This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
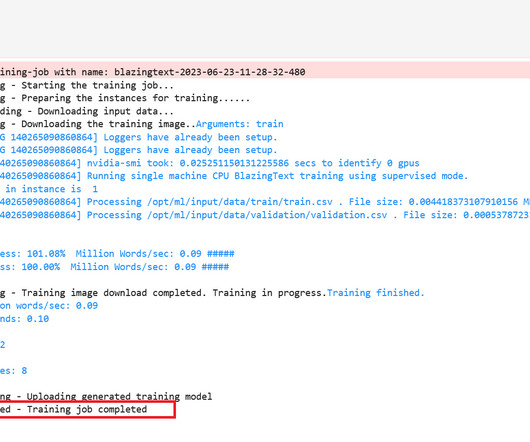
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. The SageMaker Core SDK comes bundled as part of the SageMaker Python SDK version 2.231.0 or greater is installed in the environment.
This approach is ideal for use cases requiring accuracy and up-to-date information, like providing technical product documentation or customer support. Datapreparation for LLM fine-tuning Proper datapreparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes.
Today, we’re introducing the new capability to chat with your document with zero setup in Knowledge Bases for Amazon Bedrock. With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data.
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Attendees will learn practical applications of generative AI for streamlining and automating document-centric workflows. Hear from Availity on how 1.5
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. Dataset preparation for visual question and answering tasks The Meta Llama 3.2
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. In this post, we build a Docker image that includes the Python 3.11 python3.11-pip
Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today. This includes formats like emails, PDFs, scanned documents, images, audio, video, and more.
For more information see the prompt lab documentation. The IDE connects to a Python runtime environment inside the secure scope of a project, which enables to run code in that context with access to assets available in your project. For more information see the tuning studio documentation. The watsonx.ai Use the watsonx.ai
Model cards are an essential component for registered ML models, providing a standardized way to document and communicate key model metadata, including intended use, performance, risks, and business information. The Amazon DataZone project ID is captured in the Documentation section. It’s mapped to the custom_details field.
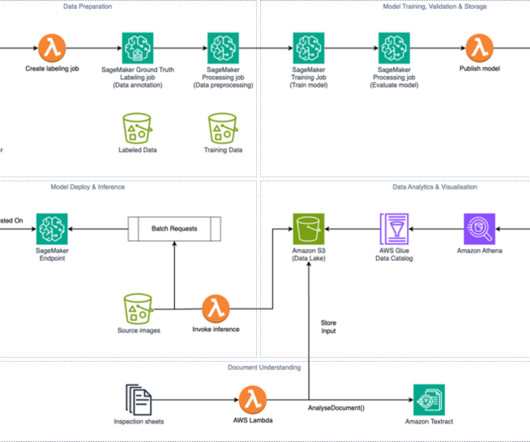
This archive, along with 765,933 varied-quality inspection photographs, some over 15 years old, presented a significant data processing challenge. Processing these images and scanned documents is not a cost- or time-efficient task for humans, and requires highly performant infrastructure that can reduce the time to value.
Additionally, these tools provide a comprehensive solution for faster workflows, enabling the following: Faster datapreparation – SageMaker Canvas has over 300 built-in transformations and the ability to use natural language that can accelerate datapreparation and making data ready for model building.
This solution supports the validation of adherence to existing obligations by analyzing governance documents and controls in place and mapping them to applicable LRRs. This approach enables centralized access and sharing while minimizing extract, transform and load (ETL) processes and data duplication. Furthermore, watsonx.ai
How to use Cloud Amplifier to: Create a new table in Snowflake and insert data Snowflake APIs in Python allow you to manipulate and integrate your data in sophisticated — and useful — ways. You can visit Snowflake’s API Documentation for more detailed examples and documentation. Very slick, if we may say so.
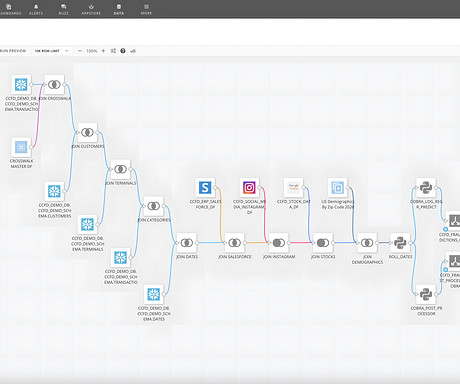
Due to various government regulations and rules, customers have to find a mechanism to handle this sensitive data with appropriate security measures to avoid regulatory fines, possible fraud, and defamation. For more details, refer to Integrating SageMaker Data Wrangler with SageMaker Pipelines.
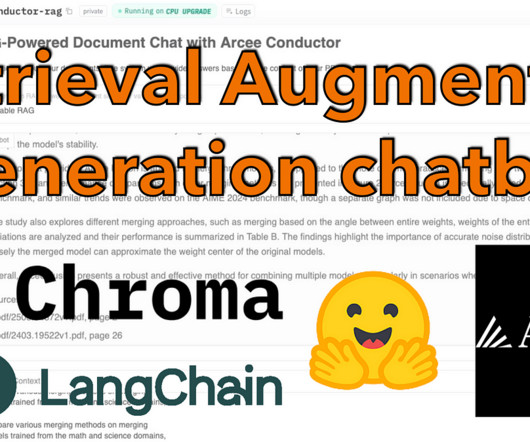
This mechanism allows the model to access and utilize context from a knowledge base, such as a collection of PDF documents. The project uses Python and several open-source libraries, including LangChain, Chroma, and Gradio. DataPreparation The first step in building the RAG chatbot is to prepare the data.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
It details the necessary setup, datapreparation requirements, the step-by-step fine-tuning workflow, methods for leveraging the resulting custom models, and illustrative examples of potential use cases. For Python development, the official mistralai library needs to be installed.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
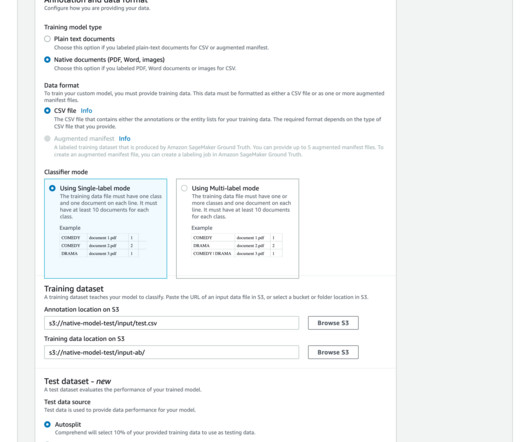
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. politics, sports) that a document belongs to.
PyTorch PyTorch is another open-source software library for numerical computation using data flow graphs. It is similar to TensorFlow, but it is designed to be more Pythonic. Scikit-learn Scikit-learn is an open-source machine learning library for Python. TensorFlow was also used by Netflix to improve its recommendation engine.
If you’re implementing complex RAG applications into your daily tasks, you may encounter common challenges with your RAG systems such as inaccurate retrieval, increasing size and complexity of documents, and overflow of context, which can significantly impact the quality and reliability of generated answers.
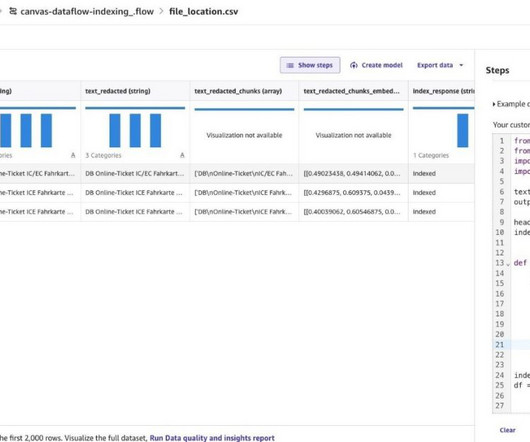
Enterprise search is a critical component of organizational efficiency through document digitization and knowledge management. Enterprise search covers storing documents such as digital files, indexing the documents for search, and providing relevant results based on user queries. Initialize DocumentStore and index documents.
I’ve also started learning and working with Tableau Public [or Power BI Desktop , Python libraries like Matplotlib/Seaborn , etc. I understand the basic functionalities of [mention tool], such as connecting to data sources, dragging and dropping dimensions and measures, applying filters, and creating different chart types.
Python = Powerful AI Research Agent By Gao Dalie () This article details building a powerful AI research agent using Pydantic AI, a web scraper (Tavily), and Llama 3.3. However, LLMs alone lack access to company-specific data, necessitating a retriever to fetch relevant information from various sources (databases, documents, etc.).
Text classification is essential for applications like web searches, information retrieval, ranking, and document classification. If you are prompted to choose a Kernel, choose the Python 3 (Data Science 3.0) Import the required Python library and set the roles and the S3 buckets. kernel and choose Select.
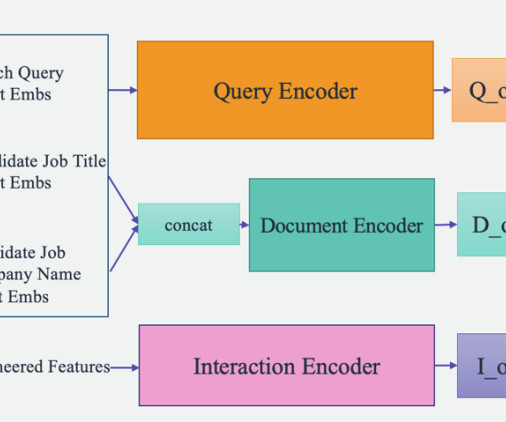
We use the standard engineered features as input into the interaction encoder and feed the SBERT derived embedding into the query encoder and document encoder. Document encoder – The document encoder processes the information of each job listing. We enhance the embeddings through an SBERT model we fine-tuned.
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. Data scientists currently use SageMaker Studio to interactively develop their Jupyter notebooks and then use SageMaker notebook jobs to run these notebooks as scheduled jobs.
Community Support and Documentation A strong community around the platform can be invaluable for troubleshooting issues, learning new techniques, and staying updated on the latest advancements. Assess the quality and comprehensiveness of the platform's documentation. It is well-suited for both research and production environments.
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
The following sections further explain the main components of the solution: ETL pipelines to transform the log data, agentic RAG implementation, and the chat application. Creating ETL pipelines to transform log dataPreparing your data to provide quality results is the first step in an AI project.
The training data used for this pipeline is made available through PrestoDB and read into Pandas through the PrestoDB Python client. The queries that are used to fetch data at training and batch inference steps are configured in the config file.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc.
It does so by covering the ML workflow end-to-end: whether you’re looking for powerful datapreparation and AutoML, managed endpoint deployment, simplified MLOps capabilities, and ready-to-use models powered by AWS AI services and Generative AI, SageMaker Canvas can help you to achieve your goals.
Datapreparation LLM developers train their models on large datasets of naturally occurring text. Popular examples of such data sources include Common Crawl and The Pile. An LLM’s eventual quality significantly depends on the selection and curation of the training data.
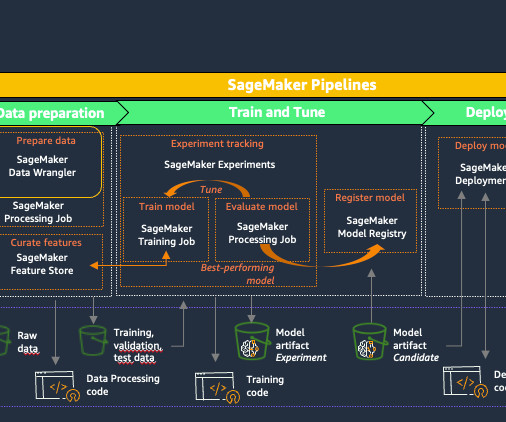
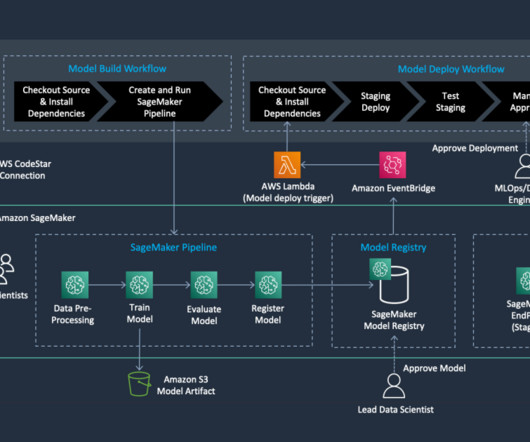
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. This ensures that your ML code base and pipelines are versioned, documented, and accessible by team members.
While both these tools are powerful on their own, their combined strength offers a comprehensive solution for data analytics. In this blog post, we will show you how to leverage KNIME’s Tableau Integration Extension and discuss the benefits of using KNIME for datapreparation before visualization in Tableau.
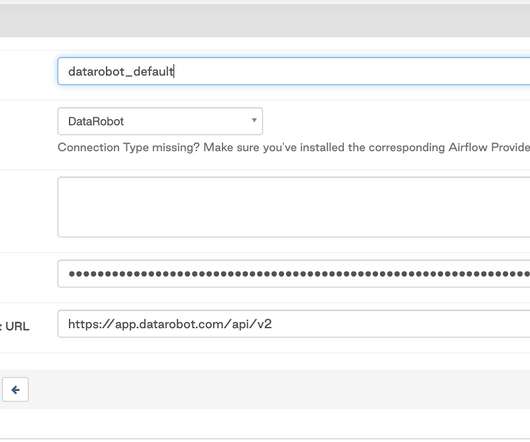
If you are new to working with DataRobot, you’re welcome to check out our documentation , where you can find the UI docs, API docs, and tutorials. The DataRobot provider for Apache Airflow is a Python package built from source code available in a public GitHub repository and published in PyPi (The Python Package Index).
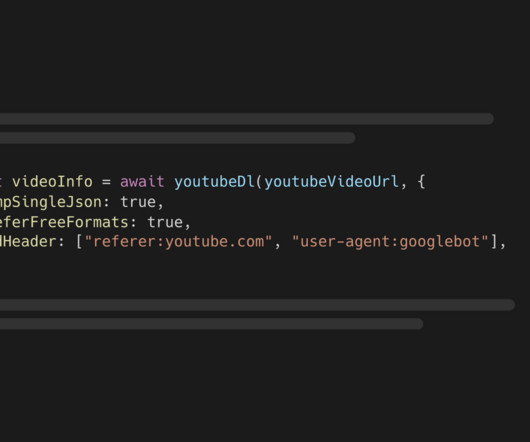
tsx lets you execute TypeScript code without additional setup npm install --save assemblyai youtube-dl-exec tsx You must also install Python 3.7 Learn Python - do a beginner and intermediate level course to get a solid base. . Learn Python - do a beginner and intermediate level course to get a solid base.
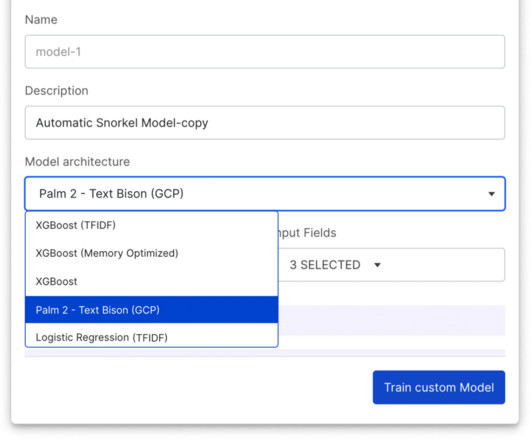
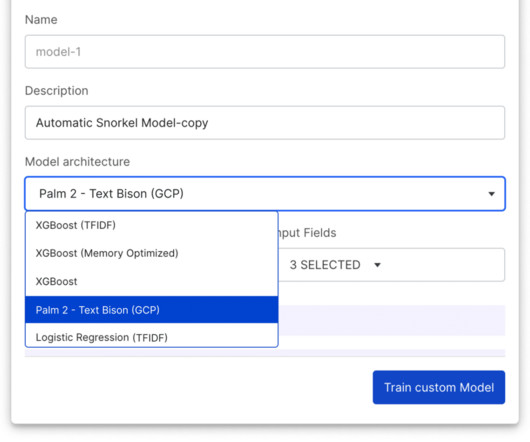
When Vertex Model Monitoring detects data drift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. Revamped Snorkel Flow SDK Also included in the 2023.R3
These procedures are designed to automate repetitive tasks, implement business logic, and perform complex data transformations , increasing the productivity and efficiency of data processing workflows. The LANGUAGE PYTHON clause indicates that the procedure is written in Python, and RUNTIME_VERSION = '3.8'
When Vertex Model Monitoring detects data drift, input feature values are submitted to Snorkel Flow, enabling ML teams to adapt labeling functions quickly, retrain the model, and then deploy the new model with Vertex AI. Revamped Snorkel Flow SDK Also included in the 2023.R3
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using natural language processing (NLP) and advanced search algorithms. With Amazon Kendra, you can find relevant answers to your questions quickly, without sifting through documents.
tsx lets you execute TypeScript code without additional setup npm install --save assemblyai youtube-dl-exec tsx You must also install Python 3.7 Learn Python - do a beginner and intermediate level course to get a solid base. . Learn Python - do a beginner and intermediate level course to get a solid base.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content