This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. The SageMaker Core SDK comes bundled as part of the SageMaker Python SDK version 2.231.0 We use the SageMaker Core SDK to execute all the steps.
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes.
Data science is an interdisciplinary field that utilizes advanced analytics techniques to extract meaningful insights from vast amounts of data. This helps facilitate data-driven decision-making for businesses, enabling them to operate more efficiently and identify new opportunities.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Deployment and Monitoring Once a model is built, it is moved to production.
An example of “Conflicting attributes in the base class” query In Python, when a class subclasses multiple base classes, attribute lookup is performed from left to right amongst the base classes following a method called “method resolution order.”¹ the definitions of the conflicting attributes in the example).
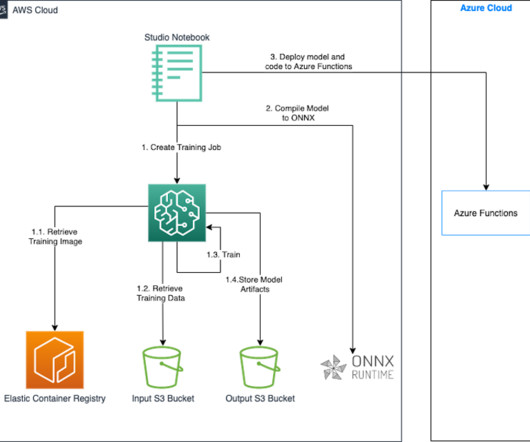
SageMaker Studio allows data scientists, ML engineers, and data engineers to preparedata, build, train, and deploy ML models on one web interface. Finally, we deploy the ONNX model along with a custom inference code written in Python to Azure Functions using the Azure CLI. image and Python 3.0
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. Ray AI Runtime (AIR) reduces friction of going from development to production.
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code.
If you are targeting roles involving data visualization , Data Analysis , or Business Intelligence , you can expect your interview to include questions specifically testing your data viz prowess. Preparing for these questions is crucial. The approach depends on the context and the amount of missing data.
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
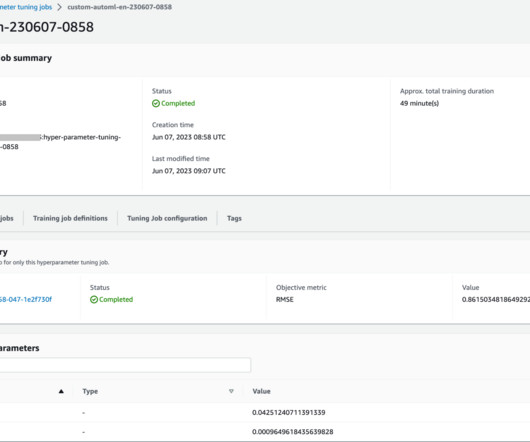
Prerequisites The following are prerequisites for completing the walkthrough in this post: An AWS account Familiarity with SageMaker concepts, such as an Estimator, training job, and HPO job Familiarity with the Amazon SageMaker Python SDK Python programming knowledge Implement the solution The full code is available in the GitHub repo.
If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select. as the image and Glue Python [PySpark and Ray] as the kernel, then choose Select. The environment preparation process may take some time to complete.
In the following sections, we break down the datapreparation, model experimentation, and model deployment steps in more detail. Datapreparation Scalable Capital uses a CRM tool for managing and storing email data. Relevant email contents consist of subject, body, and the custodian banks. Use Version 2.x
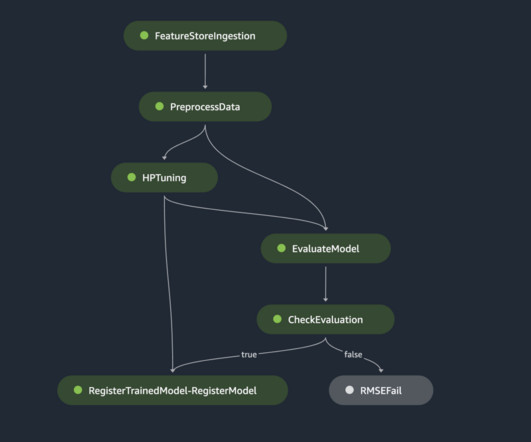
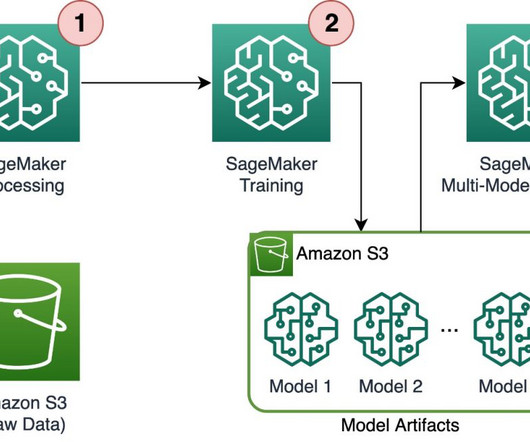
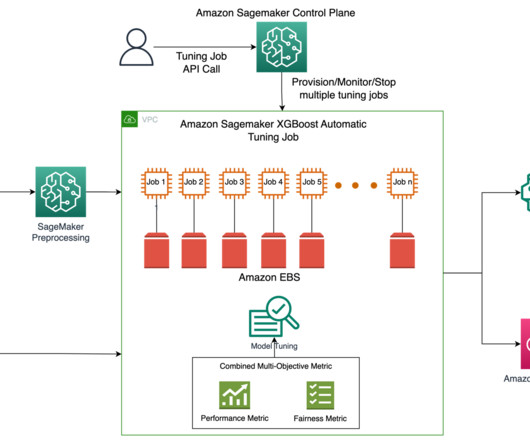
Solution overview To efficiently train and serve thousands of ML models, we can use the following SageMaker features: SageMaker Processing – SageMaker Processing is a fully managed datapreparation service that enables you to perform data processing and model evaluation tasks on your input data.
Inference code (private component) – Aside from the ML model itself, we need to implement some application logic to handle tasks like datapreparation, communication with the model for inference, and postprocessing of inference results. Built-in capabilities like retries or logging are important points to build robust orchestrations.
These procedures are designed to automate repetitive tasks, implement business logic, and perform complex data transformations , increasing the productivity and efficiency of data processing workflows. The LANGUAGE PYTHON clause indicates that the procedure is written in Python, and RUNTIME_VERSION = '3.8'
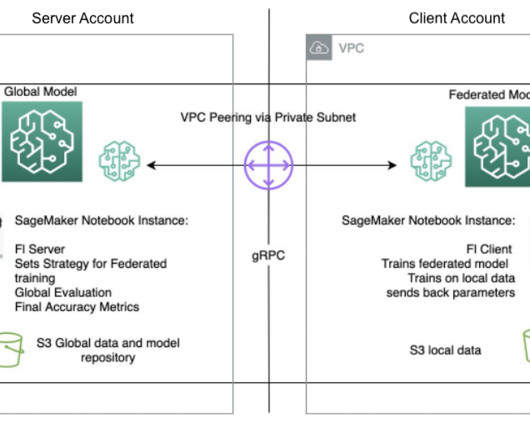
It serializes these configuration dictionaries (or config dict for short) to their ProtoBuf representation, transports them to the client using gRPC, and then deserializes them back to Python dictionaries. Data is split into a training dataset and a testing dataset. Details of the datapreparation code are in the following notebook.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as data quality, algorithm, scalability, and domain knowledge, to mention a few. You can find more details about training datapreparation and understand the custom classifier metrics.
Data Science for Business” by Foster Provost and Tom Fawcett This book bridges the gap between Data Science and business needs. It covers Data Engineering aspects like datapreparation, integration, and quality. Ideal for beginners, it illustrates how Data Engineering aligns with business applications.
A good understanding of Python and machine learning concepts is recommended to fully leverage TensorFlow's capabilities. Integration: Strong integration with Python, supporting popular libraries such as NumPy and SciPy. However, for effective use of PyTorch, familiarity with Python and machine learning principles is a must.
These statistics underscore the significant impact that Data Science and AI are having on our future, reshaping how we analyse data, make decisions, and interact with technology. Programming Skills Proficiency in programming languages like Python and R is essential for Data Science professionals.
We don’t claim this is a definitive analysis but rather a rough guide due to several factors: Job descriptions show lagging indicators of in-demand prompt engineering skills, especially when viewed over the course of 9 months. The definition of a particular job role is constantly in flux and varies from employer to employer.
This solution contains datapreparation and visualization functionality within SageMaker and allows you to train and optimize the hyperparameters of deep learning models for your dataset. You can use your own data or try the solution with a synthetic dataset as part of this solution. Choose Launch.
On the other hand, data modification refers to altering the structure or schema of a database. It involves changing the database’s structure, such as adding or deleting tables, modifying column definitions, or altering relationships between tables. Alters the original data by directly modifying its values or structure.
Amazon SageMaker Clarify can detect potential bias during datapreparation, after model training, and in your deployed model. These metrics are also openly available with the smclarify python package and github repository here. The definition of these hyperparameters and others available with SageMaker AMT can be found here.
Additionally, you will work closely with cross-functional teams, translating complex data insights into actionable recommendations that can significantly impact business strategies and drive overall success. Also Read: Explore data effortlessly with Python Libraries for (Partial) EDA: Unleashing the Power of Data Exploration.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The CUDA platform is used through complier directives and extensions to standard languages, such as the Python cuNumeric library.
The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from datapreparation to model deployment and monitoring. When you look at the end-to-end journey of an eCommerce platform, you will find there are plenty of components where data is generated.
This approach is for customers who have large troves of unlabeled, domain-specific information and want to enable their LLMs to understand the language, phrases, abbreviations, concepts, definitions, and jargon unique to their world (and business). thousands of text documents).
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. These tools help in everything from data manipulation to training complex models, and they are continuously evolving to meet the growing demands of Machine Learning applications.
Good at Go, Kubernetes (Understanding how to manage stateful services in a multi-cloud environment) We have a Python service in our Recommendation pipeline, so some ML/Data Science knowledge would be good. Data extraction and massage, delivery to destinations like Google/Meta/TikTok/etc.
algorithms: - algorithm: "FactualKnowledge" module: "fmeval.eval_algorithms.factual_knowledge" config: "FactualKnowledgeConfig" target_output_delimiter: " " Evaluation step: The new SageMaker Pipeline SDK provides users the flexibility to define custom steps in the ML workflow using the ‘@step’ Python decorator. html") s3_object = s3.Object(bucket_name=output_bucket,
Data preprocessing Text data can come from diverse sources and exist in a wide variety of formats such as PDF, HTML, JSON, and Microsoft Office documents such as Word, Excel, and PowerPoint. Its rare to already have access to text data that can be readily processed and fed into an LLM for training.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content