

Accelerate client success management through email classification with Hugging Face on Amazon SageMaker
AWS Machine Learning Blog
SEPTEMBER 12, 2023
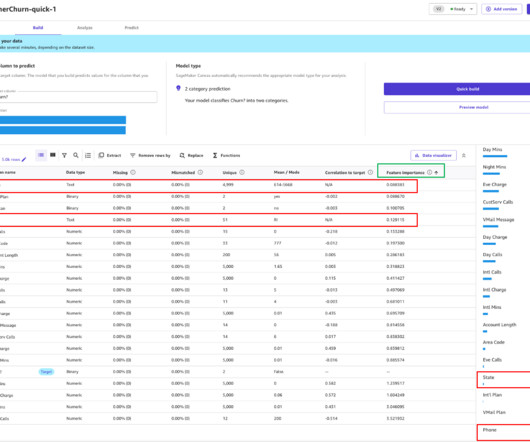
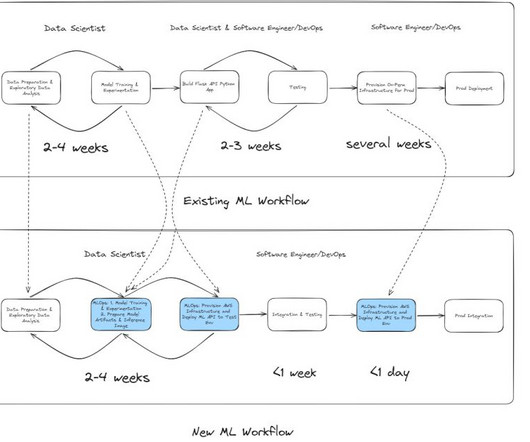
Email classification project diagram The workflow consists of the following components: Model experimentation – Data scientists use Amazon SageMaker Studio to carry out the first steps in the data science lifecycle: exploratory data analysis (EDA), data cleaning and preparation, and building prototype models.









Let's personalize your content