This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
When needed, the system can access an ODAP datawarehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. The central concept is the idea of a document.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue DataQuality , Amazon Redshift ML , and Amazon QuickSight. To learn more, see the documentation. To learn more, see the documentation.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
“Quality over Quantity” is a phrase we hear regularly in life, but when it comes to the world of data, we often fail to adhere to this rule. DataQuality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation. Microsoft Azure.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
It is widely used for storing and managing structured data, making it an essential tool for data engineers. MongoDB MongoDB is a NoSQL database that stores data in flexible, JSON-like documents. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data.
“File-based storage of data is the norm even under more relational models. [In In the cloud], Graph databases, document stores, file stores, relational stores all now exist, each addressing different challenges.” In this way, the cloud has democratized access to some of the best outputs of big data.
DataQuality Now that you’ve learned more about your data and cleaned it up, it’s time to ensure the quality of your data is up to par. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
For example, a new data scientist who is curious about which customers are most likely to be repeat buyers, might search for customer data only to discover an article documenting a previous project that answered their exact question. Modern data catalogs also facilitate dataquality checks.
Implementing Generative AI can be difficult as there are some hurdles to overcome for any business to get up and running: DataQuality You get the same quality output as the data you use for any AI system, so having accurate and unbiased data is of the utmost importance.
By incorporating metadata into the data model, users can easily discover, understand, and interpret the data stored in the lake. With the amounts of data involved, this can be crucial to utilizing a data lake effectively. Inaccurate or inconsistent data can undermine decision-making and erode trust in analytics.
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses.
Additionally, it addresses common challenges and offers practical solutions to ensure that fact tables are structured for optimal dataquality and analytical performance. Introduction In today’s data-driven landscape, organisations are increasingly reliant on Data Analytics to inform decision-making and drive business strategies.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to data modeling, making it easier to ensure dataquality and consistency across the ML pipelines.
As data types and applications evolve, you might need specialized NoSQL databases to handle diverse data structures and specific application requirements. The consequences of using poor-qualitydata are far-reaching, including erosion of customer trust, regulatory noncompliance and financial and reputational damage.
Master Data Management (MDM) and data catalog growth are accelerating because organizations must integrate more systems, comply with privacy regulations, and address dataquality concerns. What Is Master Data Management (MDM)? Data Catalog and Master Data Management. Assess DataQuality.
Precisely conducted a study that found that within enterprises, data scientists spend 80% of their time cleaning, integrating and preparing data , dealing with many formats, including documents, images, and videos. Overall placing emphasis on establishing a trusted and integrated data platform for AI.
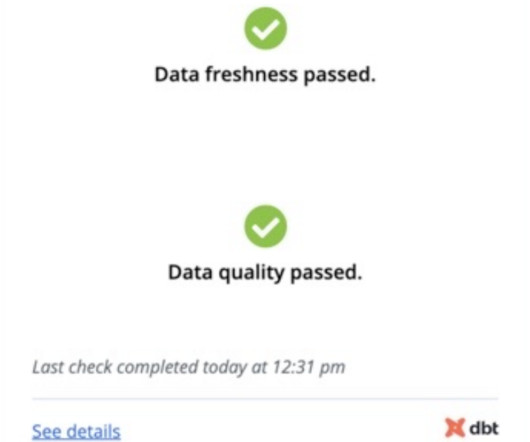
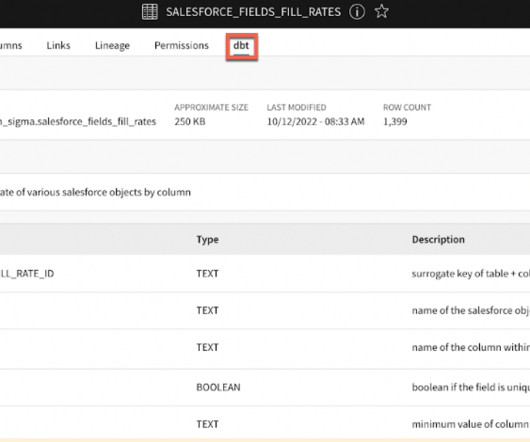
Hosted Doc Site for Documentation One of the most powerful features of dbt can be the documentation you generate. This documentation can give different users insight into where data came from, what the profile of the data is, what the SQL looked like, and the DAG to know where the data is being used.
Document Hierarchy Structures Maintain thorough documentation of hierarchy designs, including definitions, relationships, and data sources. This documentation is invaluable for future reference and modifications. DataQuality Issues Inconsistent or incomplete data can hinder the effectiveness of hierarchies.
We are now seeing a similar transformation in the world of data, where there’s tension between the old world (single-source-of-truth datawarehouses with top-down data governance) and the new world (distributed, self-service analytics with grassroots management). Dataquality can change with time.
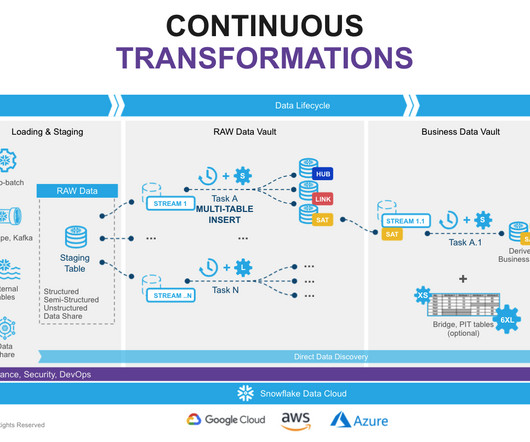
Data Vault - Data Lifecycle Architecturally, let’s understand the data lifecycle in the data vault into the following layers, which play a key role in choosing the right pattern and tools to implement. Data Acquisition: Extracting data from source systems and making it accessible.
Additional considerations Though the potential of this approach is significant, there are several challenges to consider: Dataquality High-quality, diverse input data is key to effective model performance.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital. Also Read: Top 10 Data Science tools for 2024. What is ETL?
In the next section, let’s take a deeper look into how these key attributes help data scientists and analysts make faster, more informed decisions, while supporting stewards in their quest to scale governance policies on the Data Cloud easily. Find Trusted Data. Verifying quality is time consuming. Two problems arise.
It wouldn’t be until 2013 that the topic of data lineage would surface again – this time while working on a datawarehouse project. Datawarehouses obfuscate data’s origin In 2013, I was a Business Intelligence Engineer at a financial services company. What’s the right lineage level? It depends!
To optimize data analytics and AI workloads, organizations need a data store built on an open data lakehouse architecture. This type of architecture combines the performance and usability of a datawarehouse with the flexibility and scalability of a data lake.
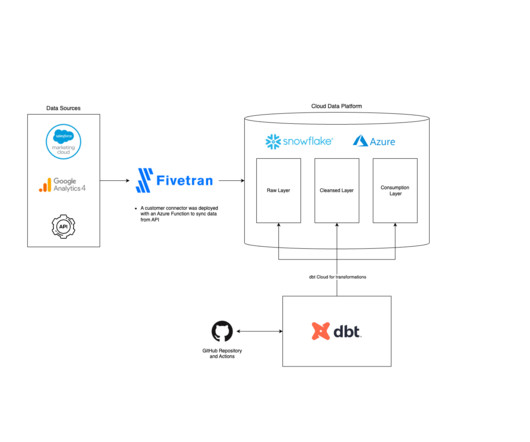
dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation. The Data Source Tool can automate scanning DDL and profiling tables between source and target, comparing them, and then reporting findings.
Fivetran includes features like data movement, transformations, robust security, and compatibility with third-party tools like DBT, Airflow, Atlan, and more. Its seamless integration with popular cloud datawarehouses like Snowflake can provide the scalability needed as your business grows.
Alation is pleased to be named a dbt Metrics Partner and to announce the start of a partnership with dbt, which will bring dbt data into the Alation data catalog. In the modern data stack, dbt is a key tool to make data ready for analysis. Purchase date represents one customer touch point.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
External Data Sources: These can be market research data, social media feeds, or third-party databases that provide additional insights. Data can be structured (e.g., documents and images). The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions.
Using SQL-centric transformations to model data to be deployed. dbt is also great for data lineage and documentation to empower business analysts to make informed decisions on their data. Data Ingestion with Fivetran Fivetran is used to move your source(s) into a centralized space for storage.
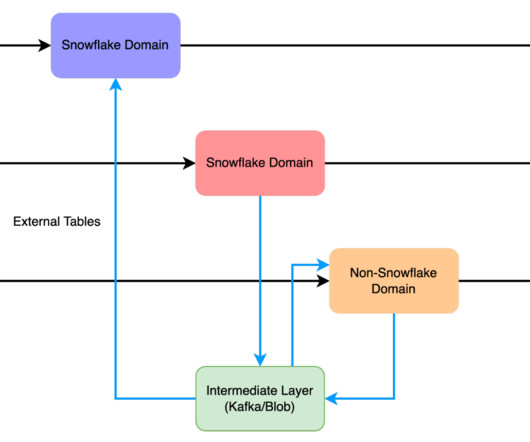
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a datawarehouse or data lake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
Important evaluation features include capabilities to preview a dataset, see all associated metadata, see user ratings, read user reviews and curator annotations, and view dataquality information. Figure 2 illustrates how analysis processes change when analysts work with a data catalog.
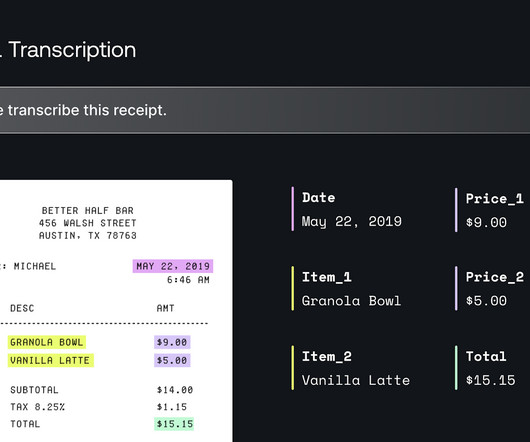
Text Data Labeling Techniques Text data labeling is a nuanced process, where success lies in finding the right balance between human expertise and automatic efficiency for each specific use case. Improve your dataquality for better AI Easily curate and annotate your vision, audio, and documentdata with a single platform.
Their tasks encompass: Data Collection and Extraction Identify relevant data sources and gather data from various internal and external systems Extract, transform, and load data into a centralized datawarehouse or analytics platform Data Cleaning and Preparation Cleanse and standardize data to ensure accuracy, consistency, and completeness.
So, we must understand the different unstructured data types and effectively process them to uncover hidden patterns. Textual Data Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content