This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. The post Tutorial to datapreparation for training machinelearning model appeared first on Analytics Vidhya. Introduction It happens quite often that we do not have all the.
Datapreparation is a step within the data project lifecycle where we prepare the raw data for subsequent processes, such as data analysis and machinelearning modeling.
With the most recent developments in machinelearning , this process has become more accurate, flexible, and fast: algorithms analyze vast amounts of data, glean insights from the data, and find optimal solutions. Given the enormous volume of information which can reach petabytes efficient data handling is crucial.
Feature selection methodologies go beyond filter, wrapper and embedded methods. In this article, I describe 3 alternative algorithms to select predictive features based on a feature importance score.
This article was published as a part of the Data Science Blogathon. Introduction The machinelearning process involves various stages such as, DataPreparation. The post Welcome to Pywedge – A Fast Guide to Preprocess and Build Baseline Models appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction on AutoKeras Automated MachineLearning (AutoML) is a computerised way of determining the best combination of datapreparation, model, and hyperparameters for a predictive modelling task.
ArticleVideo Book This article was published as a part of the Data Science Blogathon AGENDA: Introduction MachineLearning pipeline Problems with data Why do we. The post 4 Ways to Handle Insufficient Data In MachineLearning! appeared first on Analytics Vidhya.
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machinelearning (ML) lifecycle. The SageMaker Core SDK comes bundled as part of the SageMaker Python SDK version 2.231.0 Any version above 2.231.0
Introduction When it comes to datapreparation using Python, the term which comes to our mind is Pandas. Well, a library for prepping up the data for further analysis. No, not the one whom you see happily munching away on bamboo and lazily somersaulting.
MATLAB is a popular programming tool for a wide range of applications, such as data processing, parallel computing, automation, simulation, machinelearning, and artificial intelligence. Prerequisites Working environment of MATLAB 2023a or later with MATLAB Compiler and the Statistics and MachineLearning Toolbox on Linux. Here
These skills include programming languages such as Python and R, statistics and probability, machinelearning, data visualization, and data modeling. This includes sourcing, gathering, arranging, processing, and modeling data, as well as being able to analyze large volumes of structured or unstructured data.
Datapreparation for LLM fine-tuning Proper datapreparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes. Importance of quality data in fine-tuning Data quality is paramount in the fine-tuning process.
Introduction Data science has taken over all economic sectors in recent times. To achieve maximum efficiency, every company strives to use various data at every stage of its operations.
Machinelearning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster.
Recently, we posted the first article recapping our recent machinelearning survey. There, we talked about some of the results, such as what programming languages machinelearning practitioners use, what frameworks they use, and what areas of the field they’re interested in. As the chart shows, two major themes emerged.
The ability to quickly build and deploy machinelearning (ML) models is becoming increasingly important in today’s data-driven world. From data collection and cleaning to feature engineering, model building, tuning, and deployment, ML projects often take months for developers to complete.
Data Science is a field that encompasses various disciplines, including statistics, machinelearning, and data analysis techniques to extract valuable insights and knowledge from data. It is divided into three primary areas: datapreparation, data modeling, and data visualization.
Customers increasingly want to use deep learning approaches such as large language models (LLMs) to automate the extraction of data and insights. For many industries, data that is useful for machinelearning (ML) may contain personally identifiable information (PII).
Last Updated on June 27, 2023 by Editorial Team Source: Unsplash This piece dives into the top machinelearning developer tools being used by developers — start building! In the rapidly expanding field of artificial intelligence (AI), machinelearning tools play an instrumental role.
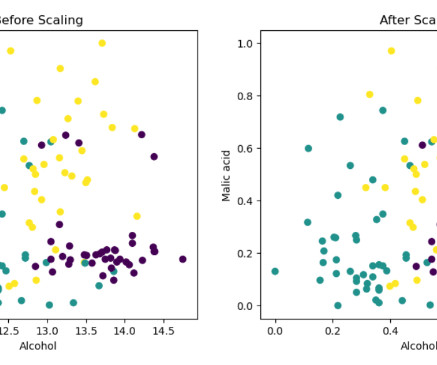
These features can be used to improve the performance of MachineLearning Algorithms. In the world of data science and machinelearning, feature transformation plays a crucial role in achieving accurate and reliable results.
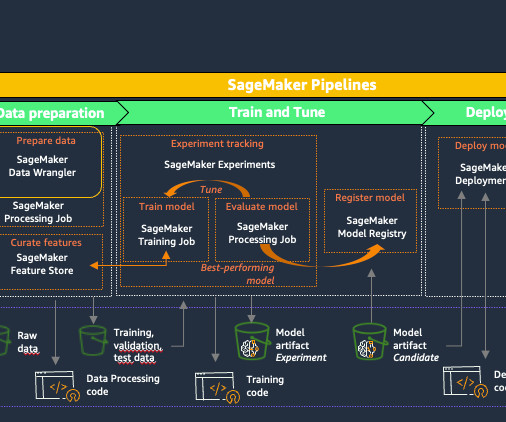
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machinelearning (ML) from weeks to minutes.
Created by the author with DALL E-3 Google Earth Engine for machinelearning has just gotten a new face lift, with all the advancement that has been going on in the world of Artificial intelligence, Google Earth Engine was not going to be left behind as it is an important tool for spatial analysis.
Top 10 AI tools for data analysis AI Tools for Data Analysis 1. TensorFlow First on the AI tool list, we have TensorFlow which is an open-source software library for numerical computation using data flow graphs. It is used for machinelearning, natural language processing, and computer vision tasks.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Deployment and Monitoring Once a model is built, it is moved to production.
With data visualization capabilities, advanced statistical analysis methods and modeling techniques, IBM SPSS Statistics enables users to pursue a comprehensive analytical journey from datapreparation and management to analysis and reporting. How to integrate SPSS Statistics with R and Python?
Fine tuning Now that your SageMaker HyperPod cluster is deployed, you can start preparing to execute your fine tuning job. Datapreparation The foundation of successful language model fine tuning lies in properly structured and prepared training data. The following is the Python code for the get_model.py
Machinelearning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed.
jpg", "prompt": "Which part of Virginia is this letter sent from", "completion": "Richmond"} SageMaker JumpStart SageMaker JumpStart is a powerful feature within the SageMaker machinelearning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs).
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machinelearning (ML) that lets you build, train, debug, deploy, and monitor your ML models.
This year, generative AI and machinelearning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services.
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation.
Photo by SHVETS production from Pexels As per the routine I follow every time, here I am with the Python implementation of Causal Impact. So let’s filter out and keep only a handful of data to perform the analysis. DataPreparation It’s time me filter out the unnecessary records to make it easier to visualize the dataset.
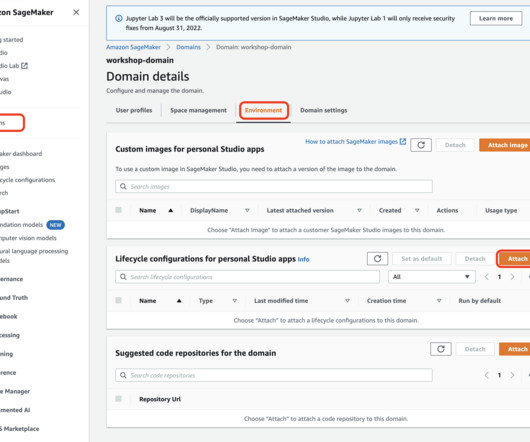
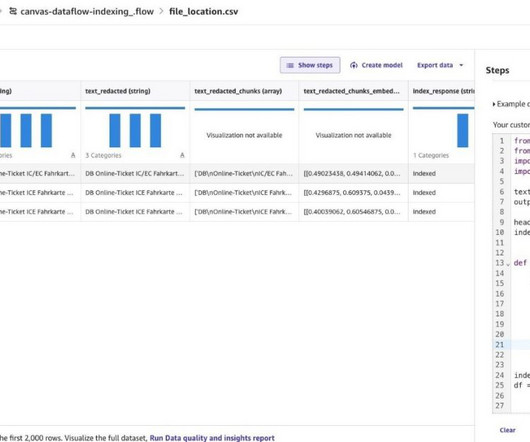
Datapreparation is important at multiple stages in Retrieval Augmented Generation ( RAG ) models. Specifically, we clean the data and create RAG artifacts to answer the questions about the content of the dataset. Choose Create on the right side of page, then give a data flow name and select Create. Choose your domain.
Summary: The UCI MachineLearning Repository, established in 1987, is a crucial resource for MachineLearning practitioners. It supports various learning tasks, including classification and regression, and is organised by type and domain, facilitating easy access for users worldwide.
Summary: The blog provides a comprehensive overview of MachineLearning Models, emphasising their significance in modern technology. It covers types of MachineLearning, key concepts, and essential steps for building effective models. The global MachineLearning market was valued at USD 35.80
Summary: Neural networks are a key technique in MachineLearning, inspired by the human brain. They consist of interconnected nodes that learn complex patterns in data. Reinforcement Learning: An agent learns to make decisions by receiving rewards or penalties based on its actions within an environment.
More than 170 tech teams used the latest cloud, machinelearning and artificial intelligence technologies to build 33 solutions. The fundamental objective is to build a manufacturer-agnostic database, leveraging generative AI’s ability to standardize sensor outputs, synchronize data, and facilitate precise corrections.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machinelearning and deep learning. Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
{This article was written without the assistance or use of AI tools, providing an authentic and insightful exploration of PyCaret} Image by Author In the rapidly evolving realm of data science, the imperative to automate machinelearning workflows has become an indispensable requisite for enterprises aiming to outpace their competitors.
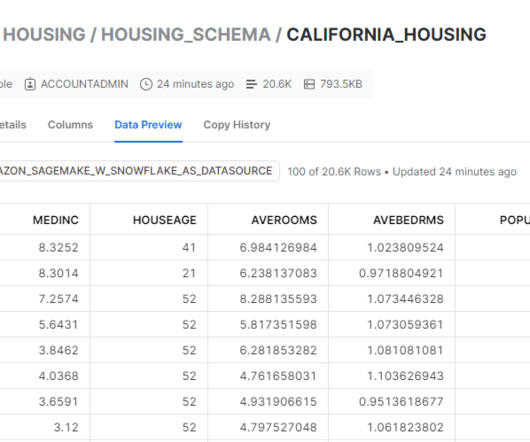
Amazon SageMaker is a fully managed machinelearning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. A Python script to connect to Secrets Manager to retrieve Snowflake credentials.
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
For readers who work in ML/AI, it’s well understood that machinelearning models prefer feature vectors of numerical information. However, the majority of enterprise data remains unleveraged from an analytics and machinelearning perspective, and much of the most valuable information remains in relational database schemas such as OLAP.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machinelearning service that simplifies the entire machinelearning workflow, from datapreparation and model training to deployment and monitoring. Python script that serves as the entry point.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content