This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
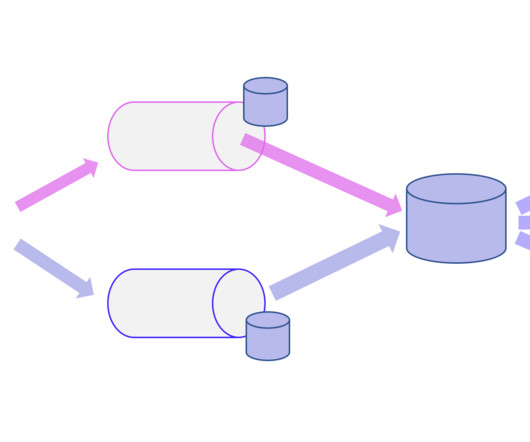
ETL pipelines are revolutionizing the way organizations manage data by transforming raw information into valuable insights. They serve as the backbone of data-driven decision-making, allowing businesses to harness the power of their data through a structured process that includes extraction, transformation, and loading.
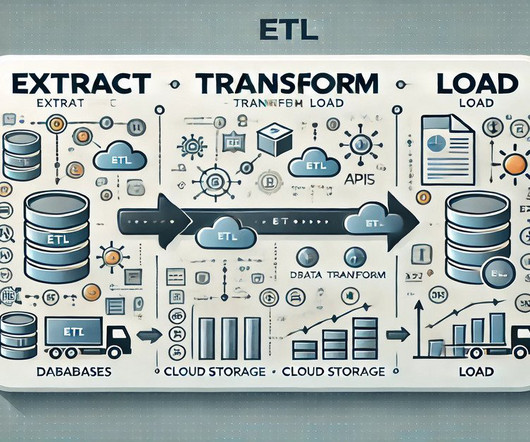
ETL (Extract, Transform, Load) is a crucial process in the world of data analytics and business intelligence. In this article, we will explore the significance of ETL and how it plays a vital role in enabling effective decision making within businesses. What is ETL? Let’s break down each step: 1.
Methods of creating data marts Let’s explain those methods. ETL processes ETL, or Extract, Transform, Load, plays a pivotal role in the creation of data marts. This process extracts data from various sources, transforms it into a desired format, and loads it into the data mart.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
By understanding how to effectively ingest data, businesses can maximize their operational efficiency and leverage analytics for informed decision-making. What is data ingestion? Data ingestion refers to the process of obtaining and importing data for immediate use or storage in a database.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
Key Takeaways Understand the fundamental concepts of data warehousing for interviews. Familiarise yourself with ETL processes and their significance. Explore popular data warehousing tools and their features. Emphasise the importance of dataquality and security measures. Can You Explain the ETL Process?
The efficiency of ETL integration can make or break the rest of your data management workflow. Want to get the most from your ETL processes? Keep reading for high-performance ETL best practices. 8 ETL best practices For optimum integration results, here’s eight of our best tips.
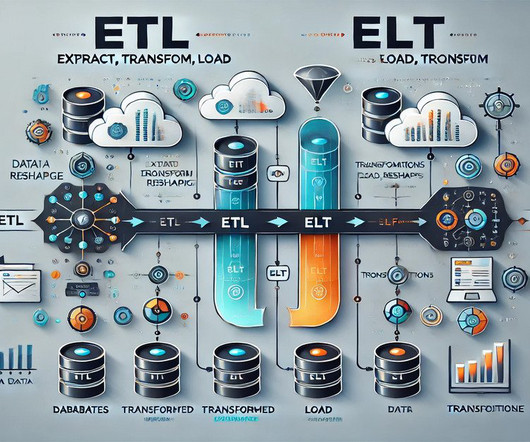
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges. Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
The magic of the data warehouse was figuring out how to get data out of these transactional systems and reorganize it in a structured way optimized for analysis and reporting. Which turned into data lakes and data lakehouses Poor dataquality turned Hadoop into a data swamp, and what sounds better than a data swamp?
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. What is ETL? ETL stands for Extract, Transform, Load.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
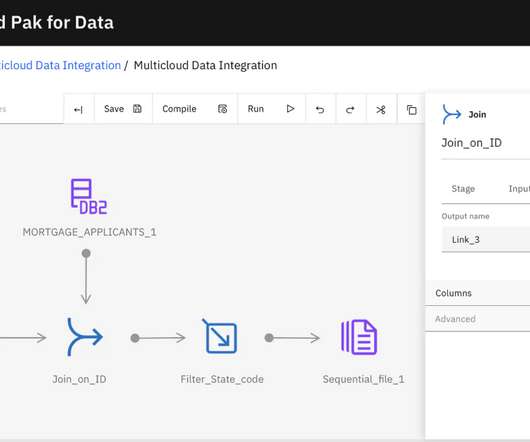
IBM Multicloud Data Integration helps organizations connect data from disparate sources, build data pipelines, remediate data issues, enrich data, and deliver integrated data to multicloud platforms where it can easily accessed by data consumers or built into a data product.
The assistant is connected to internal and external systems, with the capability to query various sources such as SQL databases, Amazon CloudWatch logs, and third-party tools to check the live system health status. To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
IBM Multicloud Data Integration helps organizations connect data from disparate sources, build data pipelines, remediate data issues, enrich data, and deliver integrated data to multicloud platforms where it can easily accessed by data consumers or built into a data product.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
Business insights are only as good as the accuracy of the data on which they are built. According to Gartner, dataquality is important to organizations in part because poor dataquality costs organizations at least $12.9 million a year on average.
The batch views within the Lambda architecture allow for the application of more complex or resource-intensive rules, resulting in superior dataquality and reduced bias over time. On the other hand, the real-time views provide immediate access to the most current data.
As a result, data silos create barriers that prevent seamless access to information across an organisation. Data silos typically arise in large enterprises where different departments operate autonomously. For instance, a sales department may maintain its own database that is incompatible with the accounting department’s system.
However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher dataquality as per business requirements. What is Data Profiling in ETL?
The storage and processing of data through a cloud-based system of applications. Master data management. The techniques for managing organisational data in a standardised approach that minimises inefficiency. Extraction, Transform, Load (ETL). Data transformation. Microsoft Azure.
In this article, we will delve into the concept of data lakes, explore their differences from data warehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. This ensures data consistency and integrity.
This can ensure that the decisions made are reliable and of high quality. Before a bank can start the process of certifying a risk model, they first need to understand what data is being used and how it changes as it moves from a database to a model.
Cloud-based business intelligence (BI): Cloud-based BI tools enable organizations to access and analyze data from cloud-based sources and on-premises databases. Understand what insights you need to gain from your data to drive business growth and strategy. Ensure that data is clean, consistent, and up-to-date.
Schema Integration Schema integration deals with reconciling data stored in different database schemas or structures. It involves mapping and transforming data elements to align with a unified schema. It requires human effort to extract data from each source and merge it.
In my first business intelligence endeavors, there were data normalization issues; in my Data Governance period, DataQuality and proactive Metadata Management were the critical points. The post The Declarative Approach in a Data Playground appeared first on DATAVERSITY. It is something so simple and so powerful.
The ability to effectively deploy AI into production rests upon the strength of an organization’s data strategy because AI is only as strong as the data that underpins it. This strategy helps organizations optimize data usage, expand into new markets, and increase revenue.
Without data engineering , companies would struggle to analyse information and make informed decisions. What Does a Data Engineer Do? A data engineer creates and manages the pipelines that transfer data from different sources to databases or cloud storage. How is Data Engineering Different from Data Science?
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes.
Summary: A data warehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, data warehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
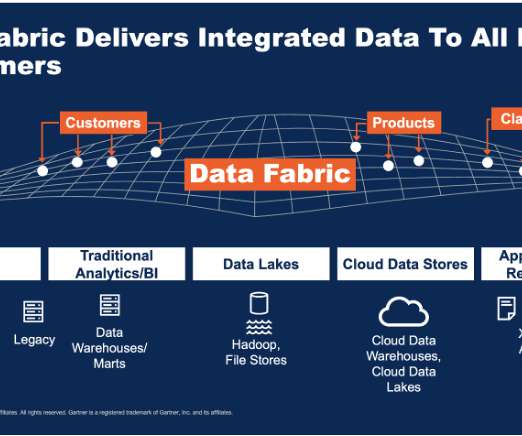
Modernizing your data infrastructure to hybrid cloud for applications, analytics and gen AI Adopting multicloud and hybrid strategies is becoming mandatory, requiring databases that support flexible deployments across the hybrid cloud. This ensures you have a data foundation that grows with your data needs, wherever your data resides.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. Files: Data stored in flat files, CSVs, or Excel sheets.
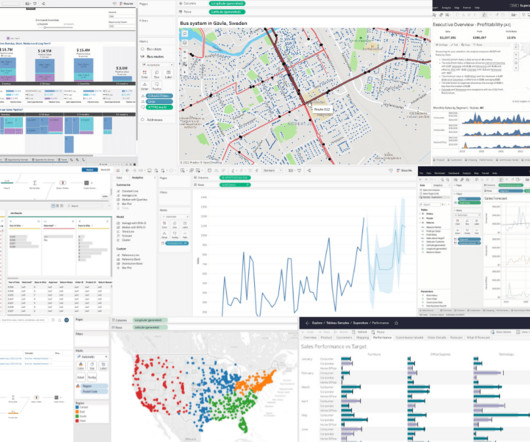
Catalog Enhanced data trust, visibility, and discoverability Tableau Catalog automatically catalogs all your data assets and sources into one central list and provides metadata in context for fast data discovery. Included with Data Management. database tables and columns). table or workbook).
What Is Data Lake? A Data Lake is a centralized repository that allows businesses to store vast volumes of structured and unstructured data at any scale. Unlike traditional databases, Data Lakes enable storage without the need for a predefined schema, making them highly flexible.
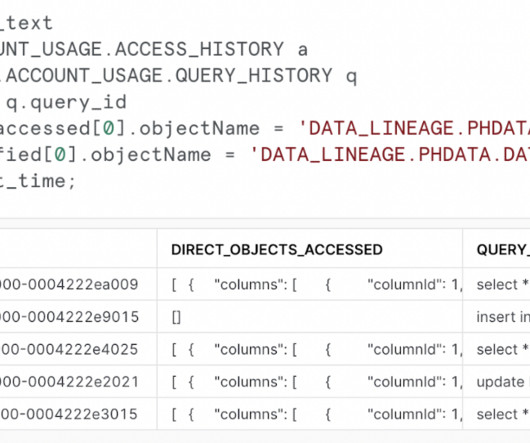
Data lineage is essential for several reasons: Data Governance – Data lineage enables organizations to track data usage, ensure compliance with regulations, and understand the impact of data changes. The ACCESS_HISTORY view is created within the SNOWFLAKE database in the ACCOUNT_USAGE schema.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content