

5 essential machine learning practices every data scientist should know
Data Science Dojo
MAY 24, 2023
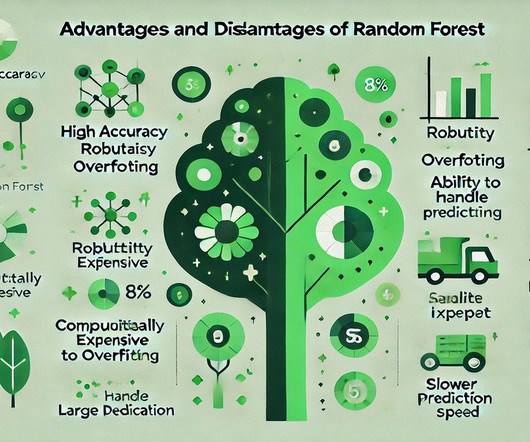
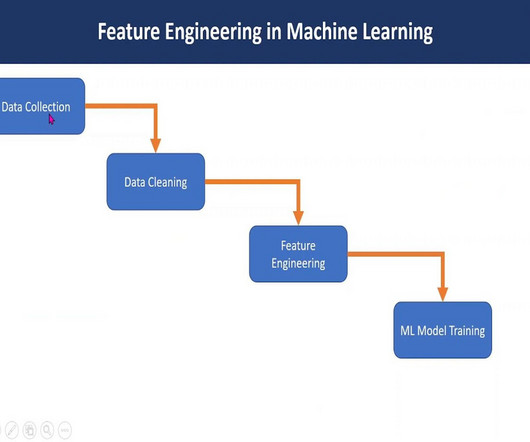
By making your models accessible, you enable a wider range of users to benefit from the predictive capabilities of machine learning, driving decision-making processes and generating valuable outcomes. They work by dividing the data into smaller and smaller groups until each group can be classified with a high degree of accuracy.






































Let's personalize your content