This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
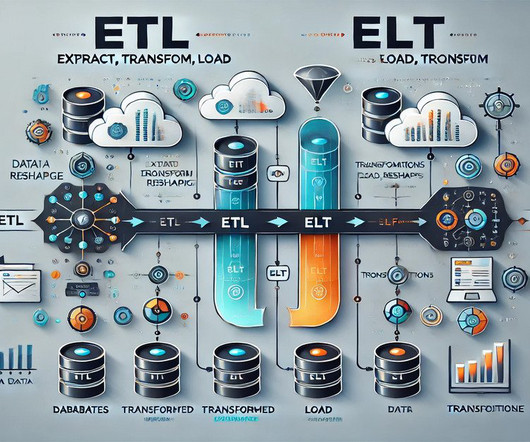
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Developing a unified roadmap for effective data management becomes essential in overcoming these obstacles. As you navigate this process, fostering collaboration between datascientists, engineers, and business leaders will prove invaluable in achieving cohesive and efficient data practices.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Follow five essential steps for success in making your data AI ready with data integration. Define clear goals, assess your data landscape, choose the right tools, ensure dataquality and governance, and continuously optimize your integration processes.
Understand what insights you need to gain from your data to drive business growth and strategy. Best practices in cloud analytics are essential to maintain dataquality, security, and compliance ( Image credit ) Data governance: Establish robust data governance practices to ensure dataquality, security, and compliance.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. Datascientists can accomplish this process by connecting through Amazon SageMaker notebooks.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. This involves working closely with data analysts and datascientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets. Complexity limits accessibility and value creation.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Their work ensures that data flows seamlessly through the organisation, making it easier for DataScientists and Analysts to access and analyse information.
Data Science focuses on analysing data to find patterns and make predictions. Data engineering, on the other hand, builds the foundation that makes this analysis possible. Without well-structured data, DataScientists cannot perform their work efficiently.
In contrast, data warehouses and relational databases adhere to the ‘Schema-on-Write’ model, where data must be structured and conform to predefined schemas before being loaded into the database. Schema Enforcement: Data warehouses use a “schema-on-write” approach.
Data preprocessing ensures the removal of incorrect, incomplete, and inaccurate data from datasets, leading to the creation of accurate and useful datasets for analysis ( Image Credit ) Data completeness One of the primary requirements for data preprocessing is ensuring that the dataset is complete, with minimal missing values.
Salam noted that organizations are offloading computational horsepower and data from on-premises infrastructure to the cloud. This provides developers, engineers, datascientists and leaders with the opportunity to more easily experiment with new data practices such as zero-ETL or technologies like AI/ML.
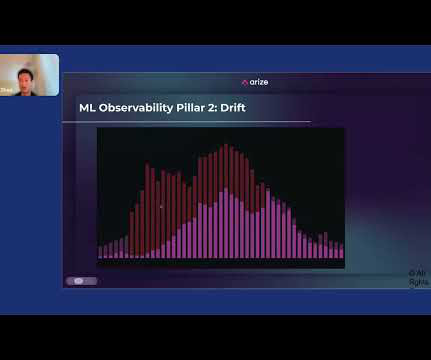
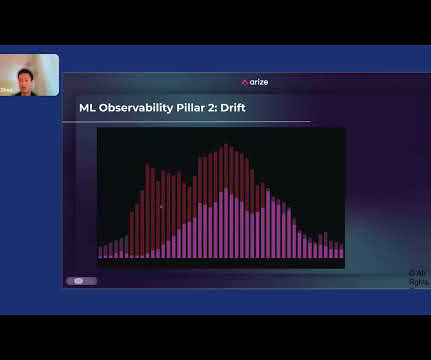
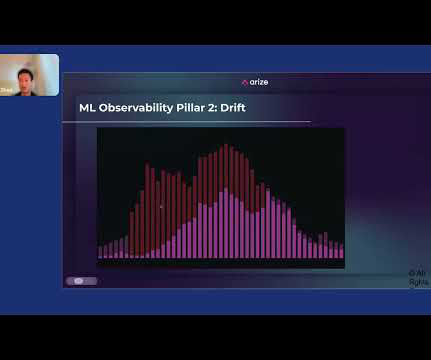
You have to make sure that your ETLs are locked down. And usually what ends up happening is that some poor datascientist or ML engineer has to manually troubleshoot this in a Jupyter Notebook. Then there’s dataquality, and then explainability. Arize AI The third pillar is dataquality.
You have to make sure that your ETLs are locked down. And usually what ends up happening is that some poor datascientist or ML engineer has to manually troubleshoot this in a Jupyter Notebook. Then there’s dataquality, and then explainability. Arize AI The third pillar is dataquality.
Collaboration : Ensuring that all teams involved in the project, including datascientists, engineers, and operations teams, are working together effectively. For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial.
Unlike traditional databases, Data Lakes enable storage without the need for a predefined schema, making them highly flexible. Importance of Data Lakes Data Lakes play a pivotal role in modern data analytics, providing a platform for DataScientists and analysts to extract valuable insights from diverse data sources.
We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. To demonstrate fine-grained data access permissions, we consider the following two users: David, a datascientist on the marketing team.
Raw DataData warehouses emerged several decades ago as a means of combining, harmonizing, and preprocessing data in preparation for advanced analytics. A data warehouse implies a certain degree of preprocessing, or at the very least, an organized and well-defined data model.
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
You have to make sure that your ETLs are locked down. And usually what ends up happening is that some poor datascientist or ML engineer has to manually troubleshoot this in a Jupyter Notebook. Then there’s dataquality, and then explainability. Arize AI The third pillar is dataquality.
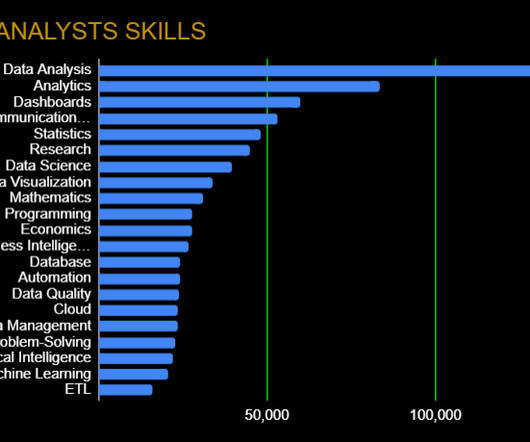
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
When done well, data democratization empowers employees with tools that let everyone work with data, not just the datascientists. When workers get their hands on the right data, it not only gives them what they need to solve problems, but also prompts them to ask, “What else can I do with data?
ThoughSpot can easily connect to top cloud data platforms such as Snowflake AI Data Cloud , Oracle, SAP HANA, and Google BigQuery. In that case, ThoughtSpot also leverages ELT/ETL tools and Mode, a code-first AI-powered data solution that gives data teams everything they need to go from raw data to the modern BI stack.
Stefan is a software engineer, datascientist, and has been doing work as an ML engineer. He also ran the data platform in his previous company and is also co-creator of open-source framework, Hamilton. To a junior datascientist, it doesn’t matter if you’re using Airflow, Prefect , Dexter.
Data Integration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis. Understanding ETL (Extract, Transform, Load) processes is vital for students. Students should learn about data wrangling and the importance of dataquality.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor dataquality and availability. It truly is an all-in-one data lake solution.
Example of Information Kept for a Simple Data Catalog Implications of Choosing the Wrong Methodology Choosing the wrong data lake methodology can have profound and lasting consequences for an organization. Inaccurate or inconsistent data can undermine decision-making and erode trust in analytics.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
And since the advent of cloud data warehouse, I was lucky enough to get a good amount of exposure on Google Cloud Platform in the early stages of the era which became my competitive edge in this wild job market. A lot of you who are already in the data science field must be familiar with BigQuery and its advantages.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. Read more here.
Here we will upskill you with the Pandas library which stands as a highly favored asset amongst datascientists, facilitating seamless data manipulation and analysis. Alongside Matplotlib, a key tool for data visualization, and NumPy, the foundational library for scientific computing upon which Pandas was constructed.
Data Science : Data science plays a crucial role in the development and application of AI, as it involves preprocessing, exploring, and transforming data to create high-quality datasets for training AI models. You don’t need massive data sets because “dataquality scales better than data size.”
If the event log is your customer’s diary, think of persistent staging as their scrapbook – a place where raw customer data is collected, organized, and kept for future reference. In traditional ETL (Extract, Transform, Load) processes in CDPs, staging areas were often temporary holding pens for data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content