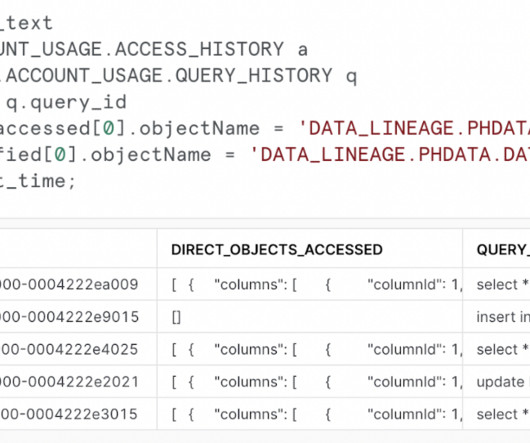
Data lineage plays a crucial role in providing transparency, ensuring data integrity, and enabling informed decision-making. While traditional methods of tracking data lineage often involve manual documentation and complex processes, the Snowflake Data Cloud offers a powerful and streamlined solution.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets. Complexity limits accessibility and value creation.
It is widely used for storing and managing structured data, making it an essential tool for data engineers. MongoDB MongoDB is a NoSQL database that stores data in flexible, JSON-like documents. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data.
Document Hierarchy Structures Maintain thorough documentation of hierarchy designs, including definitions, relationships, and data sources. This documentation is invaluable for future reference and modifications. DataQuality Issues Inconsistent or incomplete data can hinder the effectiveness of hierarchies.
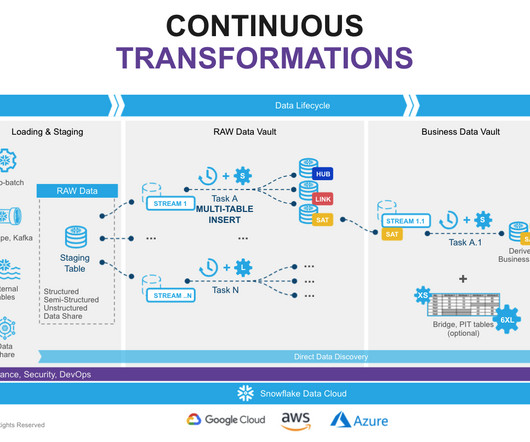
Implement business rules and validations: Data Vault models often involve enforcing business rules and performing dataquality checks. Leverage dbt’s `test` macros within your models and add constraints to ensure data integrity between data vault entities. This is where automation tools come into play.
Additionally, it addresses common challenges and offers practical solutions to ensure that fact tables are structured for optimal dataquality and analytical performance. Introduction In today’s data-driven landscape, organisations are increasingly reliant on Data Analytics to inform decision-making and drive business strategies.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. Refer to SageMaker documentation for detailed instructions.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. If you aren’t aware already, let’s introduce the concept of ETL. Redshift, S3, and so on.
As data types and applications evolve, you might need specialized NoSQL databases to handle diverse data structures and specific application requirements. With an open data lakehouse, you can access a single copy of data wherever your data resides.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
Apache Airflow Airflow is an open-source ETL software that is very useful when paired with Snowflake. dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation.
Data can be structured (e.g., documents and images). The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions. Data Integration Once data is collected from various sources, it needs to be integrated into a cohesive format.
They sought documentation to help them locate the source of the data from the warehouse. The developers spent time looking for a tool that could scan all the SQL code and Microsoft SSIS packages because that was the ETL tool being used. Table and column lineage form an essential data foundation. It depends!
Data Preprocessing Here, you can process the unstructured data into a format that can be used for the other downstream tasks. For instance, if the collected data was a text document in the form of a PDF, the data preprocessing—or preparation stage —can extract tables from this document. Unstructured.io
Using SQL-centric transformations to model data to be deployed. dbt is also great for data lineage and documentation to empower business analysts to make informed decisions on their data. Now we have one spot to check if the data is accurate. It is a compiler and a runner.
So, we must understand the different unstructured data types and effectively process them to uncover hidden patterns. Textual Data Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs.
By incorporating metadata into the data model, users can easily discover, understand, and interpret the data stored in the lake. With the amounts of data involved, this can be crucial to utilizing a data lake effectively. Inaccurate or inconsistent data can undermine decision-making and erode trust in analytics.
ThoughSpot can easily connect to top cloud data platforms such as Snowflake AI Data Cloud , Oracle, SAP HANA, and Google BigQuery. In that case, ThoughtSpot also leverages ELT/ETL tools and Mode, a code-first AI-powered data solution that gives data teams everything they need to go from raw data to the modern BI stack.
DataQuality Good testing is an essential part of ensuring the integrity and reliability of data. Without testing, it is difficult to know whether the data is accurate, complete, and free of errors. Below, we will walk through some baseline tests every team could and should run to ensure dataquality.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor dataquality and availability. It truly is an all-in-one data lake solution. Where should readers go to learn more about HPCC Systems?
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. Read more here.
The single most common way to create a view in a dataset is by CREATE VIEW DDL statement and you can refer to the official documentation to explore more options. You can use stored procedures to handle complex ETL processes, make API calls, and perform data validation.
Natural Language Understanding (NLU) : NLU is a subset of NLP focused on algorithms that can interpret the meaning of a sentence or document in terms of syntax, grammar, or ontology. You may think that AI is only for tech giants with massive budgets, colossal data sets, and a collection of proprietary technology.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. You have the function docstring because with procedural code generally in script form, there is no place to stick documentation naturally.
They offer a range of features and integrations, so the choice depends on factors like the complexity of your data pipeline, requirements for connections to other services, user interface, and compatibility with any ETL software already in use. Proper error handling enhances the resilience and reliability of your data pipeline.
Whether youre a data engineer, architect, or platform owner, this approach can help you shift from reactive firefighting to proactive, intelligent data management. The ETL Pipeline failed in PROD. Trying to Level Up Your Data Platform with Iceberg?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content