
Implementing Approximate Nearest Neighbor Search with KD-Trees
PyImageSearch
DECEMBER 23, 2024
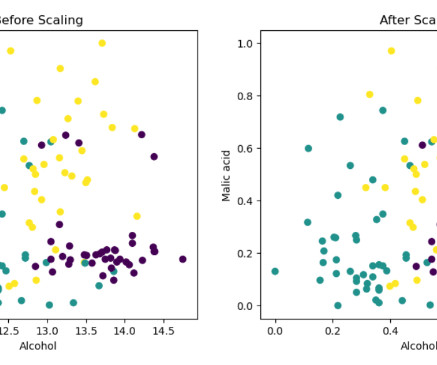
Traditional exact nearest neighbor search methods (e.g., brute-force search and k -nearest neighbor (kNN)) work by comparing each query against the whole dataset and provide us the best-case complexity of. We will start by setting up libraries and data preparation.
















Let's personalize your content